
上一章中对于编译原理的说明如下:
接下来我们来对golang的数据结构进行说明,主要内容有:
- 1 数组
- 2 切片
- 3 哈希表
- 4 字符串
字符串是 Go 语言中最常用的基础数据类型之一,虽然字符串往往被看做一个整体,但是实际上字符串是一片连续的内存空间,我们也可以将它理解成一个由字符组成的数组,在这一节中就会详细介绍字符串的实现原理、相关转换过程以及常见操作的实现。
stringchar[]"hello"

图 3-18 内存中的字符串
SRODATAhelloSRODATA$ cat main.go
package main
func main() {
str := "hello"
println([]byte(str))
}
$ GOOS=linux GOARCH=amd64 go tool compile -S main.go
...
go.string."hello" SRODATA dupok size=5
0x0000 68 65 6c 6c 6f hello
...[]bytestringstring3.4.1 数据结构
StringHeaderstringHeaderDataunsafe.Pointertype StringHeader struct {
Data uintptr
Len int
}我们会经常会说字符串是一个只读的切片类型,这是因为切片在 Go 语言的运行时表示与字符串高度相似:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}Cap3.4.2 解析过程
字符串的解析一定是解析器在词法分析时就完成的,词法分析阶段会对源文件中的字符串进行切片和分组,将原有无意义的字符流转换成 Token 序列,在 Go 语言中,有两种字面量方式可以声明一个字符串,一种是使用双引号,另一种是使用反引号:
str1 := "this is a string"
str2 := `this is another
string`\"json := `{"author": "draven", "tags": ["golang"]}`scannerfunc (s *scanner) stdString() {
s.startLit()
for {
r := s.getr()
if r == '"' {
break
}
if r == '\\' {
s.escape('"')
continue
}
if r == '\n' {
s.ungetr()
s.error("newline in string")
break
}
if r < 0 {
s.errh(s.line, s.col, "string not terminated")
break
}
}
s.nlsemi = true
s.lit = string(s.stopLit())
s.kind = StringLit
s.tok = _Literal
}从这个方法的实现我们能分析出 Go 语言处理标准字符串的逻辑:
\escape\nstr := "start
end"使用反引号声明的原始字符串的解析规则就非常简单了, 会将非反引号的所有字符都划分到当前字符串的范围中,所以我们可以使用它来支持复杂的多行字符串:
func (s *scanner) rawString() {
s.startLit()
for {
r := s.getr()
if r == '`' {
break
}
if r < 0 {
s.errh(s.line, s.col, "string not terminated")
break
}
}
s.nlsemi = true
s.lit = string(s.stopLit())
s.kind = StringLit
s.tok = _Literal
}StringLitfunc (p *noder) basicLit(lit *syntax.BasicLit) Val {
switch s := lit.Value; lit.Kind {
case syntax.StringLit:
if len(s) > 0 && s[0] == '`' {
s = strings.Replace(s, "\r", "", -1)
}
u, _ := strconv.Unquote(s)
return Val{U: u}
}
}importstrconv.Unquote3.4.3 拼接
+OADDOADDSTRfunc walkexpr(n *Node, init *Nodes) *Node {
switch n.Op {
...
case OADDSTR:
n = addstr(n, init)
}
}concatstring{2,3,4,5}func addstr(n *Node, init *Nodes) *Node {
c := n.List.Len()
buf := nodnil()
args := []*Node{buf}
for _, n2 := range n.List.Slice() {
args = append(args, conv(n2, types.Types[TSTRING]))
}
var fn string
if c <= 5 {
fn = fmt.Sprintf("concatstring%d", c)
} else {
fn = "concatstrings"
t := types.NewSlice(types.Types[TSTRING])
slice := nod(OCOMPLIT, nil, typenod(t))
slice.List.Set(args[1:])
args = []*Node{buf, slice}
}
cat := syslook(fn)
r := nod(OCALL, cat, nil)
r.List.Set(args)
...
return r
}concatstring{2,3,4,5}func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
if n == 0 {
continue
}
l += n
count++
idx = i
}
if count == 0 {
return ""
}
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
s, b := rawstringtmp(buf, l)
for _, x := range a {
copy(b, x)
b = b[len(x):]
}
return s
}如果非空字符串的数量为 1 并且当前的字符串不在栈上就可以直接返回该字符串,不需要进行额外的任何操作。

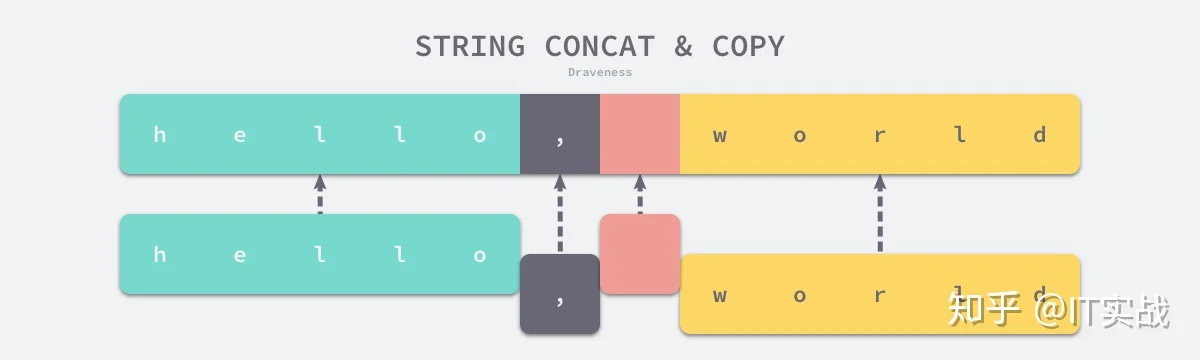
图 3-19 字符串的拼接和拷贝
copy3.4.4 类型转换
string[]bytestring(bytes)func slicebytetostring(buf *tmpBuf, b []byte) (str string) {
l := len(b)
if l == 0 {
return ""
}
if l == 1 {
stringStructOf(&str).str = unsafe.Pointer(&staticbytes[b[0]])
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
if buf != nil && len(b) <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(len(b)), nil, false)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = len(b)
memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b)))
return
}stringStructstrlenmemmove[]byte[]bytefunc stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}[]bytecopy[]byte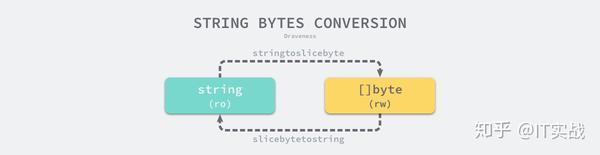
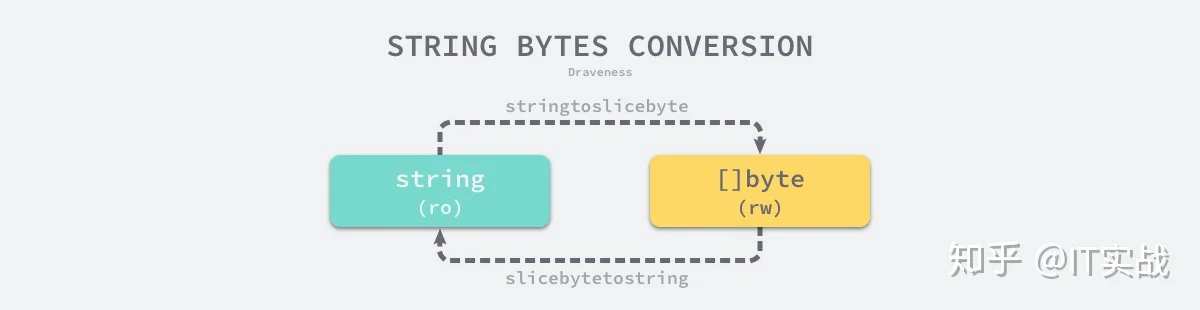
图 3-20 字符串和字节数组的转换
[]byte[]byte[]byte3.4.5 小结
[]byte全套教程点击下方链接直达: