
本文主要是记录一次错误的golang信号量使用方式,导致了cpu单核被占满的问题,希望大家引以为戒。
示例
func test() {
for {
c := make(chan os.Signal)
signal.Notify(c)
s := <-c
if s != syscall.SIGKILL {
continue
}
framework.GetLogger().ILog("recv signal: %s", s)
break
}
framework.GetLogger().ILog("service stop")
}
如上代码,在程序中监听了所有信号量,当监听到的不是SIGKILL信号时,就continue继续开启一次新的监听。乍一看似乎没什么问题,并且这段代码一开始部署的时候也是正常跑着的,但是在跑过10多天之后神奇的事情就发生了,该程序cpu吃满了cpu单核。导致cpu单核占满的原因,我们很容易联想到代码中有死循环。
原因分析
在开启pprof监控之后,成功抓到了cpu耗用点,如下图:
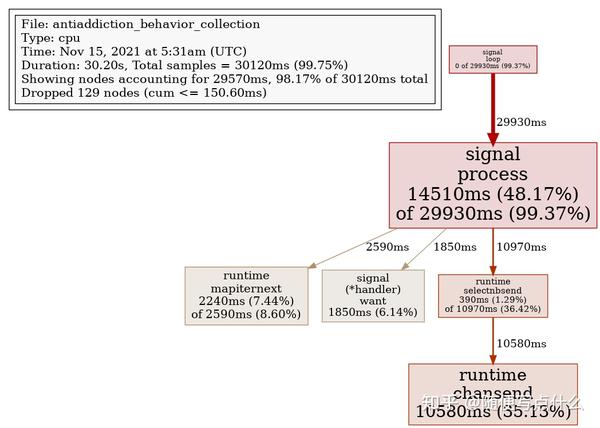
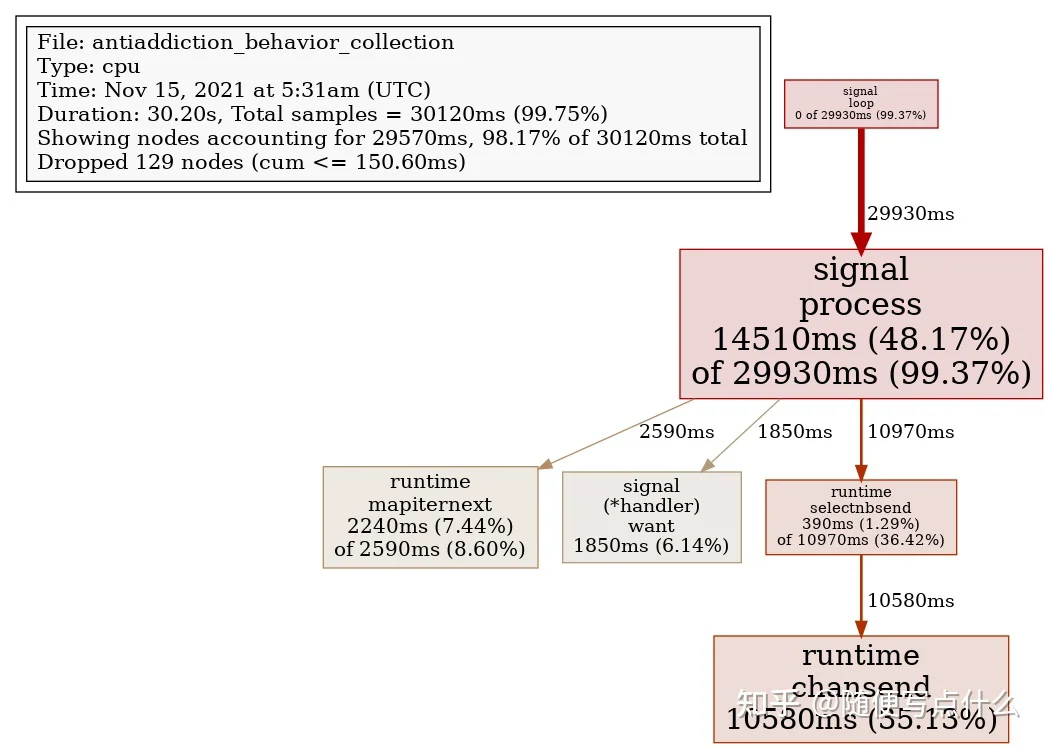
可以看到是在信号量loop中占用了特别多的cpu,来看看这里的源码:
func process(sig os.Signal) {
n := signum(sig)
if n < 0 {
return
}
handlers.Lock()
defer handlers.Unlock()
for c, h := range handlers.m {
if h.want(n) {
// send but do not block for it
select {
case c <- sig:
default:
}
}
}
// Avoid the race mentioned in Stop.
for _, d := range handlers.stopping {
if d.h.want(n) {
select {
case d.c <- sig:
default:
}
}
}
}
源码中将信号量分发到handlers.m chan中是不阻塞的,说明有非常多的用于接收信号量的notify被注册进来了,再结合代码逻辑,发现每收到一次信号量,就新注册一个chan进来。这里就有疑问了:为什么在进程正常运行的过程中,操作系统会发送如此多的信号量进来,以至于注册的队列越来越多,导致信号量分发的for循环都空转吃满了cpu呢?
SIGURG (urgent I/O condition)
runtime/proc.goconst forcePreemptNS = 10 * 1000 * 1000
func retake(now int64) uint32 {
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(_p_)
// In case of syscall, preemptone() doesn't
// work, because there is no M wired to P.
sysretake = true
}
}
}
当我们进程在运行过程中,其实偶尔也会有概率出现协程占用超10ms的情况,随着调度抢占的信号收到的次数变多,信号量分发的的压力就会越来越大,而信号量分发本身也在自己的协程中进行,这样就会越来越容易导致抢占信号的触发,从而陷入抢占协程的雪崩中,导致单核cpu被吃满。
正确姿势
func test() {
c := make(chan os.Signal)
signal.Notify(c, syscall.SIGKILL)
for {
s := <-c
if s != syscall.SIGKILL {
framework.GetLogger().WLog("recv signal: %s", s)
continue
}
framework.GetLogger().ILog("recv signal: %s", s)
break
}
framework.GetLogger().ILog("service stop")
}
正确的做法是:我们应该只关心我们需要的信号量,并且只创建一次监听队列。