


![]()

golang实现的爬虫框架,使用者只需关心页面规则,提供web管理界面。基于colly开发。
当前状态
Alpha, 核心功能可用, 但功能还不完善。接口随时可能改变。
限制:
- 目前只能单机运行, 不能实现真正的分布式运行。 但大部分情况下, 如果你不是需要同时爬取成百上千个站点, 其实并不需要真正的分布式, 只需要一个代理IP池即可。
- 不能用于大文件下载
特性
- 使用者只需编写页面规则代码
- 提供WEB管理界面 (包括任务管理、系统管理等)
- 任务级别的可配置异步并发控制(请求延迟, 请求并发度)
- 自动cookie和session处理
- 支持各种导出类型(mysql,csv等)
- 支持定时任务(兼容crontab格式)
- 支持任务级别的可配置代理IP池
- Robots.txt 支持
依赖
MySQL
gospider可以配置一下相关环境变量: GOSPIDER_DB_HOST、GOSPIDER_DB_PORT、GOSPIDER_DB_USER、GOSPIDER_DB_PASSWORD、GOSPIDER_DB_NAME、GOSPIDER_WEB_IP、GOSPIDER_WEB_PORT
本地开发环境: 安装
使用方式
_example以baidunews(百度新闻)为例简单说明爬虫规则如何编写:
_example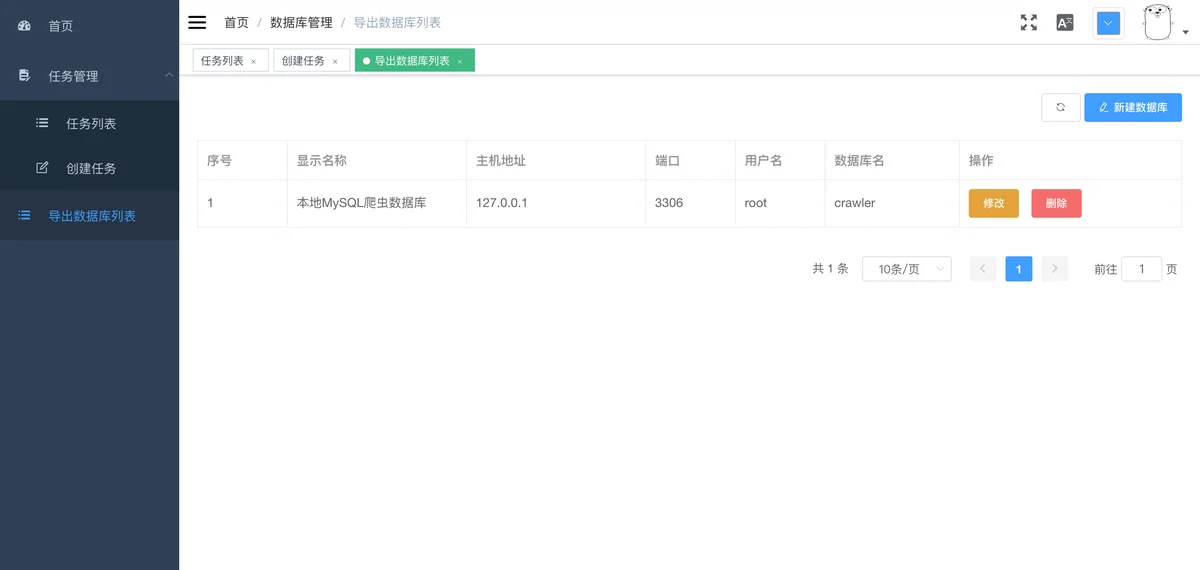
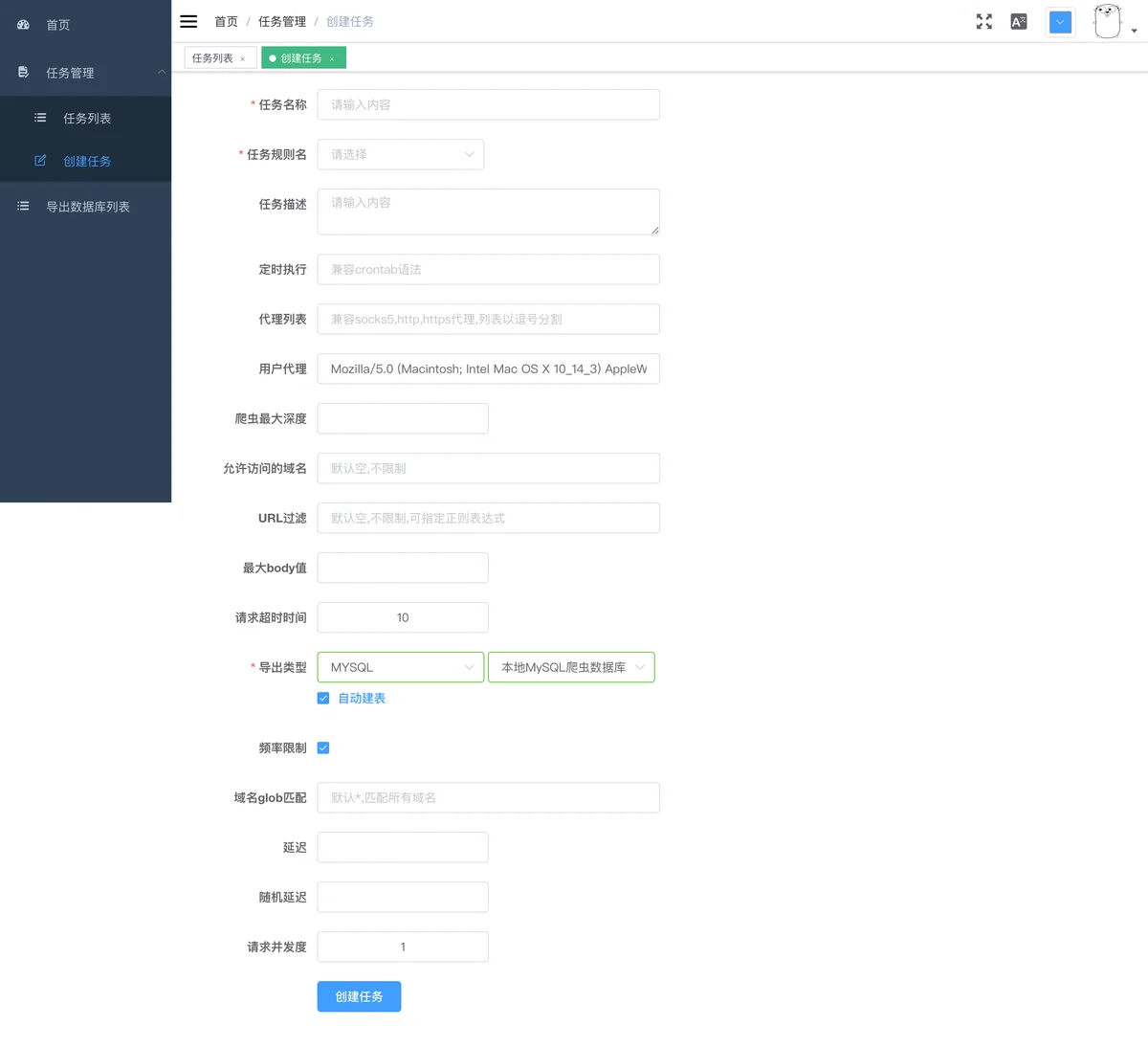
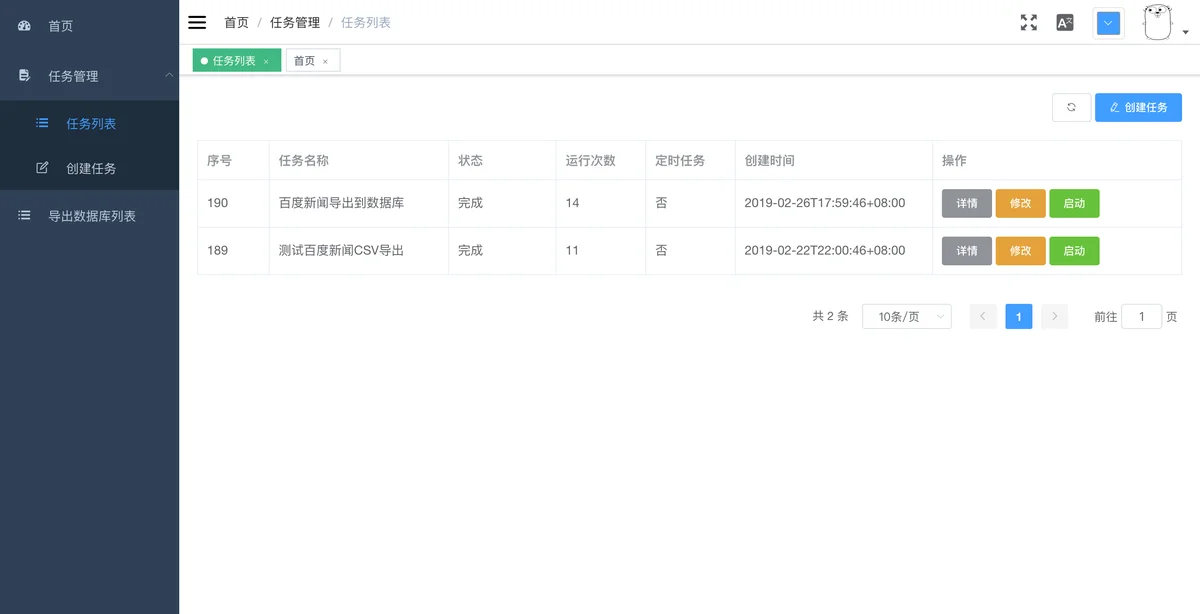
感谢
License
