
GC 触发条件:
1> 当前内存分配达到一定比例则触发
2> 2 分钟没有触发过 GC 则触发 GC
3> 手动触发,调用 runtime.GC()
阈值是由一个gcpercent的变量控制的,当新分配的内存占已在使用中的内存的比例超过gcprecent时就会触发。 比如一次回收完毕后,内存的使用量为5M,那么下次回收的时机则是内存分配达到10M的时候。也就是说,并不是内存分配越多,垃圾回收频率越高。 如果一直达不到内存大小的阈值呢?这个时候GC就会被定时时间触发,比如一直达不到10M,那就定时(默认2min触发一次)触发一次GC保证资源的回收。
GO :垃圾回收机制 (GC: Garbage Collection)
阻塞状态是go调度的一个待唤醒的状态,是不能被gc的。
go V1.3之前 采用的gc是标记回收法(mark&sweep):
从根变量来时遍历所有被引用对象,标记之后进行清除操作,对未标记对象进行回收
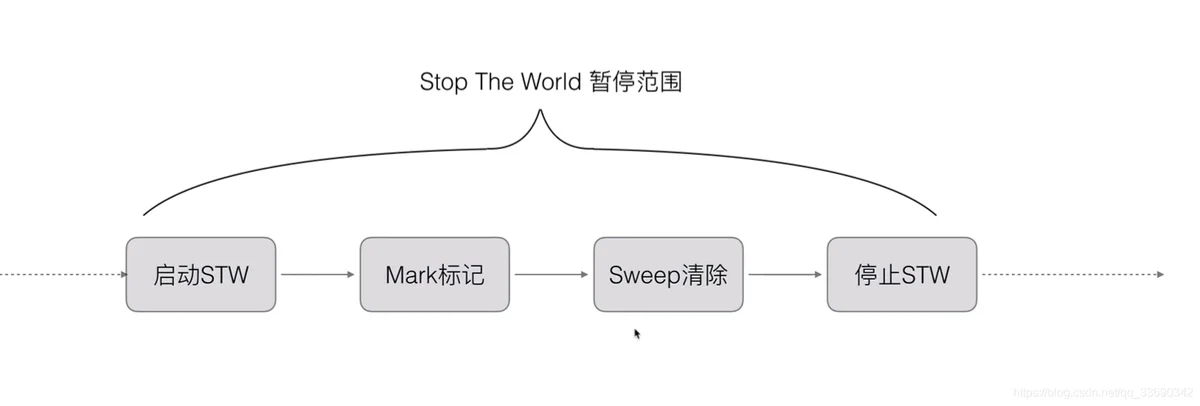
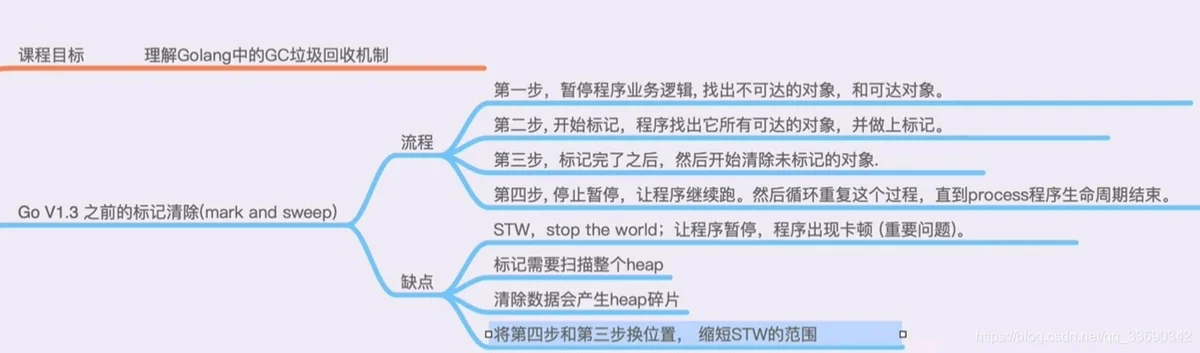
那么如何从代码方面优化以减少gc导致的STW的时间?
-
减少对象的分配
-
使用sync.Pool
GO V1.5 采用三色标记法:
三色标记最大的好处是可以异步执行,从而可以以中断时间极少的代价或者完全没有中断来进行整个 GC。
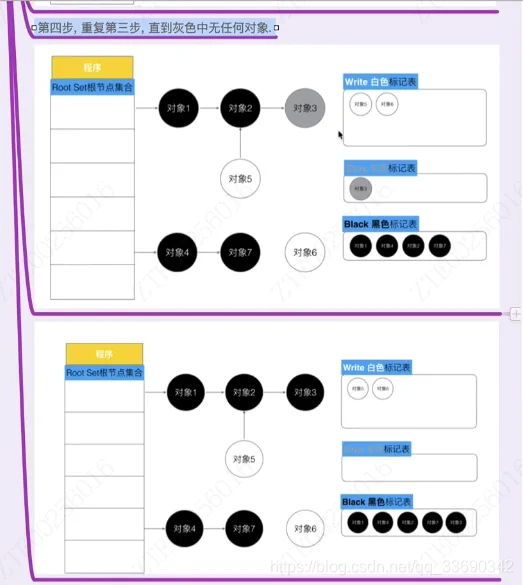
三色标记法很简单[2]。首先将对象用三种颜色表示,分别是白色、灰色和黑色。最开始所有对象都是白色的,然后把其中全局变量和函数栈里的对象置为灰色。第二步把灰色的对象全部置为黑色,然后把原先灰色对象指向的变量都置为灰色,以此类推。等发现没有对象可以被置为灰色时,所有的白色变量就一定是需要被清理的垃圾了。
三色标记法因为多了一个白色的状态来存放不确定的对象,所以可以异步地执行。
除了异步标记的优点,三色标记法掌握了更多当前内存的信息,因此可以更加精确地按需调度,而不用像标记清扫法那样只能定时执行。
标记过程中是不需要 STW ,它与程序是并发执行的,这就大大缩短了 STW 的时间.
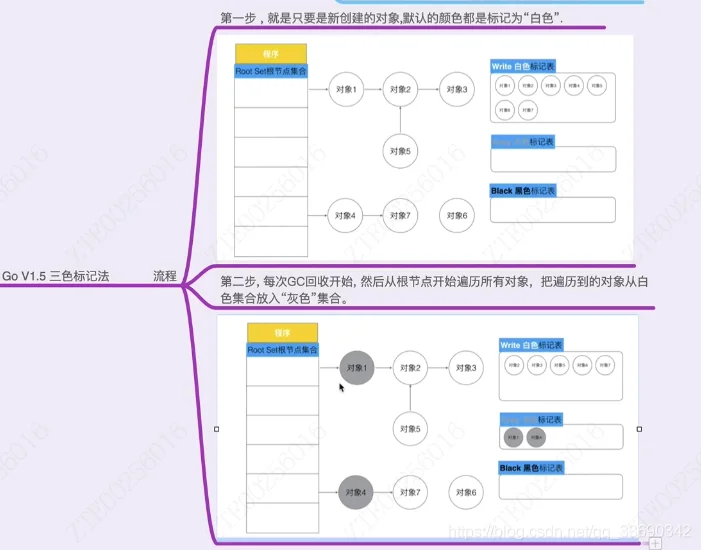
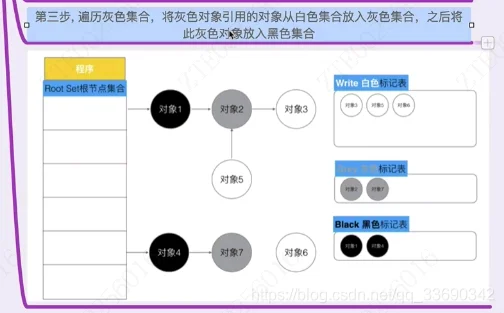
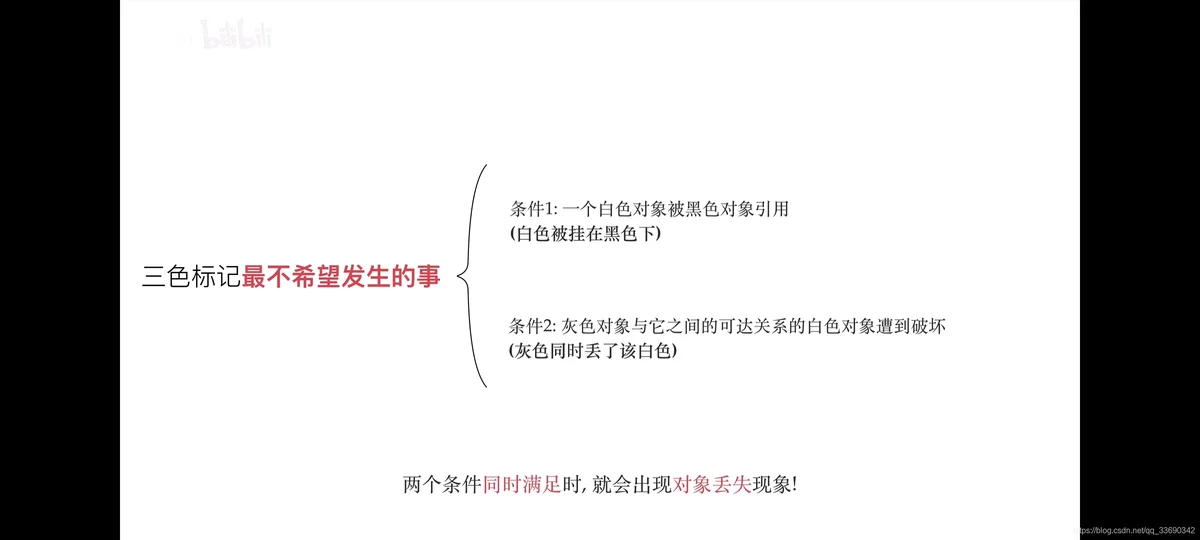
强三色不变式:强制性的不允许黑色对象引用白色对象。(破坏条件1)
弱三色不变式:黑色可以引用白色对象,白色对象存在其他灰色对象对它的引用,或者可达它的链路上游存在灰色对象。(破坏条件2)
屏障机制:
插入屏障:对象被引用时触发的机制
删除屏障:对象被删除时,触发的机制
插入写屏障:
当标记和程序是并发执行的,这就会造成一个问题. 在标记过程中,有新的引用产生,可能会导致误清扫. 清扫开始前,标记为黑色的对象引用了一个新申请的对象,它肯定是白色的,而黑色对象不会被再次扫描,那么这个白色对象无法被扫描变成灰色、黑色,它就会最终被清扫,而实际它不应该被清扫. 这就需要用到屏障技术,golang 采用了写屏障,作用就是为了避免这类误清扫问题. 写屏障即在内存写操作前,维护一个约束,从而确保清扫开始前,黑色的对象不能引用白色对象.
垃圾回收优化:
1、写屏障可以让goroutine和GC同时运行。GC过程中新分配的内存会被立即标记,用的正是写屏障技术,即GC过程中分配的内存不会再本轮GC中回收。
2、为了防止内存分配过快,在GC执行的过程中,如果goroutine需要分配内存,那么该goroutine会参与一部分GC的工作,帮助GC做一部分工作。
知道golang的内存逃逸吗?什么情况下会发生内存逃逸?
golang程序变量栈上逃逸堆上分配逃逸分析是编译器在静态编译的时候,分析对象的生命周期及引用情况来决定对象内存分配到堆上还是栈上,由于栈内存分配较堆快且栈内存回收较快(无需gc),编译器以此来优化程序性能。在函数中申请一个新的对象:
如果分配在栈中,则函数执行结束后可自动将内存回收
如果分配在堆中,则函数执行结束后可交给GC进行处理。
逃逸策略:
如果函数外部没有引用,则优先放到栈中;
如果函数外部存在引用,则必定放到堆中。
注意:仅在函数内部使用的变量,也有可能放到堆中,比如内存过大超过栈的存储能力。
逃逸场景:
1、指针逃逸
2、栈空间不足逃逸
3、动态类型逃逸
4、闭包引用对象逃逸
总结:
- 栈上分配内存比在堆上分配内存有更高的效率
- 栈上分配的内存不需要GC处理
- 堆上分配的内存使用完毕会交给GC处理、
- 逃逸分析的目的是决定分配地址是栈还是堆
- 逃逸分析在编译阶段进行
思考一下这个问题:两数传递指针真的比传值的效率高吗?
我们知道传递指针可以减少底层值的复制,可以提高效率,但是如果复制的数据量小,由于指针传递会产生逃逸,则可能会使用堆,也可能增加 GC 的负担,所以传递指针不一定是高效的。
能引起变量逃逸到堆上的典型情况:
- 函数返回局部变量的指针 局部变量原本应该在栈中分配,在栈中回收。但是由于返回时被外部引用,因此其生命周期大于栈,则溢出。
- 发送指针或带有指针的值到 channel 中。 在编译时,是没有办法知道哪个 goroutine 会在 channel 上接收数据。所以编译器没法知道变量什么时候才会被释放。
- 在一个切片上存储指针或带指针的值。 一个典型的例子就是 []*string 。这会导致切片的内容逃逸。尽管其后面的数组可能是在栈上分配的,但其引用的值一定是在堆上。
- slice 的背后数组被重新分配了,因为 append 时可能会超出其容量( cap )。 slice 初始化的地方在编译时是可以知道的,它最开始会在栈上分配。如果切片背后的存储要基于运行时的数据进行扩充,就会在堆上分配。
- 在 interface 类型上调用方法。 在 interface 类型上调用方法都是动态调度的 —— 方法的真正实现只能在运行时知道。想像一个 io.Reader 类型的变量 r , 调用 r.Read(b) 会使得 r 的值和切片b 的背后存储都逃逸掉,所以会在堆上分配。
- 栈空间不足逃逸 当对象大小超过的栈帧大小时(详见go内存分配),变量对象发生逃逸被分配到堆上。
-
当对象不确定大小或者被作为不确定大小的参数时发生逃逸。
-
在给切片或者map赋值对象指针(与对象共享内存地址时),对象会逃逸到堆上。但赋值对象值或者返回对象值切片是不会发生逃逸的。