
关于如何在一个方向或者一个领域进阶项目,总共分为4步。
1.分析关键点
2.博采众长
3.压缩提炼
4.动手
下面这个链接是我已分布式缓存举例的一个项目进阶过程。
同样,本篇回答也继续带来golang缓存的相关框架通读。
前面我们已经看了缓存的介绍、相关知识。还有gocache和bigcache的代码通读。感兴趣的同学可以点击链接查看:
从阅读难度上看,freecache略大于bigcache远大于gocache,从性能上则是完全反过来。这也是性能优化的一个很重要的规律,牺牲可读性换来性能,因为更高的性能就涉及更多的底层相关优化,此时代码的可读性显而易见就会降低。
FreeCache介绍
链接:
FreeCache特性
直接搬运github上的介绍,主要包括大数据量,零GC压力,线程安全,近似LRU算法,严格的内存使用等等。后面也将从代码分析中说明FreeCache是如何实现这五点的。
- Store hundreds of millions of entries
- Zero GC overhead
- High concurrent thread-safe access
- Pure Go implementation
- Expiration support
- Nearly LRU algorithm
- Strictly limited memory usage
- Come with a toy server that supports a few basic Redis commands with pipeline
- Iterator support
FreeCache数据结构
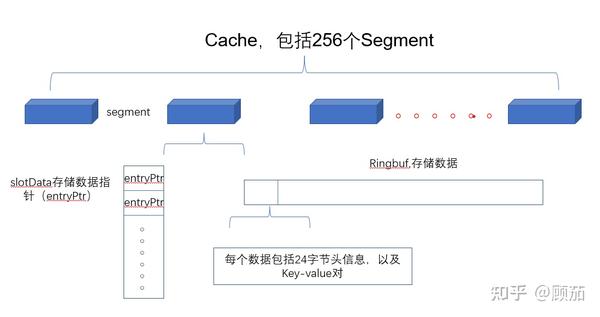
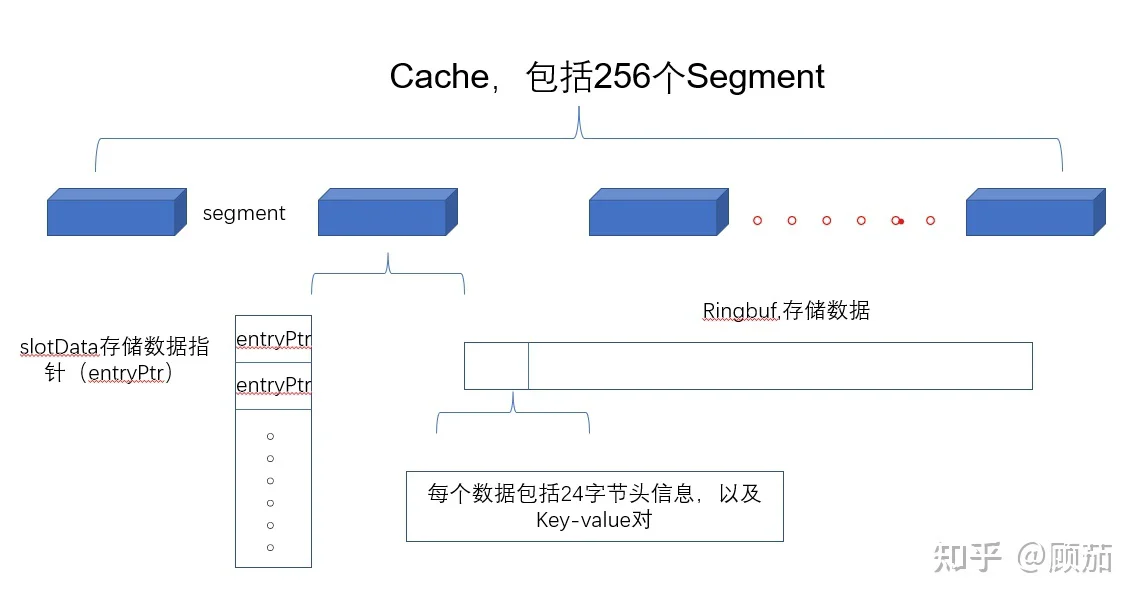
如果没有看到数据结构的设计,只看代码会非常的吃力。整个FreeCache的数据结构只有256个Segement,里面包括存储键值对索引的slotData,每个索引指针名称为entryPtr。还有存储数据的ringbuf,ringbuf存储的每个数据包括24字节的数据头和数据的实际键值对。这意味着每个segment只有一个slotData切片和ringbuf的data切片,也就是说,整个数据结构只有256*2个指针,非常少的指针数量意味着极小的gc压力。
结构体与方法分析
cache
cache包括两个数组,一个256大小的段(segment)数组和对应的锁数组。这里采用数组而不是指针,也是减少GC压力。
再看set函数,实质上与之前学习过的BIgCache类似。都是先利用hash(key)找到对应的segments位置,再锁住整个segment并调用segment的Set函数(此处锁的粒度还是比较大的。。)。
Segment
一个segment包含256个槽(slots),每个槽包含一个指向数据(entry)的指针数组。仔细看每个segment包含一个ringbuf,这是存储实体数据的字段。slotsData则是存储数据的指针。其他的都是些辅助统计字段。
set中,值得关注的点包括:
- slot := seg.getSlot(slotId), 这里由于slotsData数组是所有槽共用的,因此需要根据槽容量和slotID定位到偏移值,取出对应的entryPtr,这里三段式索引在通常语法上是不允许的,第三个表示最大能索引的值,可以理解为seg.slotsData[start(slotOff) : end(slotOff+seg.slotLens[slotId]), capend(slotOff+seg.slotCap)]。
2. 寻找位置。idx, match := seg.lookup(slot, hash16, key),这里是为了找到set的key-value在一个槽内的位置。作者利用了二分查找,感兴趣的同学可以推演其中一些极端的情况,比如所有值都大于传入的这个hash-key,或者都小于,或者都等于,推演后可以发现,逻辑上都没问题。
3.寻找空间。找到位置之后,我们还要注意目前这个数据的位置是否可以承载对应的空间,我们分几种情况讨论。
1.key匹配,原先的value空间大于现在的,那么很简单。把新值拷贝到旧值的空间中即可。


2.原先的value空间不够现在的value放置,拿就得删除掉原有的key-value,再把新值放入。
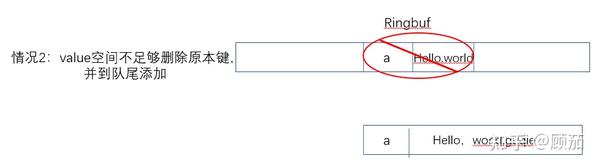
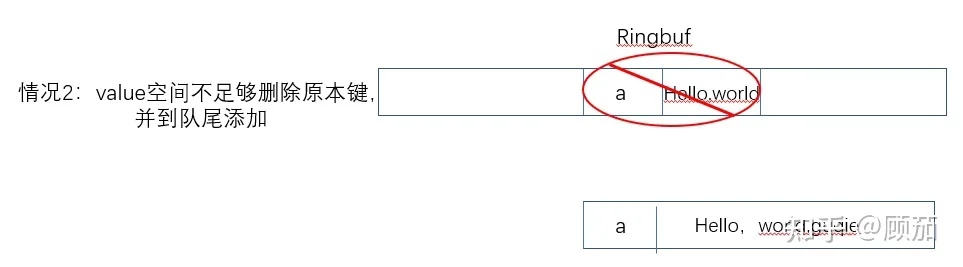
3.key不匹配,也是一样,我们从队尾把新值放入即可。整体的逻辑就如evacuate函数所示。
evacuate函数,可以理解成为新数据寻找空间,逻辑如下:1.先判断剩余空间是否小于新数据大小,如果不小于说明剩余空间足够,那么就可以退出了。如果小于按以下优先级来腾出空间。
- 读取segment第一个数据(对应offset的),如果该数据已经删除,那么就更新seg.vacuumLen
- 如果该数据已经过期或很久未使用或已经搜寻多次了,删除该数据并腾出空间。否则就继续往后找其他数据是否可以删除。
entry与RingBuf
entryPtr为每个数据的指针,主要包括该entry在ringbuf中的位置、entry的hash值,长度等等。entryHdr则是跟在每个key-value数据后面的相关信息。
RingBuf则包含着一些数据存储字段和起始位置等等。阅读RingBuf的代码时要注意:为了提高性能,ringbuf内的空间是覆盖写的,也就是如果数据写满了,将会从开头的位置写入。
总结
在本篇中,我们梳理了freeCache的数据结构,有以下几点值得大家在代码中学习。
- 指针的使用,指针就意味着gc负担,如果是非常高的性能场景,则尽量减少指针的使用。
- 在[]byte与struct的转化中大量使用unsafe.Pointer进行读取和转化,可以优化读取性能。
- 由于是在并发场景下运行,为了保证数据操作的原子性,使用atomic.AddInt64。
- hash与二分查找等经典的算法仍然有很大的用武之地,无论在键值匹配还是在数据查找中都很有帮助。
最后祝大家金三银四春招顺利,我是顾茄,干杯!

