
翻译自
这个系列的博文面向那些已经熟悉go的基本语法并想要深入了解内部原理的读者。今天的博文主要介绍go源码结构和一些go编译器细节。读完这篇文章,你应该可以回答以下问题:
1. go源码的结构是什么样的?
2. go编译器是如何工作的?
3. go的node tree的基本结构是什么样的?
开始准备
当你开始学习一门新的语言时,你通常可以找到许多"helloworld"的教程、入门指导、或者关于语言概念、语法、甚至标准库的书。然而,从这些资料上无法获取到语言runtime分配的内存布局或者当你调用内部函数时生成的汇编代码。显然的,这些答案隐藏来源码之中,但是,按照我的经验,你可能花费了几个小时思考,但是却没有取得什么进展。在这个主题,我即不会装作是一个专家,也不会尝试解释每个概念。相反,本文的目标是使你独立的识别go的源码。 开始之前,我们需要一份源码的拷贝。简单执行下面的命令。
git clone https://github.com/golang/go注意master分支的代码已经更新了许多,因此我们使用 release-branch.go1.4 分支。
项目结构
/src

编译器
/src/cmd/gclex.cgo.y深入GO语法
现在让我们看一下第二步。理解go编译器和语法,包含了语法的`go.y`文件是一个很好的切入点。文件的主要部分包括声明,如下:
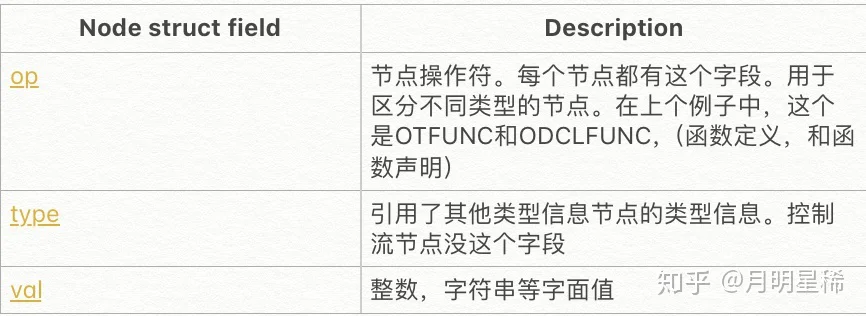
xfndcl:
LFUNC fndcl fnbody
fndcl:
sym '(' oarg_type_list_ocomma ')' fnres
| '(' oarg_type_list_ocomma ')' sym '(' oarg_type_list_ocomma ')' fnresxfndclfundclfundcksomefunction(x int, y int) int(t *SomeType) somefunction(x int, y int) intxfndclfuncLFUNCfndclfnbodynodes$$,$1,$2$$fndcl:
sym '(' oarg_type_list_ocomma ')' fnres
{
t = nod(OTFUNC, N, N);
t->list = $3;
t->rlist = $5;
$$ = nod(ODCLFUNC, N, N);
$$->nname = newname($1);
$$->nname->ntype = t;
declare($$->nname, PFUNC);
}
| '(' oarg_type_list_ocomma ')' sym '(' oarg_type_list_ocomma ')' fnres$3$5oarg_type_list_ocommafnres$$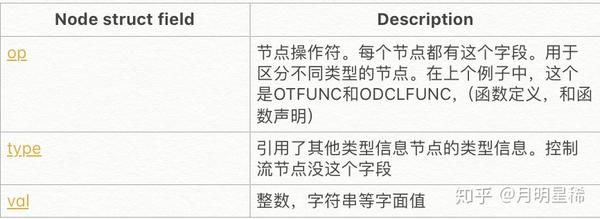
现在你理解了语法树等基本结构。你可以实践一下。在下面的内容,我们会使用一个简单的go程序分析汇编码的生成。
深入编译器
interfacego tool 6g test.go这会编译test.go并生成目标文件。这里6g时amd64下的编译器名字。不同的平台应该用不同的名字。有时候,我们也需要一些其他的命令行参数。例如,我们用 -W标志打印语法树的结构。 创建一个简单的go程序。 首先,创建一个简单的程序。
1 package main
2
3 type I interface {
4 DoSomeWork()
5 }
6
7 type T struct {
8 a int
9 }
10
11 func (t *T) DoSomeWork() {
12 }
13
14 func main() {
15 t := &T{}
16 i := I(t)
17 print(i)
18 }接着编译它
go tool 6g -W test.gomaininitinit语法树的main函数
DCL l(15)
. NAME-main.t u(1) a(1) g(1) l(15) x(0+0) class(PAUTO) f(1) ld(1) tc(1) used(1) PTR64-*main.T
AS l(15) colas(1) tc(1)
. NAME-main.t u(1) a(1) g(1) l(15) x(0+0) class(PAUTO) f(1) ld(1) tc(1) used(1) PTR64-*main.T
. PTRLIT l(15) esc(no) ld(1) tc(1) PTR64-*main.T
. . STRUCTLIT l(15) tc(1) main.T
. . . TYPE <S> l(15) tc(1) implicit(1) type=PTR64-*main.T PTR64-*main.T
DCL l(16)
. NAME-main.i u(1) a(1) g(2) l(16) x(0+0) class(PAUTO) f(1) ld(1) tc(1) used(1) main.I
AS l(16) tc(1)
. NAME-main.autotmp_0000 u(1) a(1) l(16) x(0+0) class(PAUTO) esc(N) tc(1) used(1) PTR64-*main.T
. NAME-main.t u(1) a(1) g(1) l(15) x(0+0) class(PAUTO) f(1) ld(1) tc(1) used(1) PTR64-*main.T
AS l(16) colas(1) tc(1)
. NAME-main.i u(1) a(1) g(2) l(16) x(0+0) class(PAUTO) f(1) ld(1) tc(1) used(1) main.I
. CONVIFACE l(16) tc(1) main.I
. . NAME-main.autotmp_0000 u(1) a(1) l(16) x(0+0) class(PAUTO) esc(N) tc(1) used(1) PTR64-*main.T
VARKILL l(16) tc(1)
. NAME-main.autotmp_0000 u(1) a(1) l(16) x(0+0) class(PAUTO) esc(N) tc(1) used(1) PTR64-*main.T
PRINT l(17) tc(1)
PRINT-list
. NAME-main.i u(1) a(1) g(2) l(16) x(0+0) class(PAUTO) f(1) ld(1) tc(1) used(1) main.I为了简要,采取了删减版的代码。 第一个节点很简单:
DCL l(15)
. NAME-main.t l(15) PTR64-*main.T第一个节点是声明节点。I(15)说么这个节点在15行定义。节点引用了代表matin.t变量的节点。这个变量在main包中定义,是一个main.T类型的指针。通过15行可以看出这一点。 下一个有些复杂。
AS l(15)
. NAME-main.t l(15) PTR64-*main.T
. PTRLIT l(15) PTR64-*main.T
. . STRUCTLIT l(15) main.T
. . . TYPE l(15) type=PTR64-*main.T PTR64-*main.Tmain.tmain.tmain.Tmain.Imain.iDCL l(16)
. NAME-main.i l(16) main.Iautotmp_0000main.tAS l(16) tc(1)
. NAME-main.autotmp_0000 l(16) PTR64-*main.T
. NAME-main.t l(15) PTR64-*main.T最后,这是关键的节点。
AS l(16)
. NAME-main.i l(16)main.I
. CONVIFACE l(16) main.I
. . NAME-main.autotmp_0000 PTR64-*main.Tmain.iAS-init
. AS l(16)
. . NAME-main.autotmp_0003 l(16) PTR64-*uint8
. . NAME-go.itab.*"".T."".I l(16) PTR64-*uint8
. IF l(16)
. IF-test
. . EQ l(16) bool
. . . NAME-main.autotmp_0003 l(16) PTR64-*uint8
. . . LITERAL-nil I(16) PTR64-*uint8
. IF-body
. . AS l(16)
. . . NAME-main.autotmp_0003 l(16) PTR64-*uint8
. . . CALLFUNC l(16) PTR64-*byte
. . . . NAME-runtime.typ2Itab l(2) FUNC-funcSTRUCT-(FIELD-
. . . . . NAME-runtime.typ·2 l(2) PTR64-*byte, FIELD-
. . . . . NAME-runtime.typ2·3 l(2) PTR64-*byte PTR64-*byte, FIELD-
. . . . . NAME-runtime.cache·4 l(2) PTR64-*PTR64-*byte PTR64-*PTR64-*byte) PTR64-*byte
. . . CALLFUNC-list
. . . . AS l(16)
. . . . . INDREG-SP l(16) runtime.typ·2 G0 PTR64-*byte
. . . . . ADDR l(16) PTR64-*uint8
. . . . . . NAME-type.*"".T l(11) uint8
. . . . AS l(16)
. . . . . INDREG-SP l(16) runtime.typ2·3 G0 PTR64-*byte
. . . . . ADDR l(16) PTR64-*uint8
. . . . . . NAME-type."".I l(16) uint8
. . . . AS l(16)
. . . . . INDREG-SP l(16) runtime.cache·4 G0 PTR64-*PTR64-*byte
. . . . . ADDR l(16) PTR64-*PTR64-*uint8
. . . . . . NAME-go.itab.*"".T."".I l(16) PTR64-*uint8
AS l(16)
. NAME-main.i l(16) main.I
. EFACE l(16) main.I
. . NAME-main.autotmp_0003 l(16) PTR64-*uint8
. . NAME-main.autotmp_0000 l(16) PTR64-*main.TAS-initmain.autotmp_0003go.itab.*””.T.””.Iruntime.typ2Itabmain.Tmain.Igo.itab.*””.T.””.Igetitab函数
runtime.typ2Itabfunc typ2Itab(t *_type, inter *interfacetype, cache **itab) *itab {
tab := getitab(inter, t, false)
atomicstorep(unsafe.Pointer(cache), unsafe.Pointer(tab))
return tab
}显然真正的工作是在getitab中,第二句只是一个简单的赋值。接下来分析getitab,这个函数很大,所以只截取部分。
m =
(*itab)(persistentalloc(unsafe.Sizeof(itab{})+uintptr(len(inter.mhdr)-1)*ptrSize, 0,
&memstats.other_sys))
m.inter = interm._type = typ
ni := len(inter.mhdr)
nt := len(x.mhdr)
j := 0
for k := 0; k < ni; k++ {
i := &inter.mhdr[k]
iname := i.name
ipkgpath := i.pkgpath
itype := i._type
for ; j < nt; j++ {
t := &x.mhdr[j]
if t.mtyp == itype && t.name == iname && t.pkgpath == ipkgpath {
if m != nil {
*(*unsafe.Pointer)(add(unsafe.Pointer(&m.fun[0]), uintptr(k)*ptrSize)) = t.ifn
}
}
}
}首先分配内存,persistentalloc是go的一个内存分配器。注意,它分配的内存无法释放,会一直存在。 为什么要用它分配呢?我们看一下itab结构体。
type itab struct {
inter *interfacetype
_type *_type
link *itab
bad int32
unused int32
fun [1]uintptr // variable sized
}最后一个字段,是定义为了一个只有一个元素的数组,但其实是可变大小的。(参考gcc变长数组)。接着来看这个数组指针。这些方法和interface里的方法一样。go的作者动态分配这个内存。(当你用unsafe时分配的都是这种内存).内存的大小时结构体自身大小加上interface里的函数数量乘以指针大小
unsafe.Sizeof(itab{})+uintptr(len(inter.mhdr)-1)*ptrSize接下来,是两个内嵌循环。首先,我们遍历所有的interface方法。对每个方法都试着找出相关的类型(在mhdr表中储存的)。这是为了检查两个方法是否匹配。 如果我们找到一个匹配的,我们吧指针储存在fun字段中。
*(*unsafe.Pointer)(add(unsafe.Pointer(&m.fun[0]), uintptr(k)*ptrSize)) = t.ifn一个小知识:由于方法都是按照字典序排序的,这个循环可以是O(m+n)而不是O(n*m) 最后是真正的赋值。
AS l(16)
. NAME-main.i l(16) main.I
. EFACE l(16) main.I
. . NAME-main.autotmp_0003 l(16) PTR64-*uint8
. . NAME-main.autotmp_0000 l(16) PTR64-*main.Tmain.imain.autotmp_0003main.autotmp_0003runtime.typ2Itabmain.itype iface struct {
tab *itab
data unsafe.Pointer
}