

Fury是一个基于JIT动态编译的多语言原生序列化框架,支持Java/Python/Golang/C++等语言,提供全自动的对象多语言/跨语言序列化能力,以及相比于别的框架最高20~200倍的性能。
引言
过去十多年大数据和分布式系统蓬勃发展,序列化是其频繁使用的技术。当对象需要跨进程、跨语言、跨节点传输、持久化、状态读写时,都需要进行序列化,其性能和易用性影响着系统的运行效率和开发效率。
对于Java序列化,尽管Kryo[1]等框架提供了相比JDK序列化数倍的性能,对于高吞吐、低延迟、大规模数据传输场景,序列化仍然是整个系统的性能瓶颈。为了优化序列化的性能,分布式系统如Spark[2]、Flink[3]使用了专有行列存二进制格式如tungsten[4]和arrow[5]。这些格式减少了序列化开销,但增加了系统的复杂性,牺牲了编程的灵活性,同时也只覆盖了SQL等关系代数计算专有场景。对于通用分布式编程和跨进程通信,序列化性能始终是一个绕不过去的关键问题。
同时随着计算和应用场景的日益复杂化,系统已经从单一语言的编程范式发展到多语言融合编程,对象在语言之间传输的易用性影响着系统开发效率,进而影响业务的迭代效率。而已有的跨语言序列化框架protobuf/flatbuffer/msgpack等由于无法支持引用、不支持Zero-Copy、大量手写代码以及生成的类不符合面向对象设计[6]无法给类添加行为,导致在易用性、灵活性、动态性和性能上的不足,并不能满足通用跨语言编程需求。
基于此,我们开发了Fury,通过一套支持引用、类型嵌入的语言无关协议,以及JIT动态编译加速、缓存优化和Zero-Copy等技术,实现了任意对象像动态语言自动序列化一样跨语言自动序列化,消除了语言之间的编程边界,并提供相比于业界别的框架最高20~200倍的性能。

Fury是什么
Fury是一个基于JIT的高性能多语言原生序列化框架,专注于提供极致的序列化性能和易用性:
支持主流编程语言如Java/Python/C++/Golang,其它语言可轻易扩展;
多语言/跨语言自动序列化任意对象,无需创建IDL文件、手动编译schema生成代码以及将对象转换为中间格式;
多语言/跨语言自动序列化共享引用和循环引用,用户只需要关心对象,不需要关心数据重复或者递归错误;
基于JIT动态编译技术在运行时自动生成序列化代码优化性能,增加方法内联、代码缓存和死代码消除,减少虚方法调用/条件分支/Hash查找/元数据写入等,提供相比其它序列化框架20~200倍以上的性能;
Zero-Copy序列化支持,支持Out of band序列化协议,支持堆外内存读写;
提供缓存友好的二进制随机访问行存格式,支持跳过序列化和部分序列化,并能和列存自动互转;
除了跨语言能力,Fury还具备以下能力:
无缝替代JDK/Kryo/Hessian等Java序列化框架,无需修改任何代码,同时提供相比Kryo 20倍以上的性能,相比Hessian100倍以上的性能,相比JDK自带序列化200倍以上的性能,可以大幅提升高性能场景RPC调用和对象持久化效率;
支持共享引用和循环引用的Golang序列化框架;
支持对象自动序列化的Golang序列化框架;
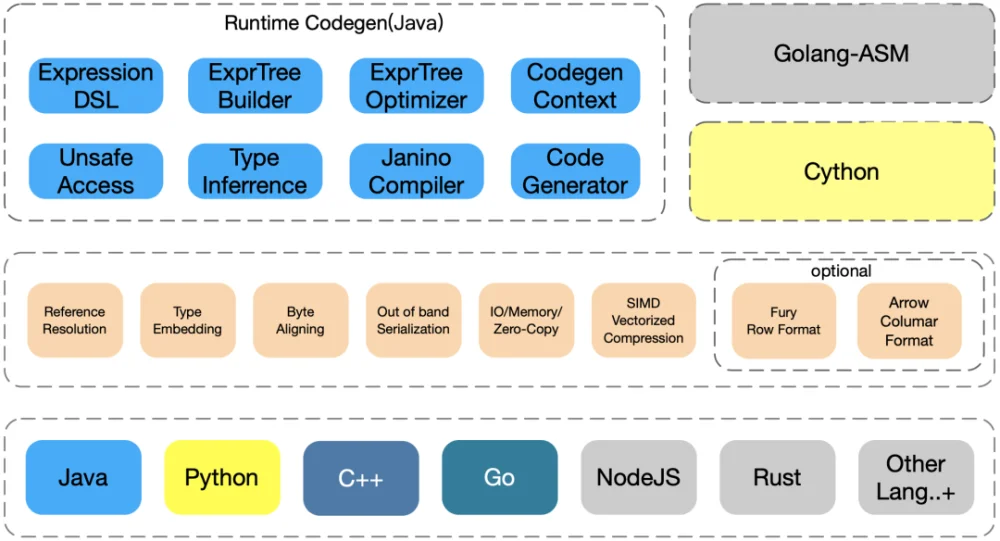
目前Fury已经支持Java、Python、Golang以及C++。本文将首先简单介绍如何使用Fury,然后将Fury跟别的序列化框架进行功能、性能和易用性比较,Fury的实现原理将在后续文章里面详细介绍。
如何使用Fury
这里给出跨语言序列化、纯Java序列化以及避免序列化的示例:
跨语言序列化自定义类型
跨语言序列化包含循环引用的自定义类型
跨语言零拷贝序列化
Drop-in替代Kryo/Hession/JDK序列化
通过Fury Format避免序列化
序列化自定义类型
下面是序列化用户自定义类型的一个示例,该类型里面包含多个基本类型以及嵌套类型的字段,在业务应用里面相当常见。需要注意自定义类型跨语言序列化之前需要调用`register`API注册自定义类型,建立类型在不同语言之间的映射关系,同时保证GoLang等静态语言编译器编译代码时不裁剪掉这部分类型的符号。
Java序列化示例
纯Java序列化:
跨语言序列化:
Python序列化示例
GoLang序列化示例
序列化共享&循环引用
共享引用和循环引用是程序里面常见的构造,很多数据结构如图都包含大量的循环引用,而手动实现这些包含共享引用和循环引用的对象,需要大量冗长复杂易出错的代码。跨语言序列化框架支持循环引用可以极大简化这些复杂场景的序列化,加速业务迭代效率。下面是一个包含循环引用的自定义类型跨语言序列化示例。
Java序列化示例
Java序列化:
跨语言序列化:
Python序列化示例
Golang序列化示例
Zero-Copy序列化
对于大规模数据传输场景,内存拷贝有时会成为整个系统的瓶颈。为此各种语言和框架做了大量优化,比如Java提供了NIO能力,避免了内存在用户态和内核态之间的来回拷贝;Kafka使用Java的NIO来实现零拷贝;Python Pickle5提供了Out-Of-Band Buffer[7]序列化能力来避免额外拷贝。
对于高性能跨语言数据传输,序列化框架也需要能够支持Zero-Copy,避免数据Buffer的额外拷贝。下面是一个Fury序列化多个基本类型数组组成的对象树的示例,分别对应到Java基本类型数组、Python Numpy数组、Golang 基本类型slice。对于ByteBuffer零拷贝,在本文的性能测试部分也给出了部分介绍。
Java序列化示例
Java序列化
跨语言序列化:
Python序列化示例
Golang序列化示例
Drop-in替换Kryo/Hession
除了多语言原生序列化以外,Fury还是一个高性能的通用Java序列化框架,可以序列化任意Java Object,完全兼容JDK序列化,包括支持序列化自定义writeObject/readObject/writeReplace/readResolve的对象,支持堆内/堆外内存。可以Drop-in替换jdk/kryo/hession等序列化框架,性能最高是Kryo 20倍以上,Hession100倍以上,JDK自带序列化200倍。
下面是一个序列化自定义类型的示例:
通过Fury Format避免序列化
对于有极致性能要求的场景,如果用户只需要读取部分数据,或者在Serving场景根据对象树某个字段进行过滤和转发,可以使用Fury Format来避免其它字段的序列化。Fury Row Format是参考SQL行存和Arrow列存实现的一套可以随机访问的二进制行存结构。目前实现了Java/Python/C++版本,Python版本通过Cython绑定到C++实现。
由于该格式是自包含的,可以根据schema直接计算出任意字段的offset。因此通过使用该格式,可以避免掉序列化,直接在二进制数据buffer上面进行所有读写操作,这样做有三个优势:
减少Java GC overhead。由于避免了反序列化,因此不会创建对象,从而避免了GC问题。
避免Python反序列化。Python性能一直很慢,因此在跨语言序列化时,可以在Java/C++侧把对象序列化成Row-Format,然后Python侧直接使用该数据计算,这样就避免了Python反序列化的昂贵开销。同时由于Python的动态性,Fury的BinaryRow/BinaryArrays实现了_getattr__/__getitem__/slice/和其它special methods,保证了行为跟python pojo/list/object的一致性,用户没有任何感知。
缓存友好,数据密集存储。
Python示例
这里给出一个读取部分数据的样例以及性能测试结果。在下面这个序列化场景中,需要读取第二个数组字段的第10万个元素,Fury耗时几乎为0,而pickler需要8秒。
Java示例
自动转换Arrow
Fury Format支持自动与Arrow列存互转。
Python示例:
C++示例:
Java示例:
对比其它序列化框架
跟其它框架的对比将分为功能、性能和易用性三个维度,每个维度上Fury都有比较显著的优势。
功能比较
这里从10个维度将Fury跟别的框架进行对比,每个维度的含义分别为:
多语言/跨语言:是否支持多种语言以及是否支持跨语言序列化
自动序列化:是否需要写大量序列化代码,还是可以完全自动话
是否需要schema编译:是否需要编写schema IDL文件,并编译schema生成代码
自定义类型:是否支持自定义类型,即POJO/DataClass/Struct等
非自定义类型:是否支持非自定义类型,即是否支持直接序列化基本类型、数组、List、Map等,还是需要将这些类型包装到自定义类型内部才能进行序列化
引用/循环引用:对于指向同一个对象的两份引用,是否只会序列化数据一次;对于循环引用,是否能够进行序列化而不是出现递归报错
多态子类型:对于List/Map的多个子类型如ArrayList/LinkedList/ImmutableList,HashMap/LinkedHashMap等,反序列化是否能够得到相同的类型,还是会变成ArrayList和HashMap
反序列化是否需要传入类型:即是否需要在反序列化时需要提前知道数据对应的类型。如果需要的话则灵活性和易用性会受到限制,而且传入的类型不正确的话反序列化可能会crash
部分反序列化/随机读写:反序列化是否可以只读取部分字段或者嵌套的部分字段,对于大对象这可以节省大量序列化开销
堆外内存读写:即是否支持直接读写native内存
数值类型可空:是否支持基本类型为null,比如Java的Integer等装箱类型以及python的int/float可能为null。

性能比较(数值越小越好)
这里给出在纯Java序列化场景对比其它框架的性能测试结果。其它语言的性能测试将在后续文章当中发布。
测试环境:
操作系统:4.9.151-015.ali3000.alios7.x86_64
CPU型号:Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz
Byte Order:Little Endian
L1d cache:32K
L1i cache:32K
L2 cache:1024K
L3 cache:33792K
测试原则:
自定义类型序列化测试数据使用的是kryo-benchmark[8]的数据,保证测试结果对Fury没有任何偏向性。尽管Kryo测试数据里面有大量基本类型数组,为了保证测试的公平性我们并没有开启Fury的Out-Of-Band零拷贝序列化能力。然后使用我们自己创建的对象单独准备了一组零拷贝测试用例。
测试工具:
为了避免JVM JIT给测试带来的影响,我们使用JMH[9]工具进行测试,每组测试在五个子进程依次进行,避免受到进程CPU调度的影响,同时每个进程里面执行三组Warmup和5组正式测试,避免受到偶然的环境波动影响。
下面是我们使用JMH测试fury/kryo/fst/hession/protostuff/jdk序列化框架在序列化到堆内存和堆外内存时的性能(数值越小越好)。
自定义类型性能对比
Struct
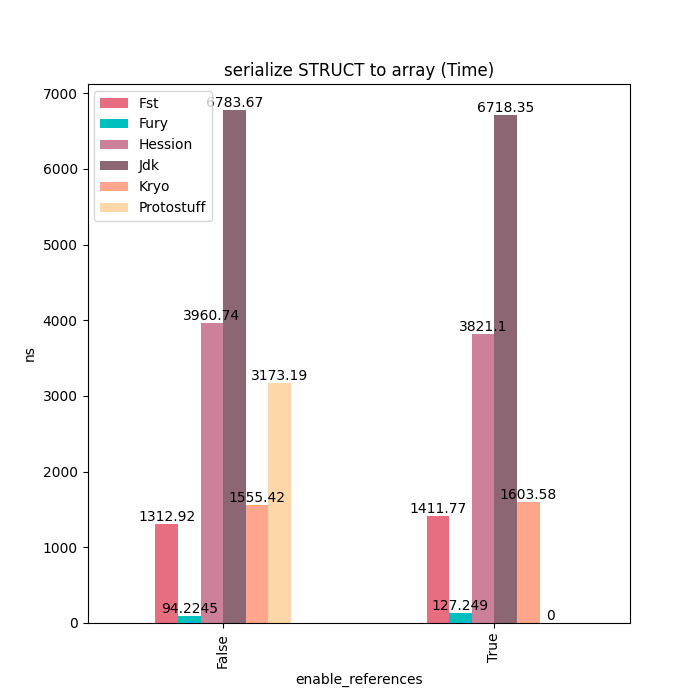
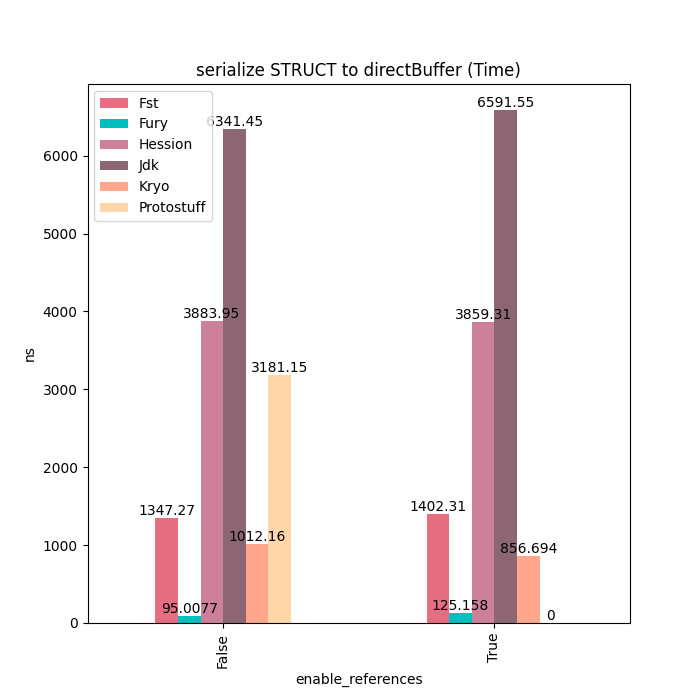
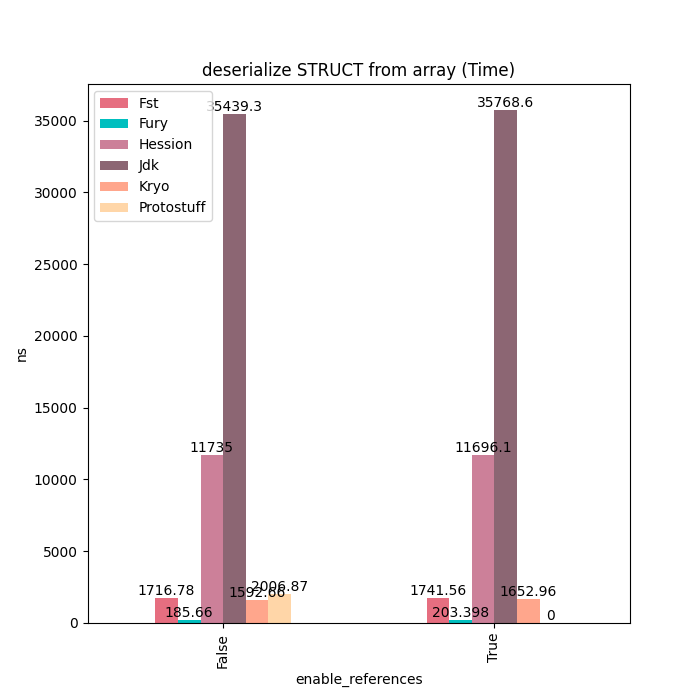
Struct类型主要是有纯基本类型的字段组成,对于这类对象,Fury通过JIT等技术,可以达到Kryo20倍的性能。
序列化:
反序列化:
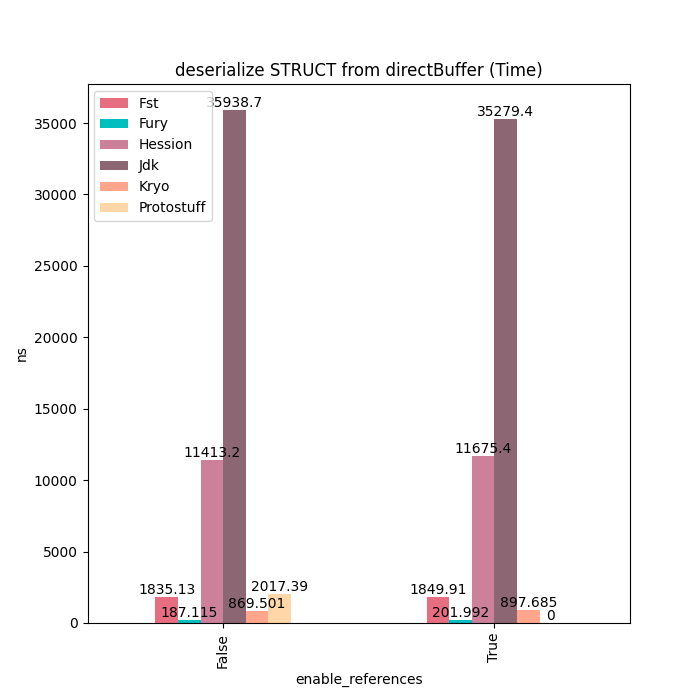
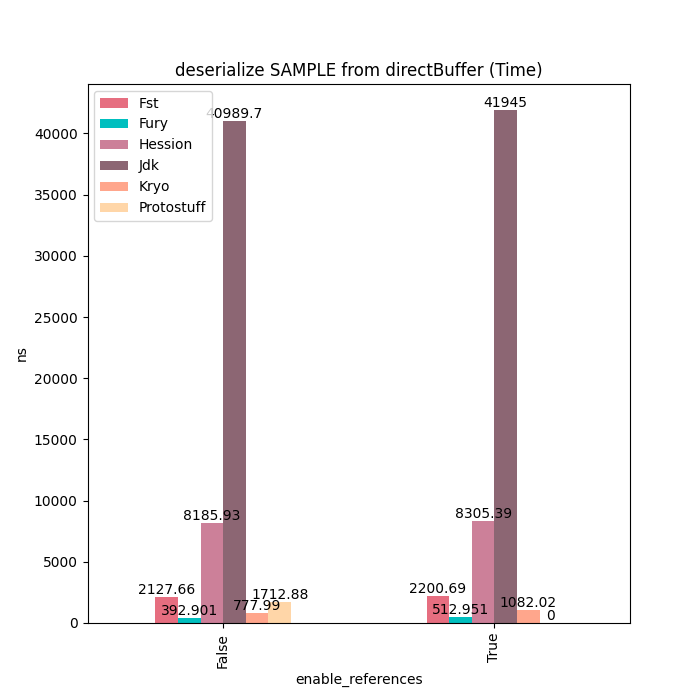
Sample
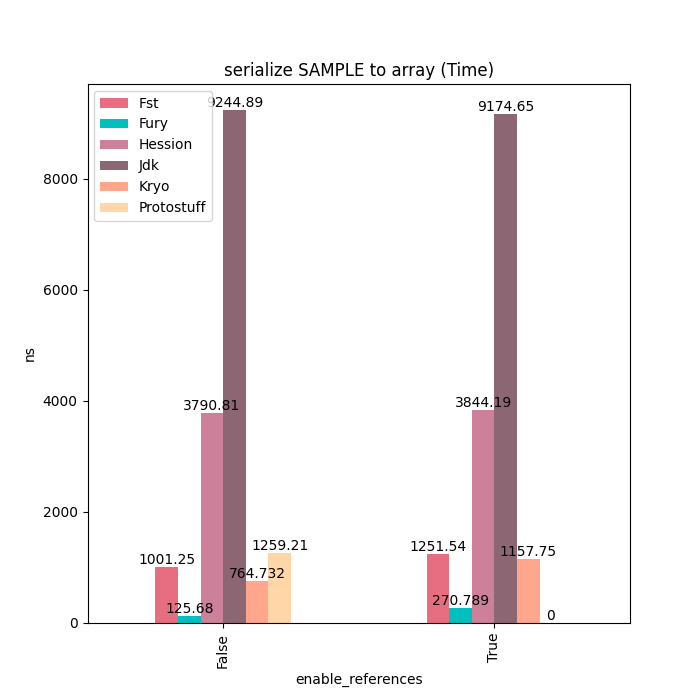
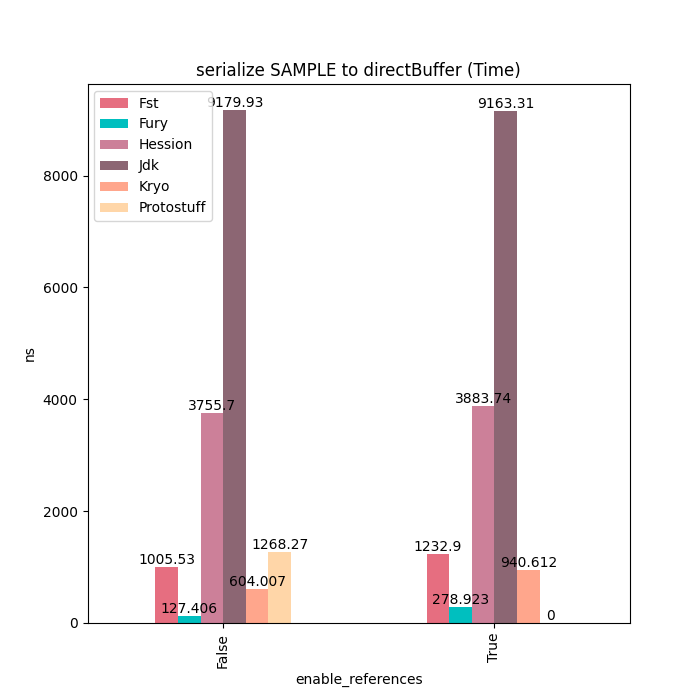
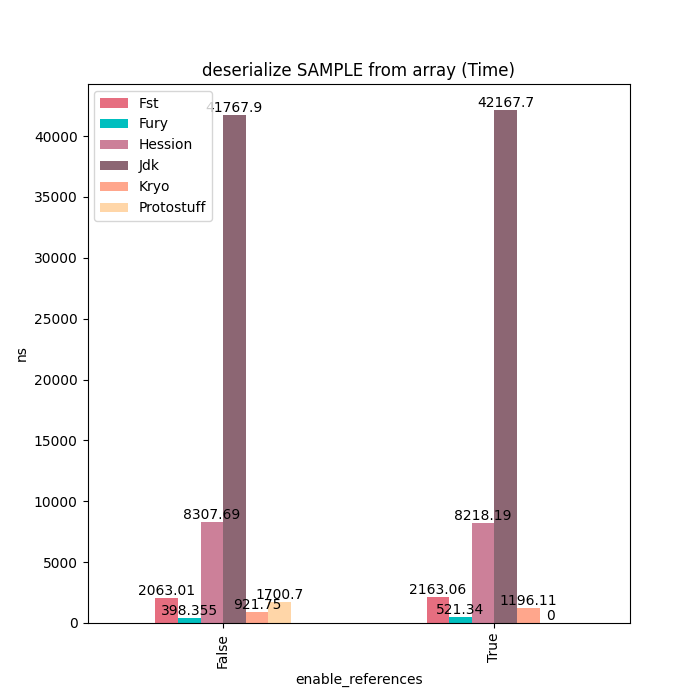
Sample类型主要由基本类型、装箱类型、字符串和数组等类型字段组成,对于这种类型的对象,Fury的性能可以达到Kryo的6~7倍。没有更快的原因是因为这里的多个基本类型数组需要进行拷贝,这块占用一定的耗时。如果使用Fury的Out-Of-Band序列化的话。这些额外的拷贝就可以完全避免掉,但这样比较不太公平,因此这里没有开启。
序列化耗时:
反序列化耗时:
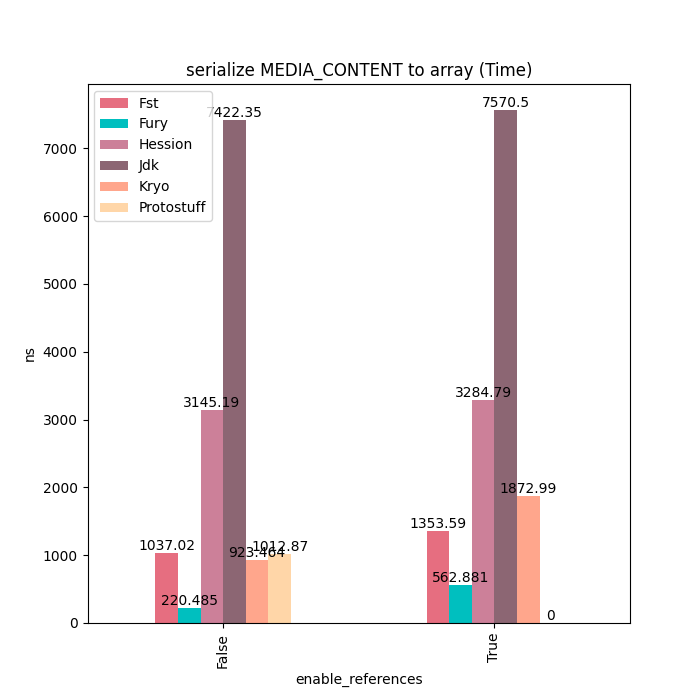
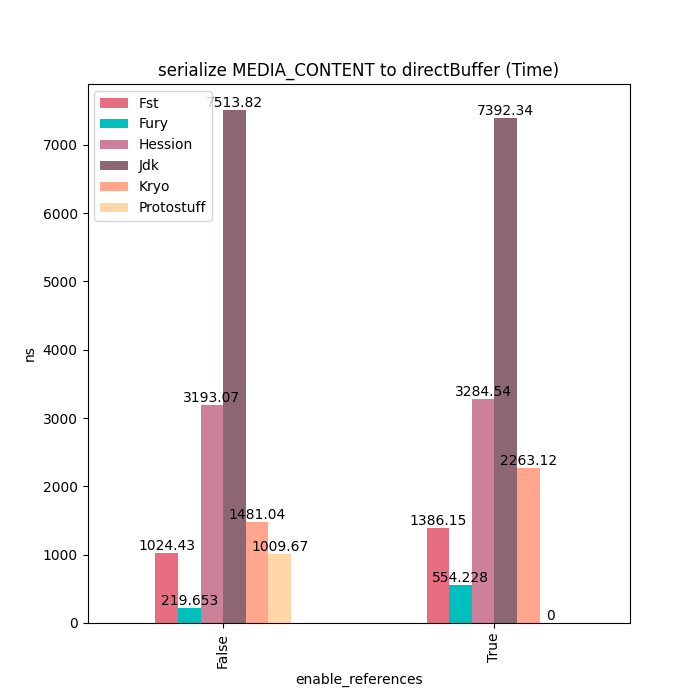
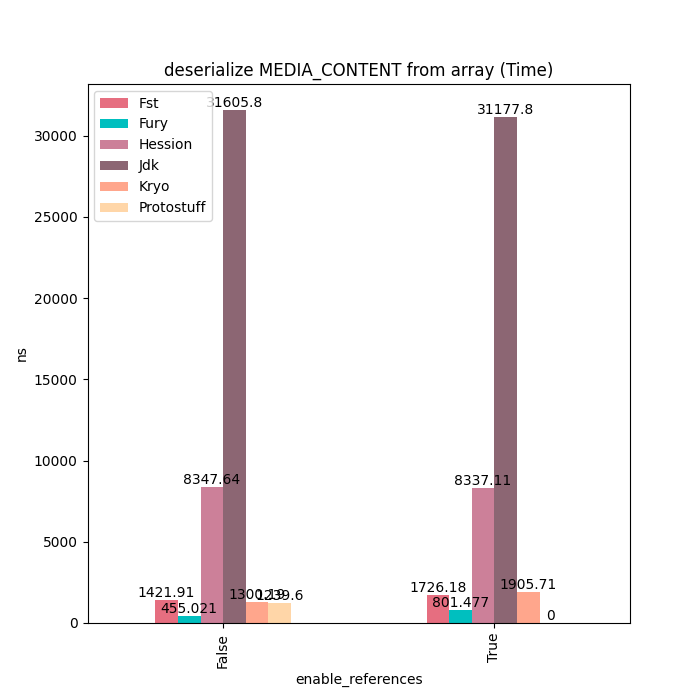
MediaContent
对于MediaContent这类包含大量String的数据结构,Fury性能大概是Kryo的4~5倍。没有更快的原因是因为String序列化开销比较大,部分摊平了Fury JIT带来的性能提升。用户如果对String序列化有更好的性能要求的话,可以使用Fury的String零拷贝序列化协议,在序列化时直接把String内部的Buffer抽取出来,然后直接放到Out-Of-Band buffer里面,完全避免掉String序列化的开销。
序列化耗时:
反序列化耗时:
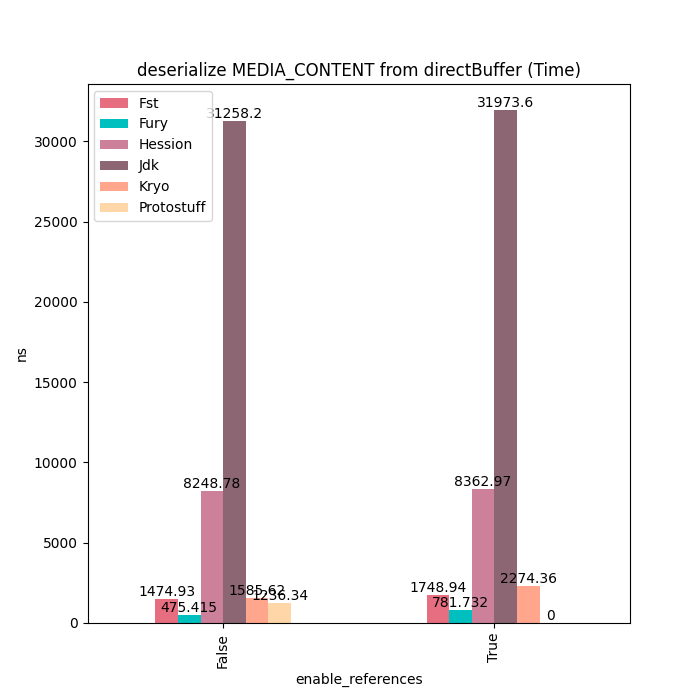
Buffer零拷贝性能对比
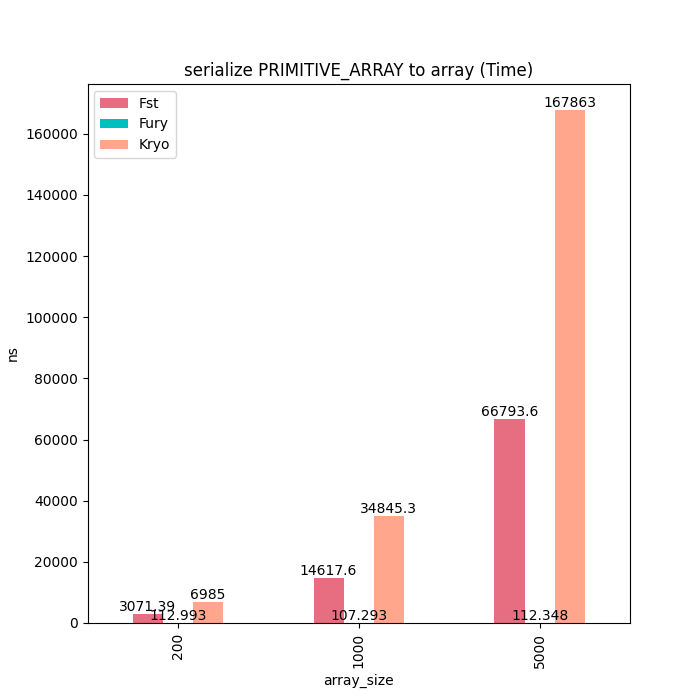
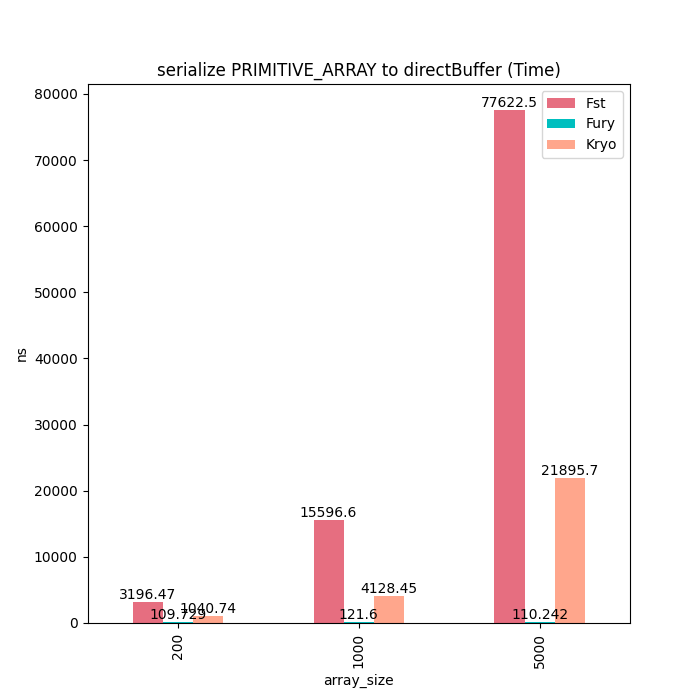
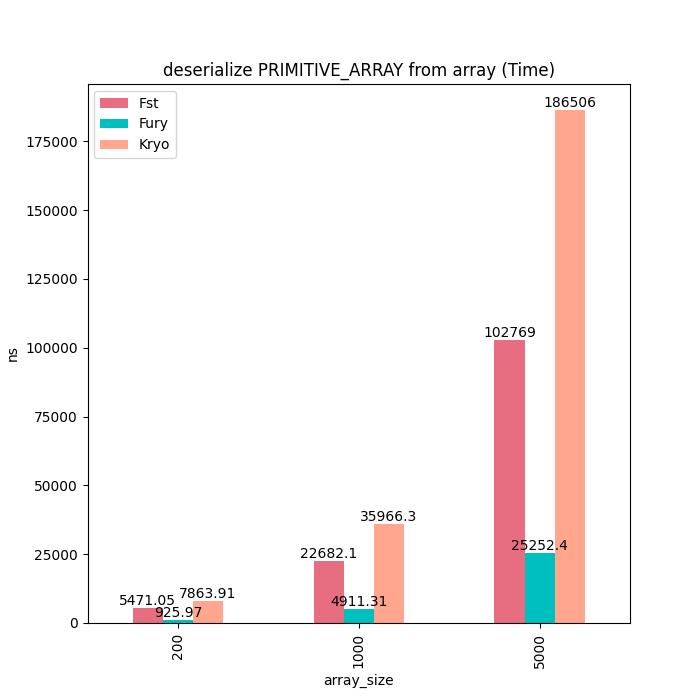
基本类型数组
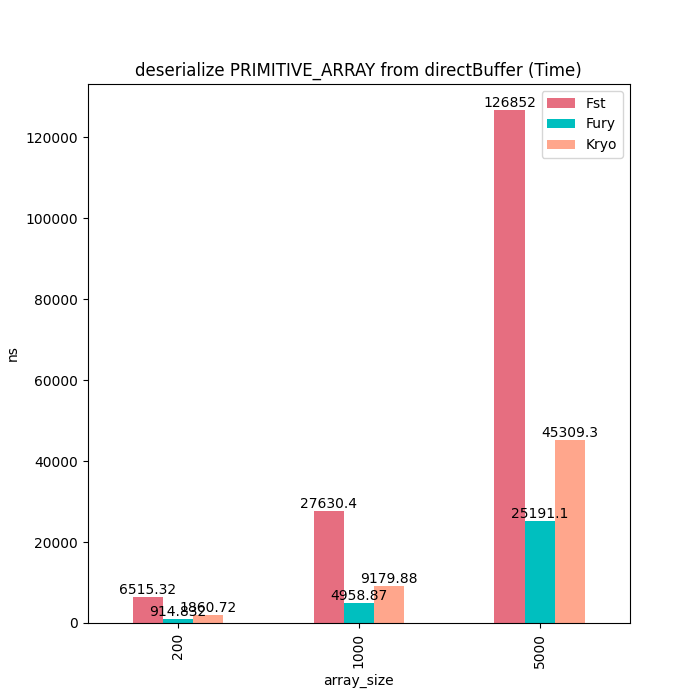
对于基本类型可以看到Fury序列化几乎耗时为0,而别的框架耗时随着数组大小线性增加。
反序列时Fury耗时也会线性增加是因为需要把Buffer拷贝到Java基本类型数组里面。
序列化耗时:
反序列耗时:
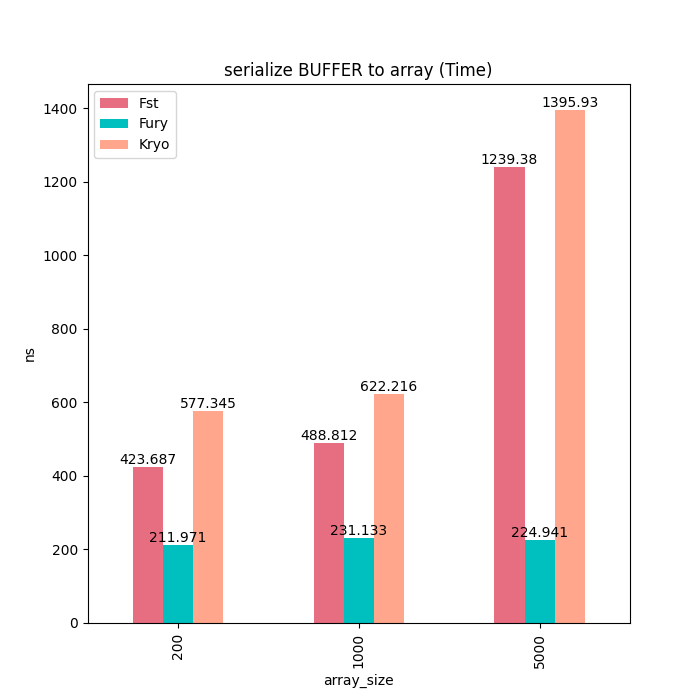
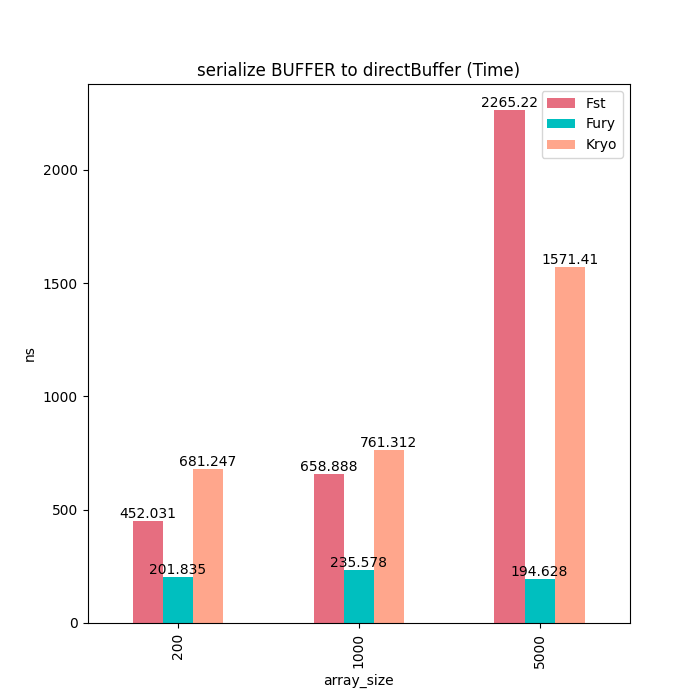
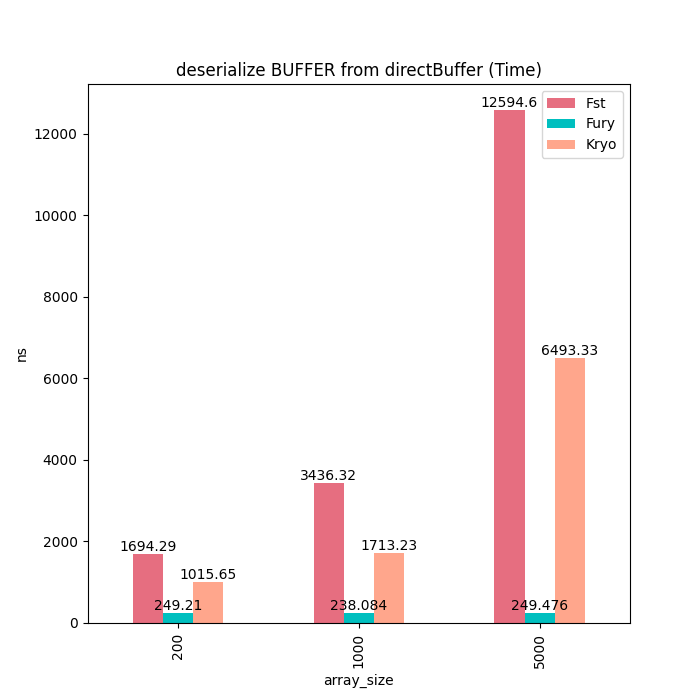
堆外Buffer
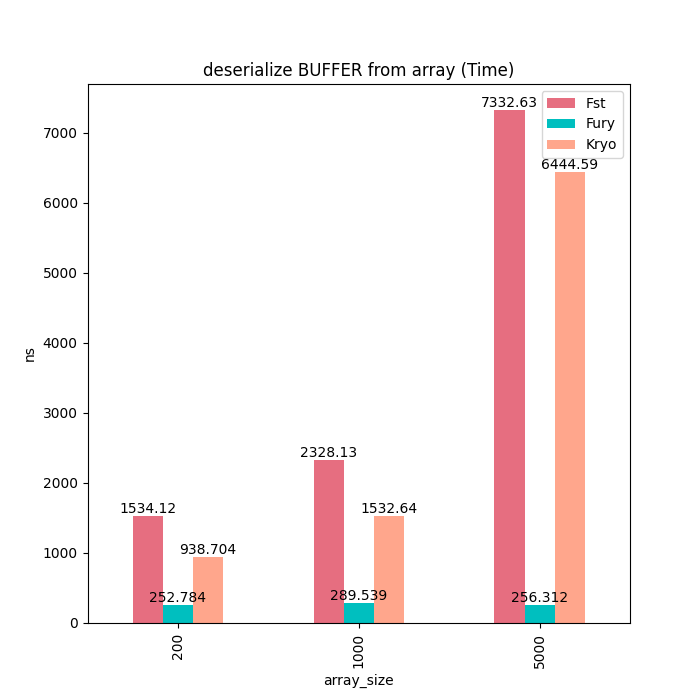
除了基本类型数组,我们也测试了Java ByteBuffer的序列化性能。由于Kryo和Fst并不支持ByteBuffer序列化,同时并没有提供直接读写ByteBuffer的接口,因此我们使用了byte array来模拟内存拷贝。可以看到对于堆外Buffer,Fury的序列化和反序列化耗时都是一个常量,不随Buffer大小而增加。
序列化耗时:
反序列化耗时:
易用性比较
这里以一个自定义类型为例对比易用性,该类型包含常见基本类型字段以及集合类型字段,最终需要序列化的对象是一个Bar的实例:
Fury序列化
Fury序列化只需一行代码,且无任何学习成本。
对比Protobuf
首先需要安装protoc编译器[10],注意protoc的版本不能高于proto依赖库的版本
然后定义针对需要序列化的对象的schema:
然后通过protoc编译schema生成Java/Python/GoLang代码文件。
java: protoc --experimental_allow_proto3_optional -I=src/main/java/io/ray/fury/benchmark/state --java_out=src/main/java/ bench.proto
bench.proto
生成Python/GoLang代码
为了避免把生成的代码提交到代码仓库,需要将proto跟构建工具进行集成,这块较为复杂,存在大量构建工具集成成本。且由于构建工具的不完善,这部分依然无法完全自动化,比如protobuf-maven-plugin[11]依然需要用户在机器安装protoc,而不是自动下载protoc。
由于大部分场景都是用户已经有了自定义类型和基本类型以及组合类型构成的对象(树)需要被序列化,因此需要将用户类型对象转换成protobuf格式。这里面就有较大的开发成本,且每种需要都需要写一遍,代码冗长且易出错难维护,同时还存在大量数据转换和拷贝开销。另外转换过程没有考虑实际类型,因此还存在类型丢失的问题,比如LinkedList反序列化回来变成了ArrayList。下面是Java的序列化代码,大概需要130~150行。
Python序列化代码:大概130~150行
GoLang序列化代码:大概130~150行
即使之前没有针对该数据的自定义类型,也无法将protobuf生成的class直接用在业务代码里面。因为protobuf生成的class并不符合面向对象设计[12],无法给生成的class添加行为。这时候就需要定义额外的wrapper,如果自动内部有其它自定义类型,还需要将这些类型转换成对应的wrapper,这进一步限制了使用的灵活性。
对比Flatbuffer
Flatbuffer与protobuf一样,也需要大量的学习成本和开发成本:
安装flatc编译器[13],对于Linux环境,可能还需要进行源码编译安装flatc。
定义Schema
然后通过flatc编译schema生成Java/Python/GoLang代码文件。
java: flatc -I=src/main/java/io/ray/fury/benchmark/state -o=src/main/java/ bar.fbs
生成Python/GoLang代码
为了避免把生成的代码提交到代码仓库,需要将proto跟构建工具进行集成,目前似乎只有bazel构建工具有比较好的集成,别的构建工具如maven/gradle等似乎都没有比较好的集成方式。
因为生成的类不符合面向对象设计无法直接添加行为,同时已有系统里面已经有了需要被序列化的类型,因此也需要将已有类型的对象序列化成flatbuffer格式。Flatbuffer序列化代码不仅存在和Protobuf一样代码冗长易出错难维护问题,还存在以下问题:
代码不灵活、难写且易出错。由于flatbuffer在序列化对象树时需要先深度优先和先序遍历整颗对象树,并手动保存每个变长字段的offset到临时状态,然后再序列化所有字段偏移或者内联标量值,这块代码写起来非常繁琐,一旦offset存储出现错误,序列化将会出现assert/exception/panic等报错,较难排查。
list元素需要按照反向顺序进行序列化不符合直觉。由于buffer是从后往前构建,因此对于list,需要将元素逆向依次进行序列化。
不支持map类型,需要将map序列化为两个list或者序列化为一个table,进一步带来了额外的开发成本。
下面是Java的序列化代码,大概需要100~150行;处理每个字段是否为null,大概还需要100行左右代码。因此Java序列化大概需要200~250行代码:
Python序列化代码:大概200~250行
GoLang序列化代码:大概200~250行
将Flatbuffer生成类型包装到其它符合面向对象设计的类里面:由于Flatbuffer序列化过程需要保存大量中间offset,且需要先把所有可变长度对象写入buffer,因此通过wrapper修改flatbuffer数据会比较复杂,使得包装Flatbuffer生成类型只适合反序列化读数据过程,导致添加wrapper也变得很困难。
对比Msgpack
Msgpack Java和Python并不支持自定义类型序列化,需要用户增加扩展类型手动进行序列化,因此这里省略。
总结
Fury最早是我在2019年开发,当时是为了支持分布式计算框架Ray[14]的跨语言序列化以及蚂蚁在线学习场景样本流的跨语言传输问题。经过蚂蚁丰富业务场景的打磨,目前已经在蚂蚁在线学习、运筹优化、Serving等多个计算场景稳定运行多年。
总体来看Fury主要优势主要是:
跨语言原生序列化,大幅提高了跨语言序列化的易用性,降低研发成本;
通过JIT技术来优化序列化性能。这里也可以看到通过把数据库和大数据领域的代码生成思想用在序列化上面是一个很好的思路,可以取得非常显著的性能提升;
Zero-Copy序列化,避免所有不必要的内存拷贝;
多语言行存支持避免序列化和元数据开销;
未来我们会在协议、框架和生态三个方面继续优化:
协议层面
JIT代码生成支持数据压缩模式
进一步通过SIMD向量化指令进行大规模数据压缩
框架层面
更多Java序列化代码JIT化;
完善C++支持,通过使用Macro、模板和编译时反射在编译时注册捕获Fury需要的类型信息,实现自动C++序列化;
通过Golang-ASM支持基于JIT的Golang序列化实现;
通过将更多Python代码Cython化来进一步加速Python序列化;
支持JavaScript,打通NodeJS生态;
支持Rust;
生态层面
与RPC框架SOFA、Dubbo、Akka等集成
与分布式计算框架Spark和Flink等集成
参考链接:
[1]https://github.com/EsotericSoftware/kryo
[2]https://spark.apache.org/docs/latest/index.html
[3]https://flink.apache.org/
[4]https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html
[5]https://arrow.apache.org/
[6]https://developers.google.com/protocol-buffers/docs/javatutorial#parsing-and-serialization
[7]https://peps.python.org/pep-0574
[8]https://github.com/EsotericSoftware/kryo/tree/master/benchmarks
[9]https://openjdk.org/projects/code-tools/jmh/
[10]https://developers.google.com/protocol-buffers/docs/downloads
[11]https://www.xolstice.org/protobuf-maven-plugin/usage.html
[12]https://developers.google.com/protocol-buffers/docs/javatutorial#parsing-and-serialization
[13]https://github.com/google/flatbuffers/releases
[14]https://github.com/ray-project/ray