
sync.WaitGroupWaitGroup 的源码也非常简短,抛去注释外也就 100 行左右的代码。但即使是这 100 行代码,里面也有着关乎内存优化、并发安全考虑等各种性能优化手段。
本文将基于 go-1.13 的源码 进行分析,将会涉及以下知识点: 1. WaitGroup 的实现逻辑 2. WaitGroup 的底层内存结构及性能优化 3. WaitGroup 的内部如何实现无锁操作
WaitGroup 的使用
在正式分析源码之前,我们先看下 WaitGroup 的基本用法:
AddDoneWaitWaitGroup 的实现逻辑
我们首先看下 WaitGroup 的组成结构,代码如下:
noCopygo vetstate1 [3]uint32state1为了便于理解 WaitGroup 的整个实现过程,我们暂时先不考虑内存对齐和并发安全等方面因素。那么 WaitGroup 可以近似的看做以下代码:
其中:
counterWaitGroup.Add(n)counter += nWaitGroup.Done()counter--waiterWaitGroup.Waitsemaruntime_Semacquireruntime_Semreleaseruntime_Semacquireruntime_SemreleaseWaitGroup 的整个调用过程可以简单地描述成下面这样:
WaitGroup.Add(n)counter += nWaitGroup.Wait()waiter++runtime_Semacquire(semap)WaitGroup.Done()counter--WaitGroup.Wait以上就是 WaitGroup 实现过程的简略版。但实际上,WaitGroup 在实现过程中对并发性能以及内存占用优化上,都有一些非常巧妙的设计点,我们接下来要着重讨论下。
WaitGroup 的底层内存结构
state1state1state1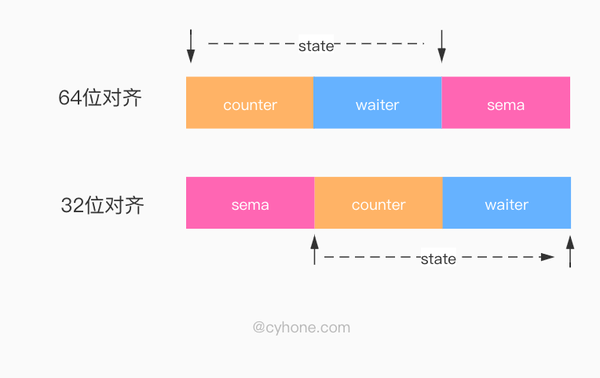
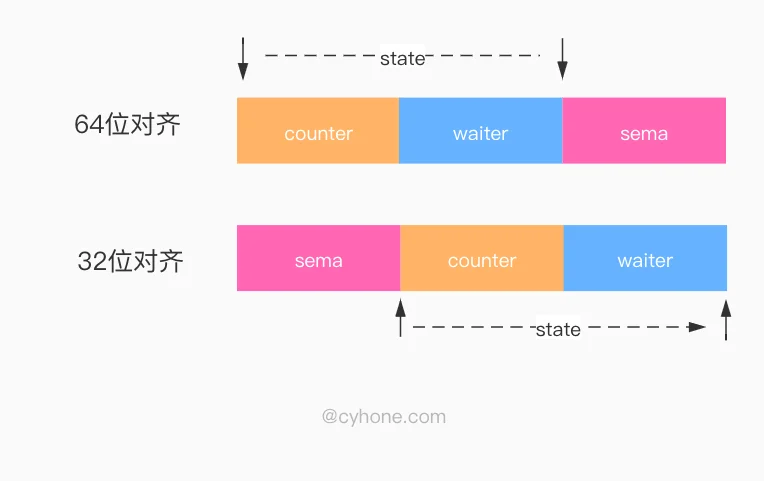
我们在图中提到了 Golang 内存对齐的概念。简单来说,如果变量是 64 位对齐 (8 byte), 则该变量的起始地址是 8 的倍数。如果变量是 32 位对齐 (4 byte),则该变量的起始地址是 4 的倍数。
state1state1state1state1state1state1为什么会有这种奇怪的设定呢?这里涉及两个前提:
前提 1:在 WaitGroup 的真实逻辑中, counter 和 waiter 被合在了一起,当成一个 64 位的整数对外使用。当需要变化 counter 和 waiter 的值的时候,也是通过 atomic 来原子操作这个 64 位整数。但至于为什么合在一起,我们会在下文详细讨论。
前提 2:在 32 位系统下,如果使用 atomic 对 64 位变量进行原子操作,调用者需要自行保证变量的 64 位对齐,否则将会出现异常。golang 的官方文档 sync/atomic/#pkg-note-BUG 原文是这么说的:
On ARM, x86-32, and 32-bit MIPS, it is the caller’s responsibility to arrange for 64-bit alignment of 64-bit words accessed atomically. The first word in a variable or in an allocated struct, array, or slice can be relied upon to be 64-bit aligned.
count+waiter[3]uint32state1state1state1semacounter+waiterstate1state1WaitGroup 的无锁实现
counterwaitercounterwaiterMutexRWMutexcounterwaitercounterwaitercounterwaitercounteratomic.AddUint64(statep, uint64(delta)<<32)count += deltaatomic.CompareAndSwapUint64(statep, state, state+1)counterwaiter--counter+waiter总结
Waitgroup 虽然只有 100 行左右的代码。作为语言的内置库,我们从中可以看出作者对每个细节的极致打磨,非常精细的针对场景优化性能,这也给我们写程序带来了很多启发。
参考

