
在服务端程序当中,缓存作为一种应对高并发的方法,通常是必不可少的。
freeCachebigCache缓存的优势
- 读写数据存储在内存中,读写速度比磁盘快
- 通常引入缓存能够保护持久化数据库(如MySQL)在高并发场景下被打垮
引入缓存会带来的问题
- 提升系统复杂程度,降低可维护性,增加排查问题的难度
- 需要投入更多的精力去保证缓存数据一致性
- 可能会随之引入缓存穿透、缓存雪崩等问题
本地缓存与缓存中间件的对比
- 本地缓存直接读写本机内存,读写效率较高。读写缓存中间件不仅消耗缓存中间件服务器本身的IO ,同时需要网络IO ,时间消耗相对较高
- 本地缓存与服务本身耦合严重,不利于扩展性。同时使用本机内存 ,可能对本机服务有影响,存在线程安全的问题
- 本地缓存通常指针对单机,缓存中间件可以支持多服务器
为什么有了缓存中间件还要引入本地缓存
降低对缓存中间件服务器的压力什么场景下可以使用本地缓存
- 缓存中间件服务器负载过高
- 数据不太会发生更新
- 对读写性能要求很高
本地缓存是指将本地的物理内存划分出一部分空间用来缓冲程序写到服务器的数据
比较几种Golang开源的本地缓存| freecache | bigcache | fastcache | |
|---|---|---|---|
| 适用场景 | 读多写少 | 读多写少 | 读多写少 |
| 社区活跃度 | |||
| 存储数据限制 | 初始化时分配内存,不可扩容 | 每个shard数据的queue可以自动扩容 | 初始化时分配内存,不可扩容 |
| 过期时间支持 | 支持 | 支持 | 支持 |
| Key淘汰机制 | 近LRU(LRU+移动次数(Set触发)) | 定时清理 + FIFO(Set) | FIFO(类环形队列) |
| Gc | 0GC | 0GC | 0GC |
| Gc优化原理 | map非指针优化(通过slice实现map) | map[uint64]uint32 | map[uint64]uint32堆外申请内存 |
| 锁机制 | 分片+互斥锁 | 分片+读写锁 | 分片+读写锁 |
| 局限 | bucket空闲分配后无法更改 | 无法对单key设置过期时间 | 无过期时间 |
| 支持迭代器 |
针对GC优化的方式
- 无GC:分配堆外内存(Mmap)
- 避免GC: map非指针优化(map[uint64]uint32)或者采用slice实现一套无指针的map
- 避免GC:数据存入[]byte slice(环形队列封装循环使用空间)
Go1.5map没有指针GC将忽略它介绍
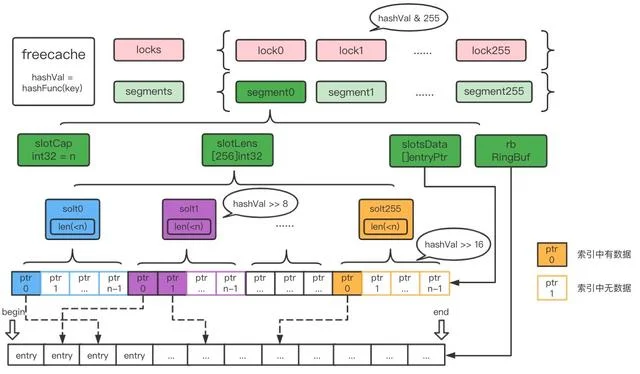
segmentsegment<!---->
环形数组entryentryheaderentry二分查找如何实现0GC: 使用map非指针优化
ringbufslotData架构图
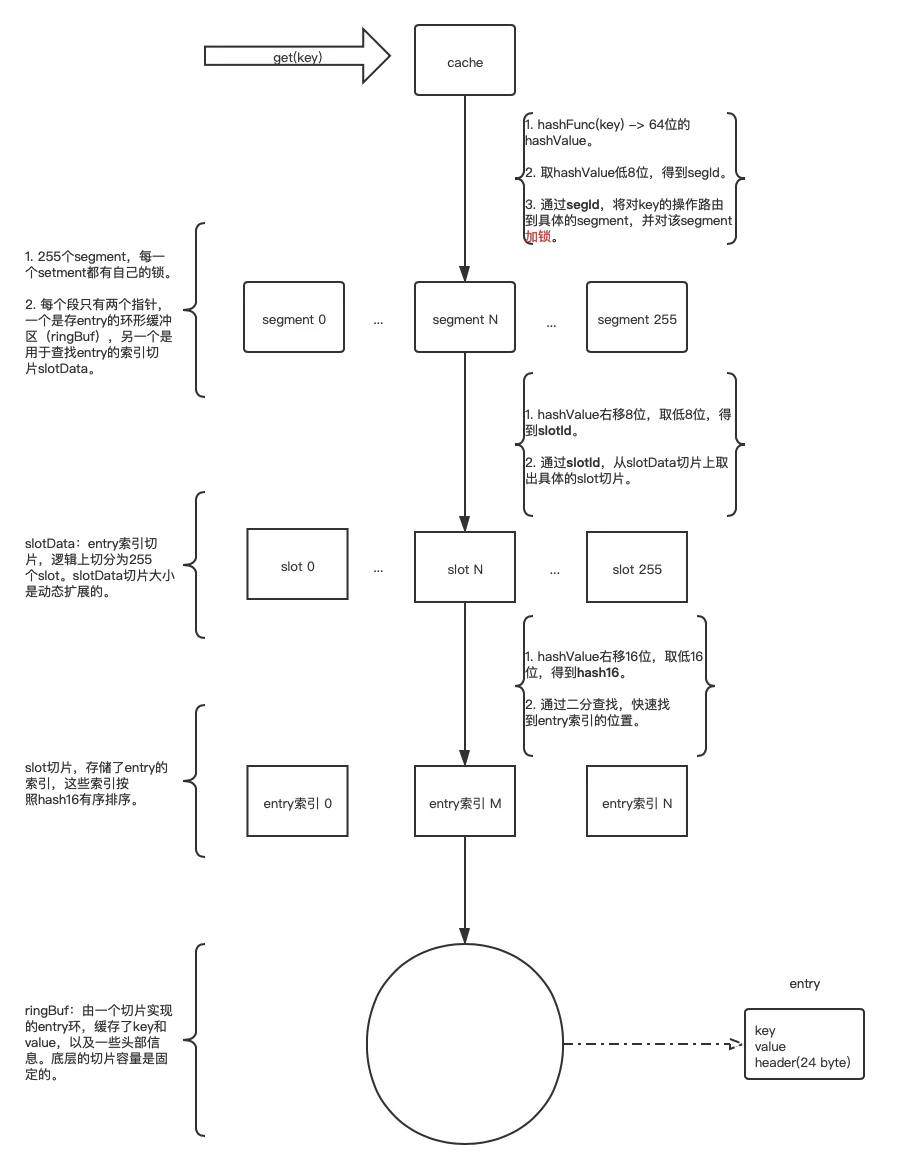
Get
流程图
代码分析
对freecache的get方法做简单的分析
Getfunc (cache *Cache) Get(key []byte) (value []byte, err error) {
hashVal := hashFunc(key)
// 1. 定位segmentId
segID := hashVal & segmentAndOpVal
// 2. 加互斥锁
cache.locks[segID].Lock()
// 3. 从对应的segment中,根据key读取数据
value, _, err = cache.segments[segID].get(key, nil, hashVal, false)
cache.locks[segID].Unlock()
return
}getlocatesegment.ringbug.ReadAtfunc (seg *segment) get(key, buf []byte, hashVal uint64, peek bool) (value []byte, expireAt uint32, err error) {
hdr, ptr, err := seg.locate(key, hashVal, peek)
if err != nil {
return
}
expireAt = hdr.expireAt
if cap(buf) >= int(hdr.valLen) {
value = buf[:hdr.valLen]
} else {
value = make([]byte, hdr.valLen)
}
seg.rb.ReadAt(value, ptr.offset+ENTRY_HDR_SIZE+int64(hdr.keyLen))
if !peek {
atomic.AddInt64(&seg.hitCount, 1)
}
return
}locate- 对slotsData二分查找 找到entry的索引idx
- 判断entry是否过期
- 更新访问时间
- 返回entry.Header信息
func (seg *segment) locate(key []byte, hashVal uint64, peek bool) (hdr *entryHdr, ptr *entryPtr, err error) {
// 1. 计算slotId 和hash16
slotId := uint8(hashVal >> 8)
hash16 := uint16(hashVal >> 16)
slot := seg.getSlot(slotId)
// 2. 对slotsData二分查找 找到entry的索引idx .虽然此处是二分查找,但slotdData()长度基本为256,因此认为时间复杂度是O(1)
idx, match := seg.lookup(slot, hash16, key)
if !match {
err = ErrNotFound
if !peek {
atomic.AddInt64(&seg.missCount, 1)
}
return
}
// 3. 拿到entry对应的slot
ptr = &slot[idx]
var hdrBuf [ENTRY_HDR_SIZE]byte
// 4. 从ringbuf中 从offset开始,将entry header写入hdrBuf中(24 bytes)
seg.rb.ReadAt(hdrBuf[:], ptr.offset)
// 5. 指针强转成entryHeader结构体
hdr = (*entryHdr)(unsafe.Pointer(&hdrBuf[0]))
if !peek {
now := seg.timer.Now()
// 6. 过期判断
if hdr.expireAt != 0 && hdr.expireAt <= now {
// entry已过期,删除entry
err= notFountd
return
}
// 7. 更新数据(访问时间)
seg.rb.WriteAt(hdrBuf[:], ptr.offset)
}
return hdr, ptr, err
}lookuplocategetreadAt 方法readAt从 offset偏移量 + header头大小entry头部设置的key长度(entry.Header.KeyLen)pfunc (rb *RingBuf) ReadAt(p []byte, off int64) (n int, err error) {
if off > rb.end || off < rb.begin {
err = ErrOutOfRange
return
}
readOff := rb.getDataOff(off)
readEnd := readOff + int(rb.end-off)
if readEnd <= len(rb.data) {
n = copy(p, rb.data[readOff:readEnd])
} else {
n = copy(p, rb.data[readOff:])
if n < len(p) {
n += copy(p[n:], rb.data[:readEnd-len(rb.data)])
}
}
if n < len(p) {
err = io.EOF
}
return
}总结
我们来总结一下get方法的流程
互斥锁Set
流程图
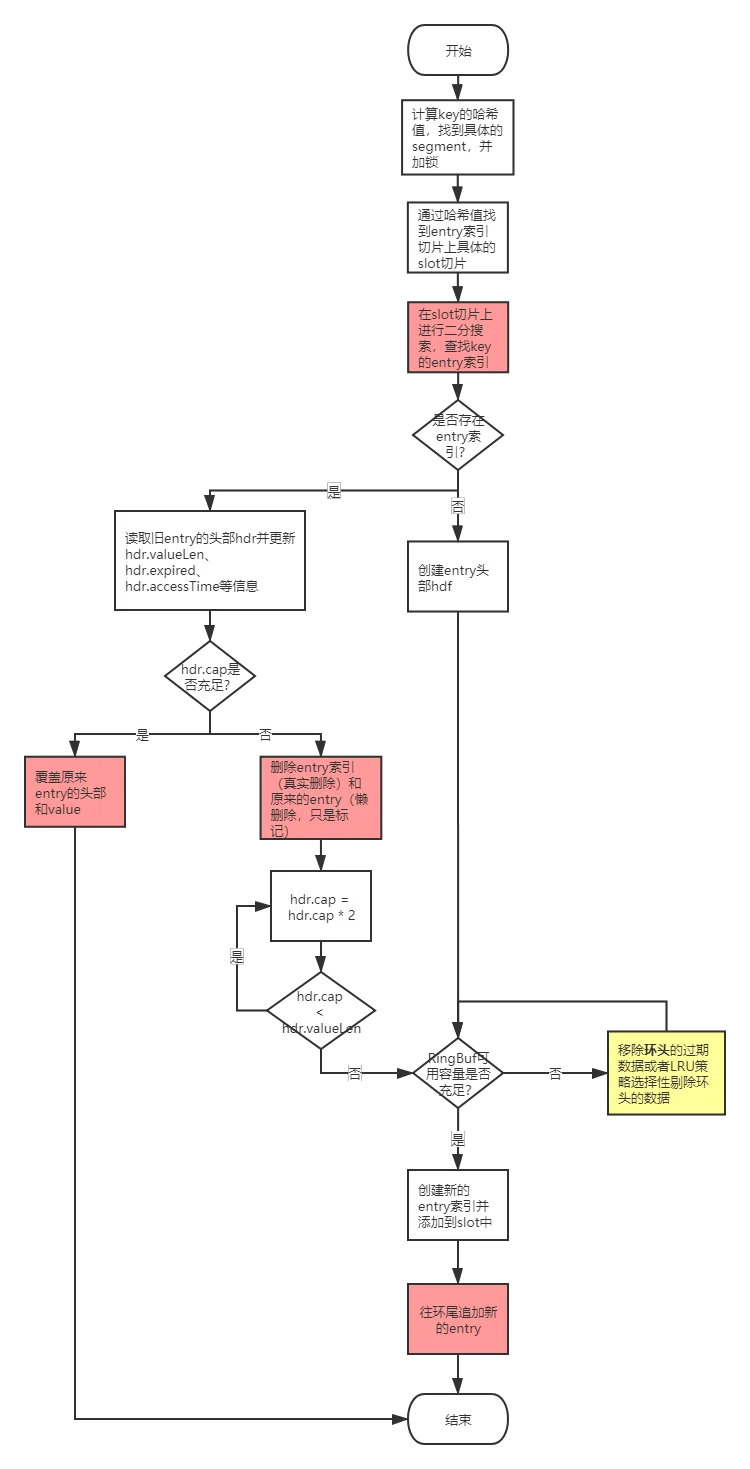
代码分析
func (seg *segment) set(key, value []byte, hashVal uint64, expireSeconds int) (err error) {
// 1. 校验key && value 大小
if len(key) > 65535 {
return ErrLargeKey
}
// 每个freecache有256个segment,因此每个entry大小不能超过 freecache内存大小的1/1024
maxKeyValLen := len(seg.rb.data)/4 - ENTRY_HDR_SIZE
if len(key)+len(value) > maxKeyValLen {
// Do not accept large entry.
return ErrLargeEntry
}
now := seg.timer.Now()
expireAt := uint32(0)
if expireSeconds > 0 {
expireAt = now + uint32(expireSeconds) // 如果set时候设置过期时间为0,永不过期
}
slotId := uint8(hashVal >> 8)
hash16 := uint16(hashVal >> 16)
slot := seg.getSlot(slotId)
// 2. 二分查找 找到entry的索引idx,如果entry不存在,返回的是第一个大于hash16(entry)的索引
idx, match := seg.lookup(slot, hash16, key)
var hdrBuf [ENTRY_HDR_SIZE]byte
// 指针强转得到header头信息
hdr := (*entryHdr)(unsafe.Pointer(&hdrBuf[0]))
// entry是否存在
if match {
// entry存在 ,拿到entry对应的slot ,更新expireAt、KeyLen等信息
// dosomething
// hdr空间是否充足
if hdr.valCap >= hdr.valLen {
// *** 空间充足 覆盖原来的entry头部和value 直接返回 ,时间复杂度O(1)
return
}
// *** 空间不足的情况下,懒删除原entry ,随后在ringbuf尾部append新entry ,时间复杂度O(1)
seg.delEntryPtr(slotId, slot, idx)
match = false
// increase capacity and limit entry len.
for hdr.valCap < hdr.valLen {
hdr.valCap *= 2
}
if hdr.valCap > uint32(maxKeyValLen-len(key)) {
hdr.valCap = uint32(maxKeyValLen - len(key))
}
} else {
// entry不存在,构建新entry
}
entryLen := ENTRY_HDR_SIZE + int64(len(key)) + int64(hdr.valCap)
// *** 数据驱逐 ,作用是腾出足够的内存,时间复杂度O(1)
slotModified := seg.evacuate(entryLen, slotId, now)
if slotModified {
slot = seg.getSlot(slotId)
idx, match = seg.lookup(slot, hash16, key)
// assert(match == false)
}
newOff := seg.rb.End()
// 更新slotData索引切片 。如果超过256个索引,加倍扩容
seg.insertEntryPtr(slotId, hash16, newOff, idx, hdr.keyLen)
// *** entry append到ringbuf尾部 时间复杂度O(1)
return
}set为什么效率高
- slot切片上的entry索引是根据hash16值有序排列的,采用二分查找算法进行定位,时间复杂度O(log(len(slotData)))
- 对于key不存在的情况下(找不到entry索引)。
ringbufentry- 对于已经存在的key(找到entry索引)。
- 如果原来给entry的value预留的容量充足的话,则直接更新原来entry的头部和value,时间复杂度为O(1)。
- 如果原来给entry的value预留的容量不足的话,freecache为了避免移动底层数组数据,不直接对原来的entry进行扩容,而是将原来的entry标记为删除(懒删除),然后在环形缓冲区ringBuf的环尾追加新的entry,时间复杂度为O(1)。
evacuate
evacuateset流程图
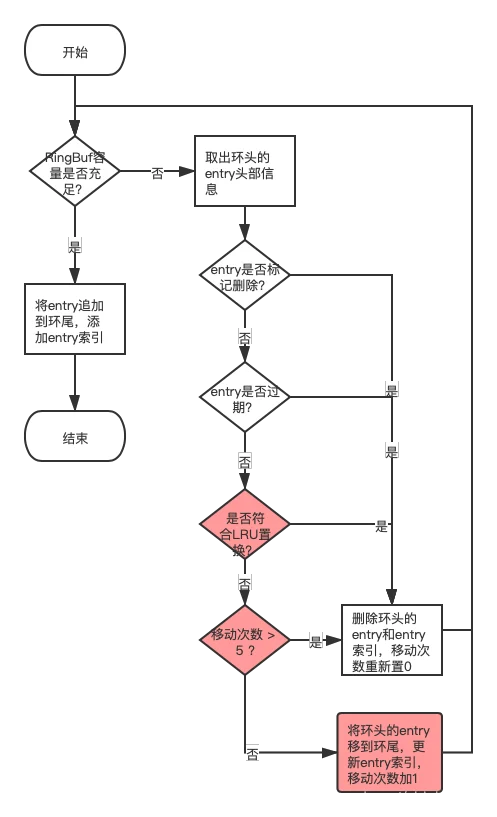
源码分析
func (seg *segment) evacuate(entryLen int64, slotId uint8, now uint32) (slotModified bool) {
// RingBuf容量不足的情况
for seg.vacuumLen < entryLen {
oldOff := seg.rb.End() + seg.vacuumLen - seg.rb.Size()
seg.rb.ReadAt(oldHdrBuf[:], oldOff)
oldHdr := (*entryHdr)(unsafe.Pointer(&oldHdrBuf[0]))
oldEntryLen := ENTRY_HDR_SIZE + int64(oldHdr.keyLen) + int64(oldHdr.valCap)
// entry是否被标记删除
if oldHdr.deleted {
// 移动次数记为0
consecutiveEvacuate = 0
atomic.AddInt64(&seg.totalTime, -int64(oldHdr.accessTime))
atomic.AddInt64(&seg.totalCount, -1)
seg.vacuumLen += oldEntryLen
continue
}
// entry是否过期
expired := oldHdr.expireAt != 0 && oldHdr.expireAt < now
// LRU entry最近使用情况
leastRecentUsed := int64(oldHdr.accessTime)*atomic.LoadInt64(&seg.totalCount) <= atomic.LoadInt64(&seg.totalTime)
if expired || leastRecentUsed || consecutiveEvacuate > 5 {
// entry如果已经过期了,或者满足置换条件,则删除掉entry
} else {
// 如果不满足置换条件,则将entry从环头调换到环尾
newOff := seg.rb.Evacuate(oldOff, int(oldEntryLen))
// 更新entry的索引
seg.updateEntryPtr(oldHdr.slotId, oldHdr.hash16, oldOff, newOff)
}
}
return
}总结
slotDataslotData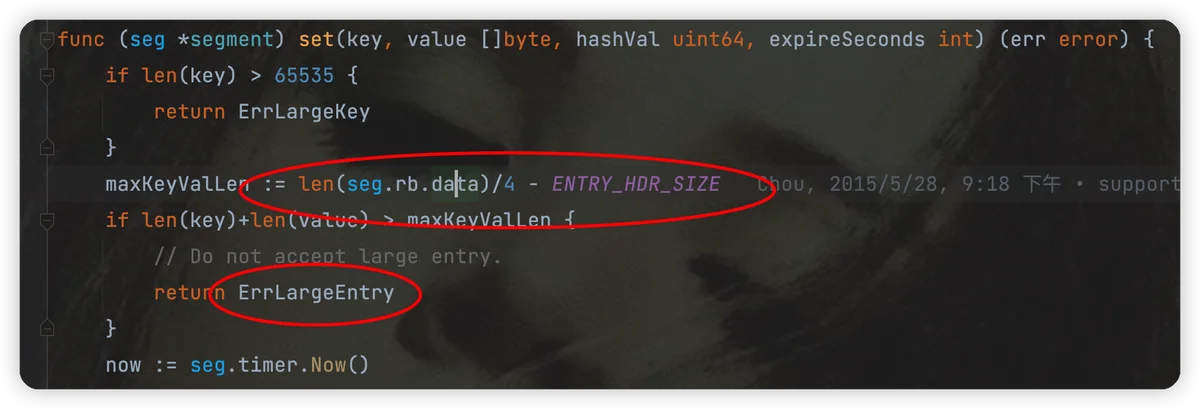
介绍
cacheShardcacheShardmapkeyvaluekeyfnv64avaluebyte索引与数据分离map5根据各自的长度申请bigCacheheaderbinary[]bytemap结构
type BigCache struct {
shards []*cacheShard // 缓存分片数据
lifeWindow uint64
clock clock // 时间计算函数
hash Hasher // hash 函数,在计算Key的Hash使用
config Config // Cache 配置
shardMask uint64 // 寻找分片位置时使用
maxShardSize uint32
close chan struct{}
}
type cacheShard struct {
hashmap map[uint64]uint32 // 索引列表,对应KEY在entries中的位置
entries queue.BytesQueue // 实际数据存储
lock sync.RWMutex
entryBuffer []byte
onRemove onRemoveCallback
isVerbose bool
logger Logger
clock clock
lifeWindow uint64
stats Stats
}
// 存储数据的字节队列
type BytesQueue struct {
array []byte // 一个字节数组,实际数据存储的地方
capacity int // 容量
maxCapacity int // 最大容量
head int
tail int // 下次可以插入 item 的位置
count int // 当前插入的 item 数量
rightMargin int
headerBuffer []byte // 插入前做临时 buffer 所用(slice-copy)
verbose bool // 打印 log 开关
initialCapacity int // BytesQueue 创建时,array 的初始容量
}Get
bigcache的Get十分简单
cacheShardcacheShard校验传入的key和entry中的key- 传入的key和entry中的key不同,返回错误
- 传入的key和entry中的key相同,从entry中读value ,返回值
func (c *BigCache) Get(key string) ([]byte, error) {
hashedKey := c.hash.Sum64(key)
shard := c.getShard(hashedKey)
return shard.get(key, hashedKey)
}
func (s *cacheShard) get(key string, hashedKey uint64) ([]byte, error) {
wrappedEntry, err := s.getWrappedEntry(hashedKey)
if err != nil { return nil, err
}
// 从entry中读key ,校验entry中的key和传入的key是否相同
if entryKey := readKeyFromEntry(wrappedEntry); key != entryKey {
s.lock.RUnlock()
return nil, ErrEntryNotFound
}
// entry中读value
entry := readEntry(wrappedEntry)
return entry, nil
}Set
整体来说bigcache的赋值操作也不复杂 。
bytesQueue新entrybytesQueue队尾- 如果内存足够,entry直接放入队尾
- 如果内存不够,尝试删除队头的entry,并再次尝试步骤 4
func (s *cacheShard) set(key string, hashedKey uint64, entry []byte) error {
currentTimestamp := uint64(s.clock.Epoch())
s.lock.Lock()
// 冲突检查,将之前的key对应value置为空
if previousIndex := s.hashmap[hashedKey]; previousIndex != 0 {
if previousEntry, err := s.entries.Get(int(previousIndex)); err == nil {
resetKeyFromEntry(previousEntry)
delete(s.hashmap, hashedKey)
}
}
// 每次插入新数据时,bigCache 都会获取 BytesQueue 头部数据,
if oldestEntry, err := s.entries.Peek(); err == nil {
// 然后判断数据是否过期,如果过期则删除
s.onEvict(oldestEntry, currentTimestamp, s.removeOldestEntry)
}
// 设置缓存的值,使用 wrapEntry 对用户传入的 key 和 value 进行序列化
w := wrapEntry(currentTimestamp, hashedKey, key, entry, &s.entryBuffer)
// 设置缓存的值,使用 wrapEntry 对用户传入的 key 和 value 进行序列化
for {
// Push 会判断是不是有足够的空间,没有,则返回 err。如果有,则将entry复制到queue队尾
if index, err := s.entries.Push(w); err == nil {
s.hashmap[hashedKey] = uint32(index)
s.lock.Unlock()
return nil
}
// 没有足够内存空间,尝试删除bytesQueue头节点的数据
if s.removeOldestEntry(NoSpace) != nil {
s.lock.Unlock()
return fmt.Errorf("entry is bigger than max shard size")
}
}
}- set的entry内存是在push方法中分配的
delete
并没有实际回收内存func (s *cacheShard) del(hashedKey uint64) error {
s.lock.RLock()
{
itemIndex := s.hashmap[hashedKey]
// 检查index 是否是合法的 .如果不合法,直接返回
if err := s.entries.CheckGet(int(itemIndex)); err != nil {
return err
}
}
{
itemIndex := s.hashmap[hashedKey]
wrappedEntry, err := s.entries.Get(int(itemIndex))
if err != nil {
return err
}
// 删除索引 ,同时将value置空 ,没有回收内存
delete(s.hashmap, hashedKey)
// 删除时的回调函数
s.onRemove(wrappedEntry, Deleted)
if s.statsEnabled {
delete(s.hashmapStats, hashedKey)
}
resetKeyFromEntry(wrappedEntry)
}
return nil
}缓存过期
bigCache 可以为插入的数据设置过期时间,但是缺点是所有数据的过期时间都是一样的。
bigCache 中自动删除数据有两种场景:
CleanWindowgoroutine后台定时批量func newBigCache(config Config, clock clock) (*BigCache, error) {
// ***
if config.CleanWindow > 0 {
go func() {
ticker := time.NewTicker(config.CleanWindow)
defer ticker.Stop()
for {
select {
case t := <-ticker.C:
cache.cleanUp(uint64(t.Unix()))
case <-cache.close:
return
}
}
}()
}
return cache, nil
}
func (c *BigCache) cleanUp(currentTimestamp uint64) {
for _, shard := range c.shards {
shard.cleanUp(currentTimestamp)
}
}
func (s *cacheShard) cleanUp(currentTimestamp uint64) {
s.lock.Lock()
for {
if oldestEntry, err := s.entries.Peek(); err != nil {
break
} else if evicted := s.onEvict(oldestEntry, currentTimestamp, s.removeOldestEntry); !evicted {
break
}
}
s.lock.Unlock()
}
func (s *cacheShard) onEvict(oldestEntry []byte, currentTimestamp uint64, evict func(reason RemoveReason) error) bool {
oldestTimestamp := readTimestampFromEntry(oldestEntry)
if currentTimestamp-oldestTimestamp > s.lifeWindow {
evict(Expired)
return true
}
return false
}不足
内存空洞bytesQueue内存不够用bigcache和freecache的比较
slotDatagithub.com/coocood/freecache v1.1.0
github.com/allegro/bigcache/v2 v2.1.3
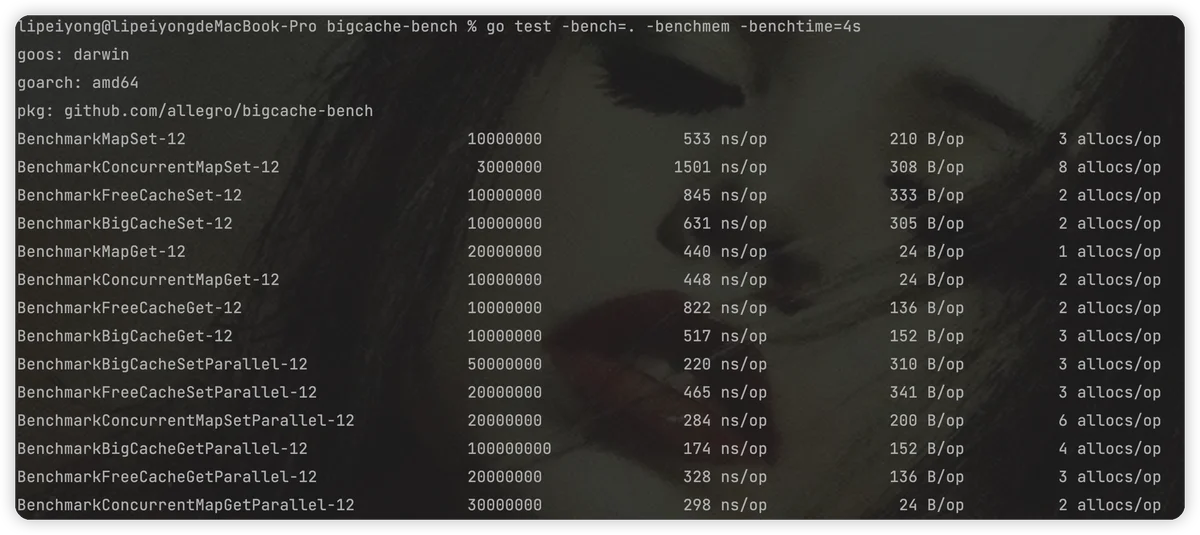
github.com/allegro/bigcache/v3 v3.0.2\
github.com/coocood/freecache v1.2.1
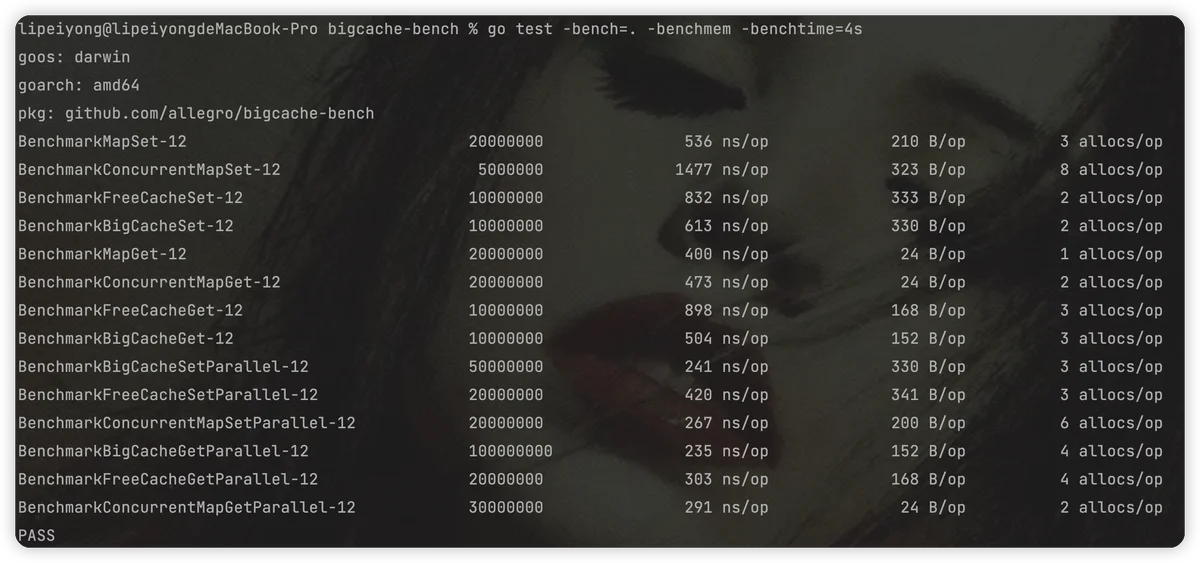
性能对比
bigCachefreeCachefreecachebigcache- 分片+分段锁
- GC优化: uint 来做gc优化
- 底层数据结构的选型(Map 或者Slice实现O(1)的查找 )
- 数据的高效定位(hash + 连续内存地址)
- 数据淘汰策略(FIFO ? LRU ?LFU ? && LRU +LFU 结合 && 是否结合懒删除)
- 数据存储([]byte + ringbuf)
- 是否需要支持内存扩容 && 内存扩容的机制(时机) && 过程(快 + 稳)
提升系统复杂度数据一致性会更难保证意义解决了什么实际问题随之引入的问题