

一、总体内容
1、内置函数、递归函数、闭包
2、数组和切片
3、map数据结构
4、package介绍
一、内置函数
注意:值类型用new来分配内存,引用类型用make来分配内存
1、close:主要用来关闭channel
2、len:用来求长度,比如string、array、slice、map、channel
3、new:用来分配内存,主要用来分配值类型,比如int、struct、浮点型。返回的是指针
代码案例
6、panic和recover:用来做错误处理
panic可以快速定位到哪里出错了
捕获异常的原因是因为上线项目之后不能够随便的停止,所以要捕获
还可以自己手动的通过pinic来捕获异常
数组:
var a [1]int :这个是确定的长度,为1
var a [] int :这个是切片
new和make的区别
new之后如果是slice等引用类型必须要用make初始化一下才可以用如下:
递归函数
一个函数调用自己,就叫做递归
例子一:计算阶乘
斐波那契数列
闭包:
闭包:是一个函数和与其相关作用域的结合体
下面的匿名函数中的变量和x绑定了
例2
数组
1、数组:是同一种数据类型的固定长度的序列
2、数组定义:var a [len]int 比如:var a [5] int 一旦定义长度就不会变了
3、长度是数组类型的一部分,因此var a[5]int和var a[10]int 是不同的类型
4、数组可以通过下标进行访问,下标是从零开始的,最后一个元素下标是len-1
遍历的方法如下:
下面是遍历数组的两种方法
5、访问越界,如果下标在数组合法范围之外,则触发越界,会panic
如下,就会在编译的时候报错,也就是pinic了
6、数组是值类型,因此改变副本的值,不会改变本身的值
在函数里面改变不会改变外部的值,在函数中改变的知识数组的副本
如果要改变函数中的值,需要通过指针的方式来修改
数组和切片:
1、练习,使用非递归的方式实现斐波那契数列,打印前100个数
2、数组初始化
a、var age0 [5]int =[5]int {1,2,3,4,5]
b、var age1=[5] int {1,2,3,4,5]
c、var age2=[…]int {1,2,3,4,5}
d、var str=[5]string{3:”hello word”,4:”tom”}
3、多维数组
a、var age[5][3] int //5行 3 列,第一个行,第二个列
b、var f[2][3] int=[…][3]int {{1,2,3},{7,8,9}}
遍历多维数组
注意这里的切片和数组的区别:
a、声明的时候切片没有长度,数组有长度在中括号中,因为切片是变长的,数组的是长度固定的,切片是引用类型,数组是值类型
1、切片:切片是数组的一个引用,因此切片是引用类型
2、切片的长度可以改变,因此切片是一个可变的数组
3、切片遍历方式和数组一样,可以用len()求长度
4、cap可以求出slice最大的容量,0<= len (slice)<=cap (array),其中array是slice引用的数组
5、切片的定义:var变量名[]切片类型,比如var str []string var arr[] int
方法: 切片初始化只能通过切片的方式
1、切片初始化:var slice [] int=arr[start”end].包含start到end之间的元素名不包含end
2、var slice []int=arr[0:end]可以简写为var slice []int=arr[:end]
3、var slice []int=arr[start:len(arr)] 可以简写为var slice[]int = arr[start:]
4、var slice []int=arr[0,len(arr)] 可以简写为var slice[]int=arr[:]
5、如果要切片最后一个元素去掉,可以这样写
slice=slice[:len(slice)-1]
数组和切片定义之后必须要初始化
下面是切片的内存布局 第一个是x的切片布局指针方式指针数组,
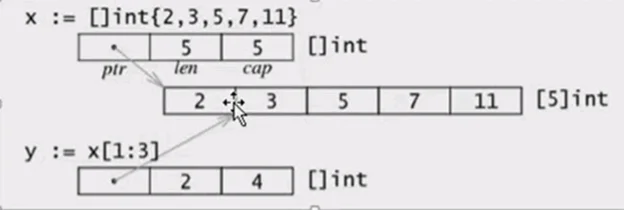
上面的第三个切片的地址指向的是数组的第一个元素的地址,如下:
3、通过make来创建切片

4、用append内置函数操作切片
slice=append(slice,10)
var a=[]int{1,2,3}
var b=[]int{4,5,6}
a=append(a,b…) //这里注意,如果是一个切片的话,append需要后面是…
切片是引用,如果切片的append的大小超过了原来的数组的大小,这个时候就会扩容,可以通过切片和数组的第一个值的地址是否相同来比较
上面切片的地址和数组的第一个元素的地址不同可以看到,这个切片进行了扩容的方式,新开了一块内存和原来的内存不一样了,这个是内部的算法决定的
5、切片遍历
for index,val :range slice{
}
6、切片resize,切片之后可以再进行切片
var a=[] int{1,2,3}
b:=a[1:2]
b=b[0:3]
7、切片的拷贝
s1:=[]int{1,2,3,4}
s2:=make([]int ,10)
copy(s2,s1)
s3:=[]int{1,2,3}
s3=append(s3,s2…)
s3=append(s3,4,5,6)
8、stringhe slice
string底层就是一个byte的数组,因此,也可以进行切片操作
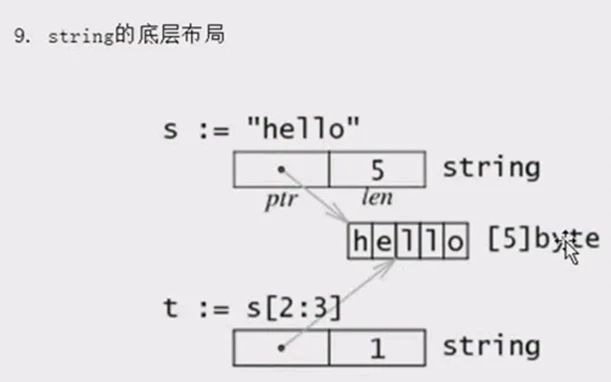
10、如何改变string中的字符串?
string本身是不可变的,因此要改变string中字符,需要如下操作
下面是针对没有中文的情况下:
11、排序和查找操作
排序操作主要在sort包中,导入就可以使用了
import(“sort”)
sort.Ints对整数进行排序,sort.String对字符串进行排序,sort.Float64s对浮点数进行排序
sort.SearchInts(a []int,b int)从数组a中查找b,前提是a必须有序
sort.SearchFloats(a []float64 ,b float64)从数组a中查找b,前提是a必须有序
sort.SearchStrings(a []string,bstring)从数组a中查找b,请安提是a必须有序
下面是对数组进行排序
map数据结构
一、简介
key-value的数据结构
a、声明,声明是不会分配内存的,初始化需要make
var map1 map[key type]value type
var a map[string]string
var a map[string]int
var a map[int]string
var a map[string]map[string]string
map相关的操作
a[“hello”]=”world” 插入和更新
val,ok:=a[“hello”] 查找
for k,v:=range a { 遍历
}
delete (a,”hello”) 删除
len(a) 长度
排序:
map排序,map的排序是无序的:
a、先获取所有key,把key进行排序
b、按照排好的key,进行遍历
map反转
初始化另外一个map把key、value呼唤即可
包
1、golang中的包
a、golang目前有150个标准的包,覆盖了几乎所有的基础库
b、golang.org有所有包的文档,没事就翻翻
2、线程同步
a、import(“sync”)
b、互斥锁 var mu sync.Mutex,同一时间只能有一个goroute能进去
c、读写锁,var mu sync.RWMutex
线程和协程,只有读操作的时候不用加锁
1、如果有写操作,需要加锁
2、如果有读写的操作,需要加锁
3、如果只有读的操作,不需要加锁
编译的时候—race可以查看是否有竞争
下面是互斥锁的程序
读写锁:
实际就是一种特殊的自旋锁,它把共享资源的访问者划分为读者和写者,读者只对共享资源进行读访问,写者则需要对共享资源进行写操作
使用场景:
写比较少,有大量的读 (读多写少)
写的时候只有一个goroute去写,但是读的时候所有的goroute去读
读写锁有三种状态:读加锁状态、写加锁状态和不加锁状态
一次只有一个线程可以占有写模式的读写锁,但是多个线程可以同时占有读模式的读写锁。(这也是它能够实现高并发的一种手段)
当读写锁在写加锁模式下,任何试图对这个锁进行加锁的线程都会被阻塞,直到写进程对其解锁。
当读写锁在读加锁模式先,任何线程都可以对其进行读加锁操作,但是所有试图进行写加锁操作的线程都会被阻塞,直到所有的读线程都解锁。
所以读写锁非常适合对数据结构读的次数远远大于写的情况
原子操作:atomic 包 在sync下面
https://studygolang.com/pkgdoc
这是串行的操作
比较读写锁和互斥锁的性能
go get安装第三方包
go get后面跟上github地址