
Snowflake 在行动


Snowflake 算法的背景当然是 Twitter 高并发环境下对唯一 ID 生成的需求。
由于 Twitter 的内部技术,Snowflake 算法可以在今天得到广泛传播和广泛使用,因为它具有几个特点。
- 可以满足高并发分布式系统环境下的非重复ID。
- 生产效率高。
- 基于时间戳,保证有序增量。
- 不依赖第三方库或中间件。
- 生成的 id 是连续且唯一的。
Snowflake 算法原理
我们来看一张图片。
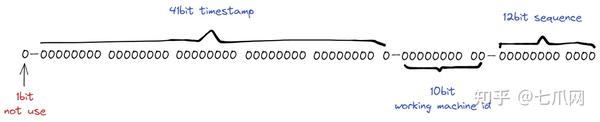
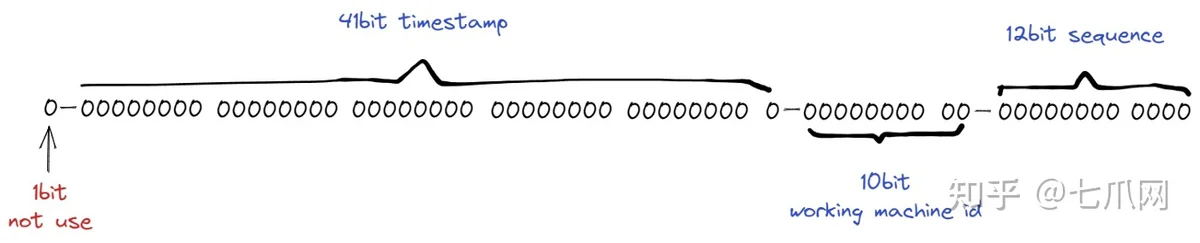
我们从图中可以看出,SnowFlake ID 结构是一个 64bit 的 int 数据。
- 1BT。
在二进制中,最高位是1。因为我们使用的id应该是整数,有负数,所以这里最高位应该是0。
- 41bit:时间戳。
41 位可以表示 ²⁴¹-1 个数字。如果仅用于表示正整数,则可表示的取值范围为 0 — (²⁴¹ -1)。之所以在这里减一,是因为取值范围是从0开始计数,而不是从1开始计数。
这里的单位是毫秒,所以 41 位可以表示 ²⁴¹-1 毫秒,转换为单位年为 (²⁴¹-1)/(1000 * 60 * 60 * 24 * 365) = 69。
- 10bit:工作机器ID。
这里是用来记录worker机器的id。 ²¹⁰=1024表示当前规则允许的最大分布式节点数为1024个节点。这包括五位数的 WorkerID 和五位数的数据中心,在这里可能无法区分,但下面的代码进行了区分。
- 12bit:序列号。
用于记录同一毫秒内产生的不同id。 12bit可以表示的最大正整数是²¹²-1=4095,即4095个数字0,1,2,3,…4094。这可以用来表示同一台机器是在同一时间戳(毫秒)内生成的。 4095 个 ID 序列号。
原理如上。没有困难。让我们看看代码是如何实现的。
Go 实现了 {Snowflake 算法
1.定义基本常数
2.定义工作节点
因为这是分布式环境中使用的ID生成算法,所以如果要生成多个worker,就必须抽象出节点参数。
代码说明:
- mu sync.Mutex:添加互斥锁,保证并发安全。
- LastStamp int64:记录最后一次ID生成的时间戳。
- WorkerID int64:worker节点的ID,对上图中的5bit WorkerID有含义。
- DataCenterID int64:节点的数据中心ID。
- sequence int64:当前毫秒内已经生成的id序列号(从0开始累加)一毫秒内最多生成4096个id
3.创建worker对象
4.生成ID
代码有点长,我依次解释一下:
- getMilliSeconds():封装的获取当前毫秒值的方法。
- func(w *Worker) NextID() (uint64, 错误)
这段代码的内容没有什么特别的作用,主要是为了解耦。唯一需要注意的是锁定和释放步骤。
这里的实现分为几个步骤:
- 获取当前时间戳并进行判断。确保当前时间戳值大于上一次 ID 生成的时间戳。否则,会有重复。
- 如果相等,首先获取当前毫秒生成的id序列号。你可能不明白这里。它相当于 if w.sequence++ > maxSequence 。
- 如果当前毫秒生成的id序列号溢出,则必须等待下一毫秒。如果你不等待,它会导致很多重复。
- 我们在else中设置w.sequence为0,这里解释一下,如果当前时间与worker节点上一次生成ID不一致,需要重新设置worker节点生成ID的序号。
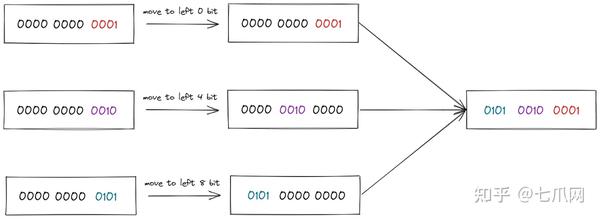
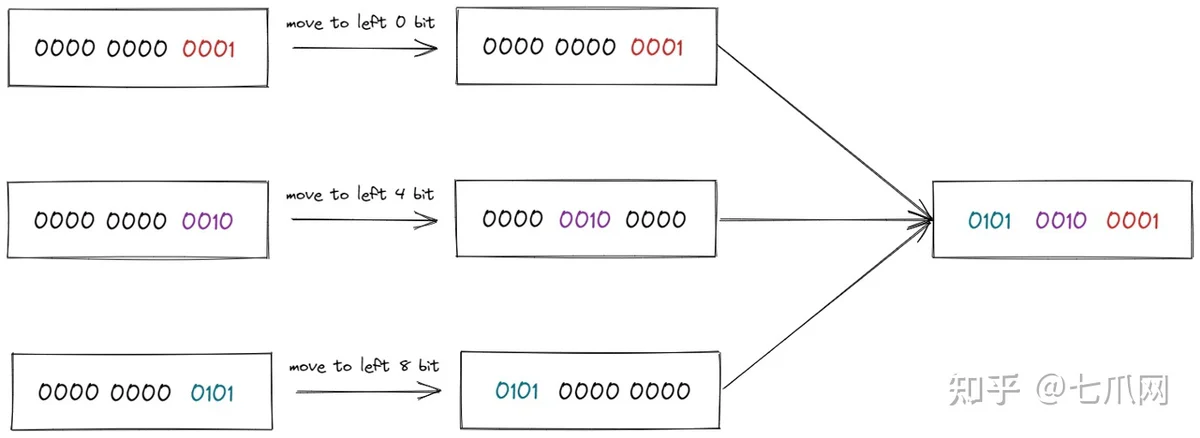
- 更重要的最后一步使用 OR 操作。这里的目的是返回每个部分的位,并通过按位或运算(即this |)对它们进行积分。 <<这是原点左移功能,|操作是积分。
5. 测试
写完代码,我们来测试一下。 这里我同时生成 10,000 个 goroutine 的 ID,将它们存储在 map 中,并检查是否存在重复。 让我们看看代码:
以下是验证结果:
感谢您阅读本文。
关注七爪网,获取更多APP/小程序/网站源码资源!