
为什么需要无锁队列
无锁队列解决了什么问题?无锁队列解决了锁引起的问题。
cache失效
当CPU要访问主存的时候,这些数据首先要被copy到cache中,因为这些数据在不久的将来可能又会被处理器访问;CPU访问cache的速度要比访问内存要快的多;由于线程频繁切换,会造成cache失效,将导致应用程序性能下降。
阻塞引起的CPU浪费
mutex是阻塞的,在一个负载较重的应用程序中使用阻塞队列来在线程之间传递消息,会导致频繁的线程切换,大量的时间将被浪费在获取mutex,而不是处理任务上。
这就需要非阻塞来解决问题。任务之间不争抢任何资源,在队列中预定一个位置,然后在这个位置上插入或提取数据。这种机制使用了cas(compare and swap)的操作,它是一个原子操作,需要CPU指令支持。它的思想是先比较,再赋值。具体操作如下:它需要3个操作数,m,A, B,其中m是一个内存地址,将m指向的内存中的数据与A比较,如果相等则将B写入到m指向的内存并返回true,如果不相等则什么也不做返回false。
cas语义如下
内存的频繁申请和释放
当一个任务从堆中分配内存时,标准的内存分配机制会阻塞所有与这个任务共享地址空间的其它任务(进程中的所有线程)。malloc本身也是加锁的,保证线程安全。这样也会造成线程之间的竞争。标准队列插入数据的时候,都回导致堆上的动态内存分配,会导致应用程序性能下降。
小结
- cache失效
- 阻塞引起的CPU浪费
- 内存的频繁申请和释放
这3个问题,本质上都是由于线程切换带来的问题。无锁队列就是从这几个方面解决问题。
无锁队列使用场景
无锁队列适用于队列push、pop非常频繁的场景,效率要比mutex高很多; 比如,股票行情,1秒钟至少几十万数据量。
无锁队列一般也会结合mutex + condition使用,如果数据量很小,比如一秒钟几百个、几千个消息,那就会有很多时间是没有消息需要处理的,消费线程就会休眠,等待唤醒;所以对于消息量很小的情况,无锁队列的吞吐量并不会有很大的提升,没有必要使用无锁队列。
无锁队列的实现,主要分为两类:
- 链表实现;
- 数组实现。
链表实现有一个问题,就是会频繁的从堆上申请内存,所以效率也不会很高。
对于一写一读场景下,各种消息队列的测试结果对比:
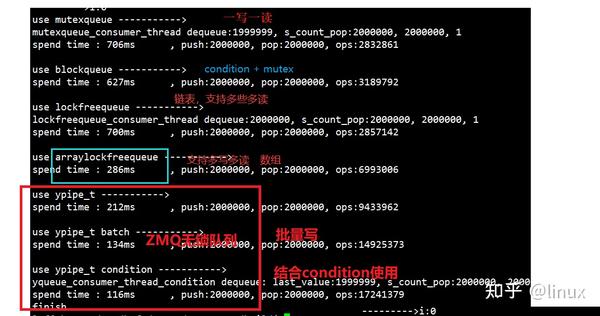
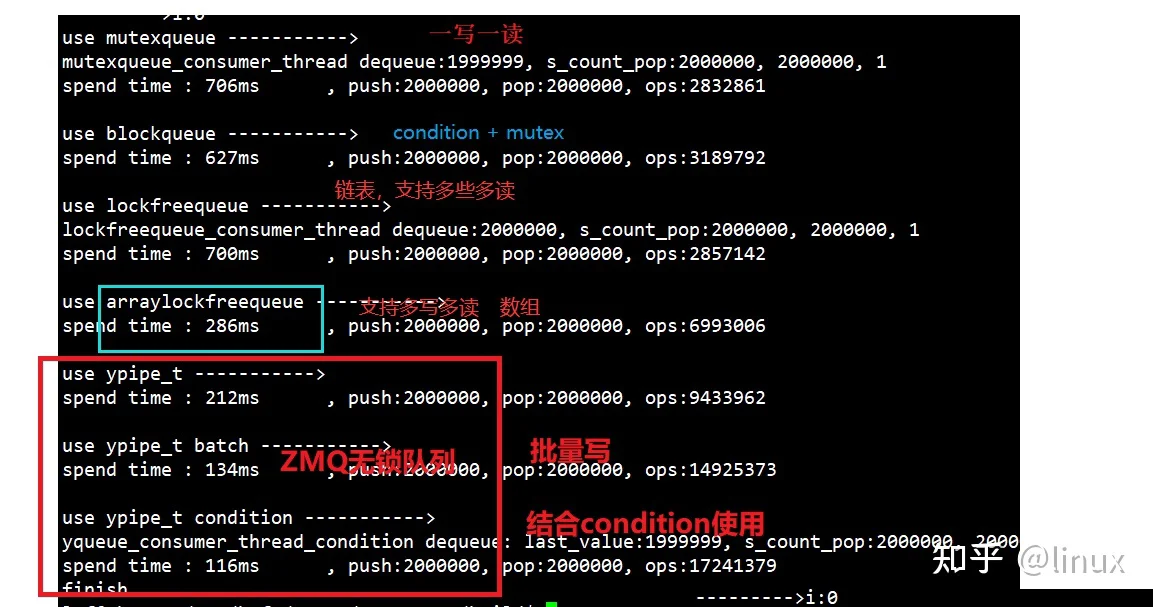
zmq无锁队列的实现原理
zmq中实现了一个无锁队列,这个无锁队列只支持单写单读的场景。zmq的无锁队列是十分高效的,号称全世界最快的无锁队列。它的设计是非常优秀的,有很多设计是值得借鉴的。我们可以直接把它用到项目中去,zmq只用了不到600行代码就实现了无锁队列。
zmq的无锁队列主要由yqueue和ypipe组成。yqueue负责队列的数据组织,ypipe负责队列的操作。
相关视频推荐
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

原子操作函数
无锁队列的实现,一定是基于原子操作的。
zmq无锁队列使用如下原子操作函数
set函数,把私有成员ptr指针设置成参数ptr_的值,不是一个原子操作,需要使用者确保执行set过程没有其他线程使用ptr的值。
xchg函数,把私有成员ptr指针设置成参数val_的值,并返回ptr设置之前的值。原子操作,线程安全。
cas函数,原子操作,线程安全,把私有成员ptr指针与参数cmp_指针比较:
如果相等返回ptr设置之前的值,并把ptr更新为参数val_的值;
如果不相等直接返回ptr值。
chunk机制
每次分配可以存放N个元素的大块内存,减少内存的分配和释放。N值还有元素的类型,是可以根据自己的需要进行设置的。N不能太小,如果太小,就退化成链表方式了,就会有内存频分的申请和释放的问题。


当队列空间不足时每次分配一个chunk_t,每个chunk_t能存储N个元素。
当一个chunk中的元素都出队后,回收的chunk也不是马上释放,而是根据局部性原理先回收到spare_chunk里面,当再次需要分配chunk_t的时候从spare_chunk中获取。spare_chunk只保存一个chunk,即只保存最新的要回收的chunk;如果spare_chunk现在保存了一个chunk A,如果现在有一个更新的chunk B需要回收,那么spare_chunk会更新为chunk B,chunk A会被释放;这个操作是通过cas完成的。
批量写入
支持批量写入,批量能够提高吞吐量。
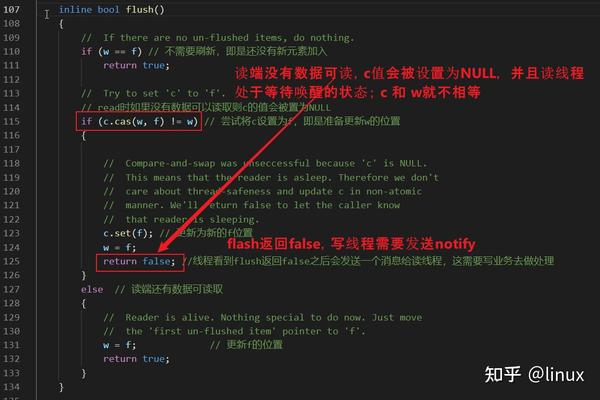
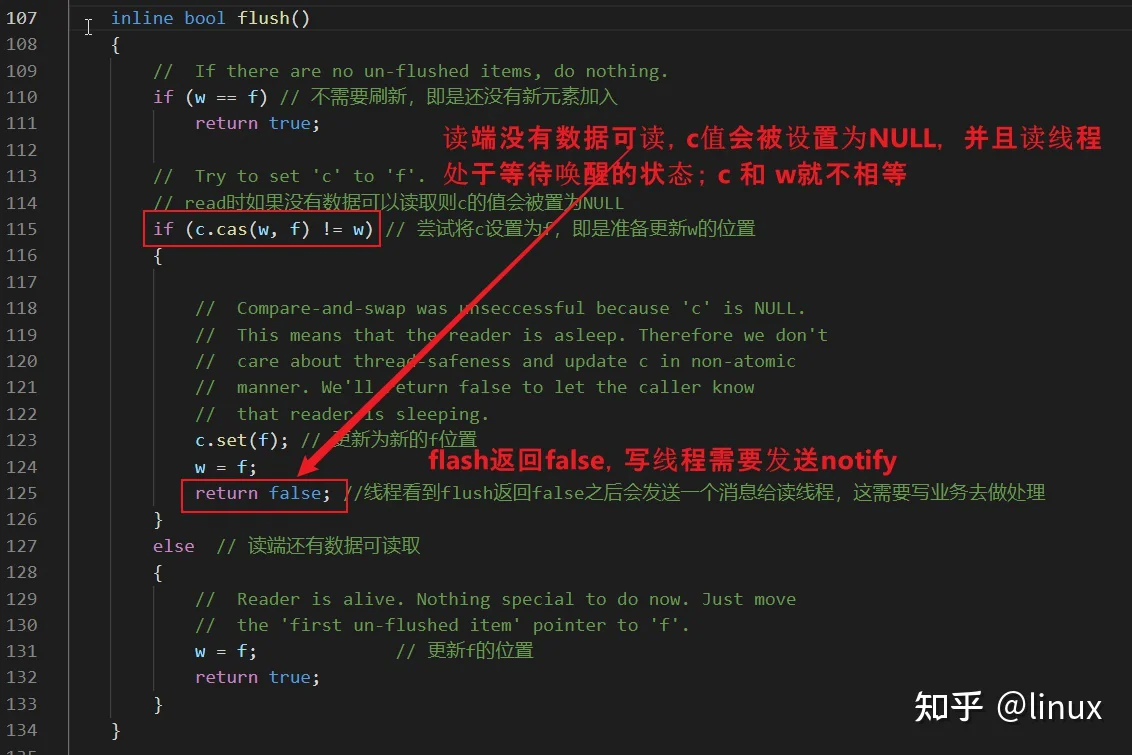
incomplete_flush后才更新到读端。
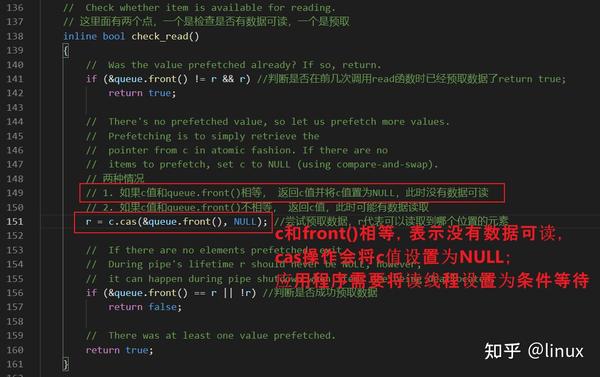
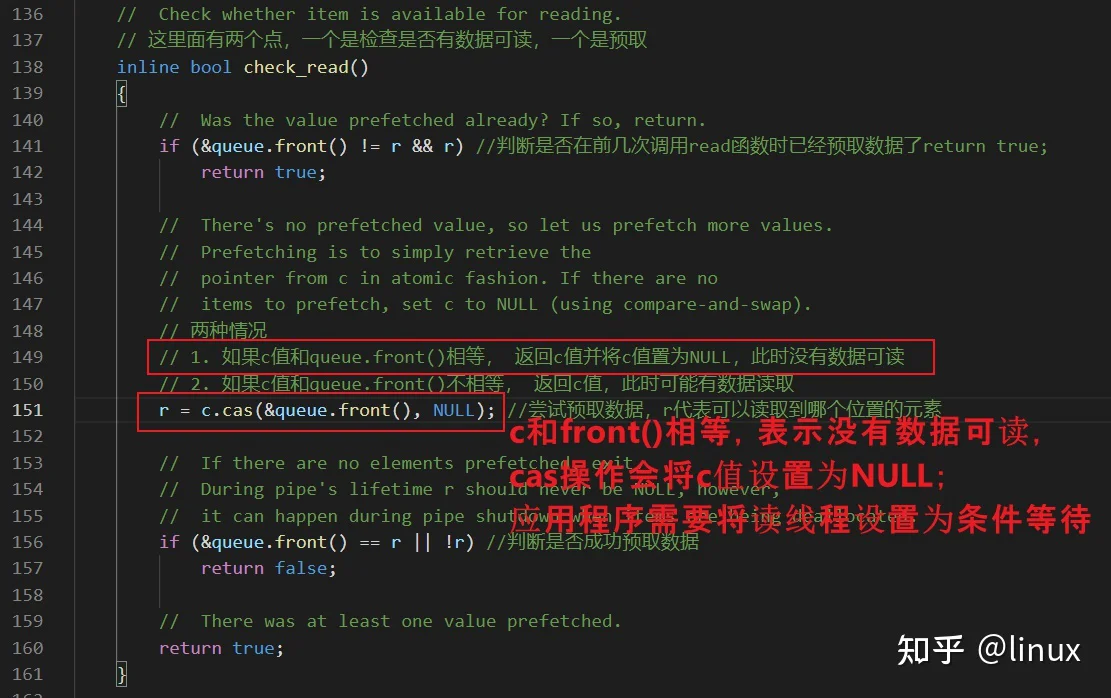
怎样唤醒读端?
读端没有数据可读,这个时候应该怎么办?
使用mutex + condition进行wait,休眠;
写端怎么唤醒读端去读取数据呢?
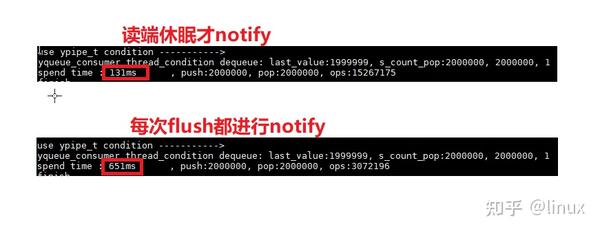
很多消息队列,都是每次有消息,都进行notify。如果发送端每发送一个消息都notify,性能会下降。调用notify,涉及到线程切换,内核态与用户态切换,会影响性能;检测到读端处于阻塞状态,在notify,效率才高。
zmq的无锁队列写端只有在读端处于休眠状态的时候才会发送notify,是不是很厉害的样子?写端是怎么检测到读端处于休眠状态的呢?
写端在进行flush的时候,如果返回false,说明读端处于等待唤醒的状态,就可以进行notify。


condition wait和notify,都需要由应用程序自己去做。
我们修改代码,将写端修改为每次flush都notify;经过测试,性能是会明显下降的。

写端为什么可以检测到读端的状态的?
c值是唯一一个读端和写端都要设置的值,通过对c值进行cas操作,写端就可以判断读端是否处于等待唤醒的状态。
yqueue的实现
yqueue主要负责队列的数据组织,通过chunk机制进行管理。
数据的组织
chunk是通过链表进行组织的;
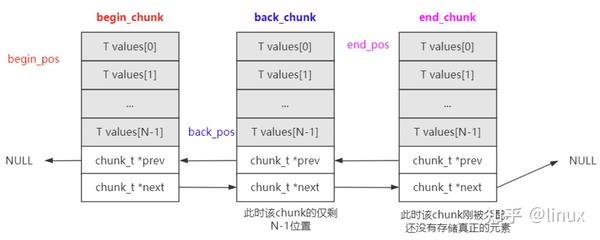
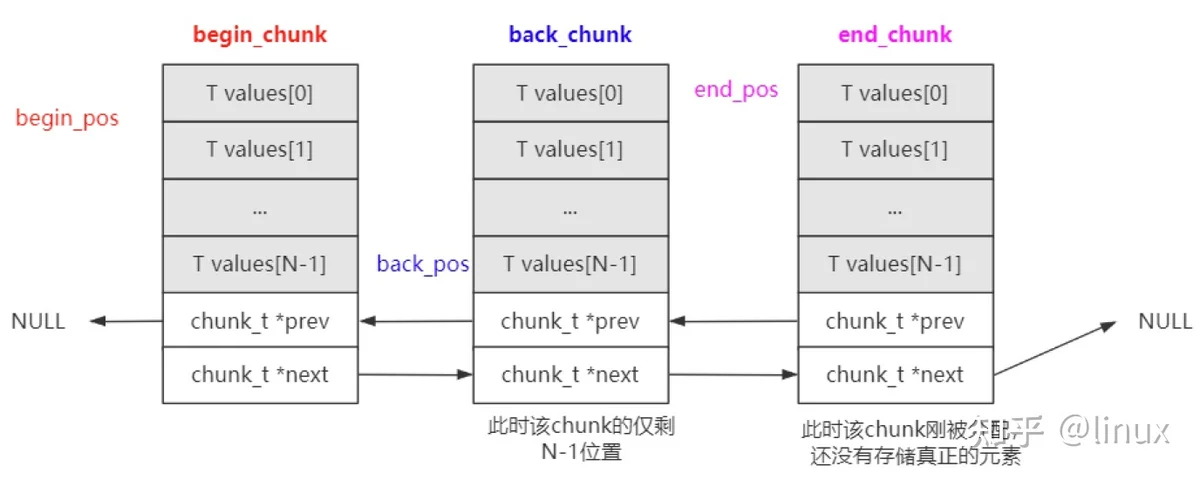
yqueue_t内部有三个chunk_t类型指针以及对应的索引位置:
begin_chunk/begin_pos:begin_chunk指向第一个的chunk;begin_pos是队列第一个元素在当前chunk中的位置;
back_chunk/back_pos:back_chunk指向队列尾所在的chunk;back_pos是队列最后一个元素在当前chunk的位置;
end_chunk/end_pos: end_chunk指向最后一个chunk;end_chunk和back_chunk大部分情况是一致的;end_pos 大部分情况是 back_pos + 1; end_pos主要是用来判断是否要分配新的chunk。
上图中:
由于back_pos已经指向了back_chunk的最后一个元素,所以end_pos就指向了end_chunk的第一个元素。
back、push函数
back函数返回队列尾部元素的引用;
push函数,更新back_chunk、back_pos的值,并且判断是否需要新的chunk;如果需要新的chunk,先看spare_chunk是否为空: 如果spare_chunk有值,则将spare_chunk作为end_chunk; 否则新malloc一个chunk。
可以使用back和push函数向队列中插入元素:
front、pop函数
front函数返回队列头部元素的引用。
begin_pos == N可以使用front和pop函数进行出队列操作
这里有两点需要注意:
- pop掉的元素,其销毁工作交给调用者完成,即是pop前调用者需要通过front()接口读取并进行销毁(比如动态分配的对象);
- 空闲块的保存,要求是原子操作;因为闲块是读写线程的共享变量,因为在push中也使用了spare_chunk。
ypipe的实现
ypipe_t在yqueue_t的基础上构建一个单写单读的无锁队列。
**w、r、f****c**write
incomplete_fqueue.back()fflush
wfccheck_read
crrc&queue.front()cNULLc基于环形数组的无锁队列
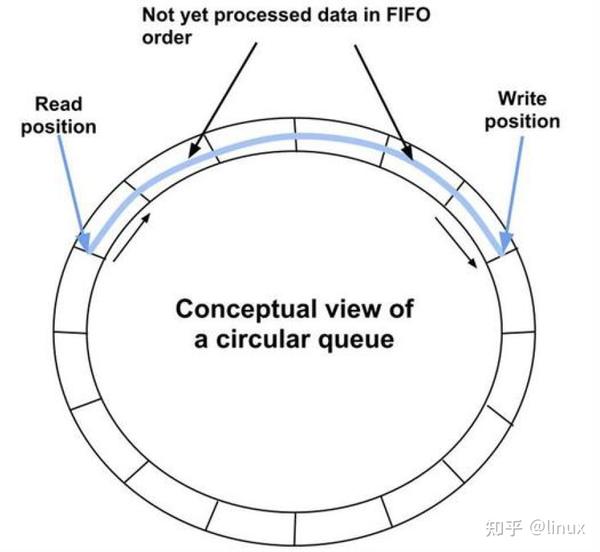
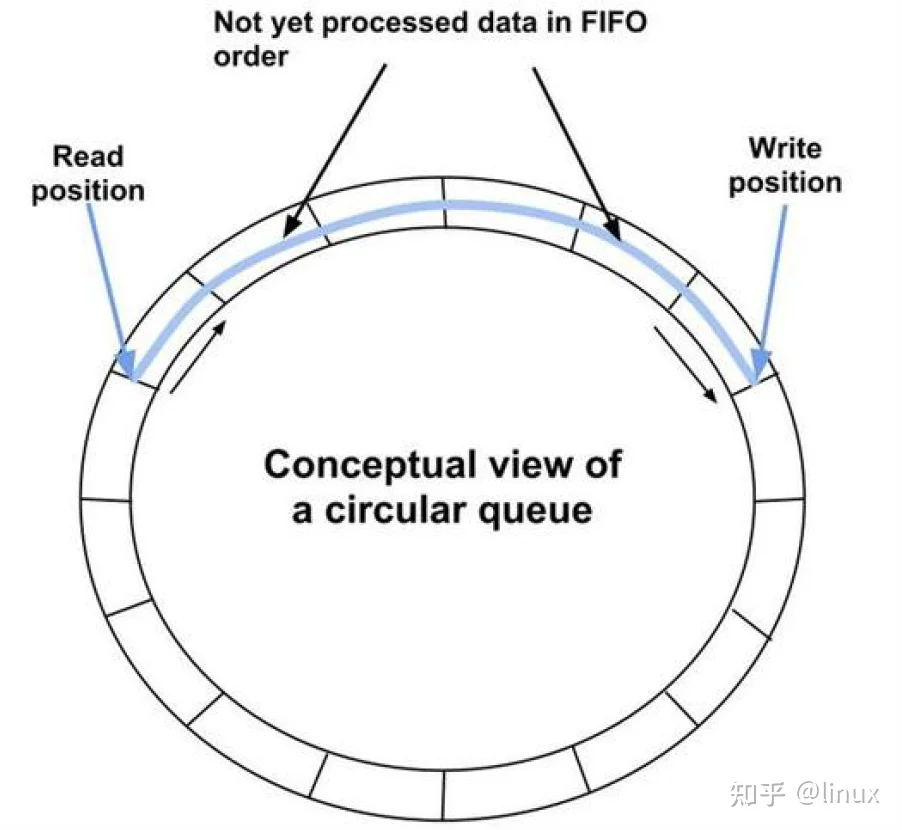
基于环形数组的无锁队列,也是利用cas操作解决多线程数据竞争的问题;它支持多谢多读。
关键是对于三种下标的操作:
- m_writeIndex;//新元素入列时存放位置在数组中的下标
- m_readIndex;/ 下一个出列的元素在数组中的下标
- m_maximumReadIndex; //最后一个已经完成入列操作的元素在数组中的下标, 即可以读到的最大索引。
通过对这3个下标的cas操作,解决多线程数据竞争的问题。
enqueue
首先判断队列是否已满:(m_writeIndex + 1) %/Q_SIZE == m_readIndex;如果队列已满,则返回false。
enqueu的核心思想是预先占用一个可写的位置,保证同一个位置只有一个线程会进行写操作;并且保证先获取到位置的线程,先操作,保证了操作的顺序性。这两个都是通过cas操作保证的。
dequeue
m_readIndex == m_maximumReadIndex通过cas操作保证同一个位置,只有一个线程读取。
多写多读测试结果
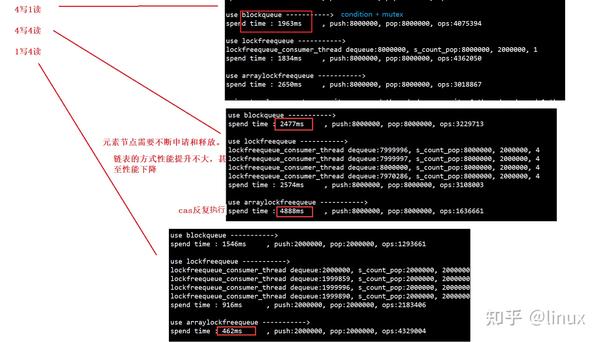
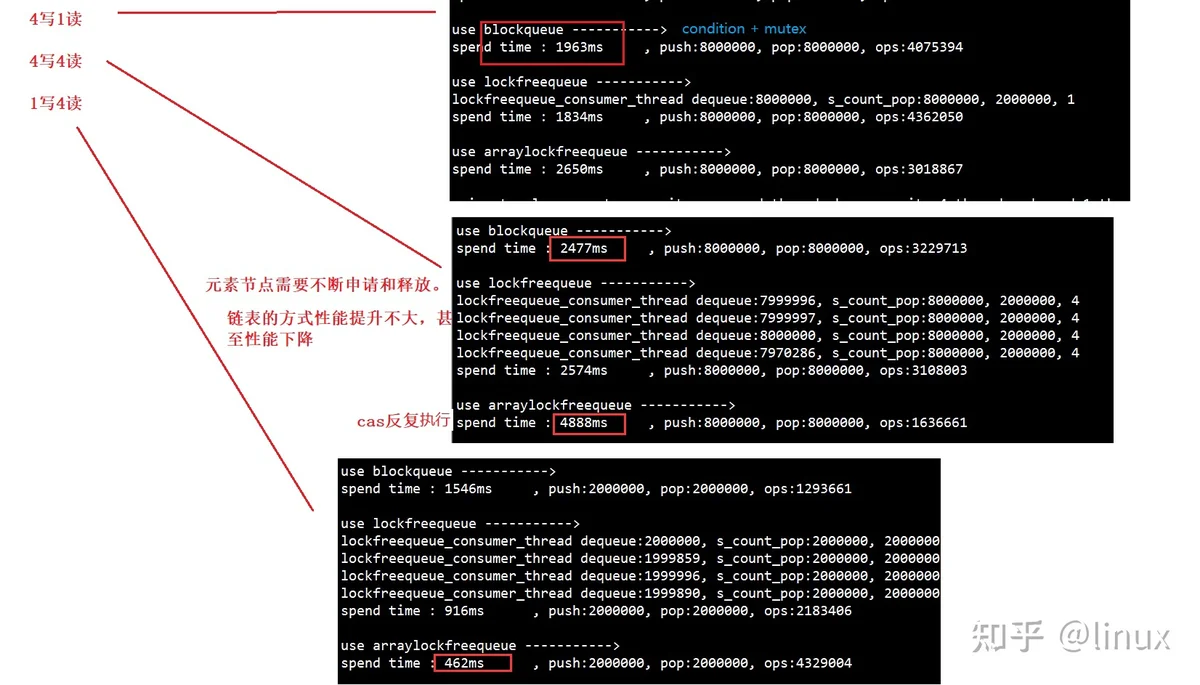
从测试结果可以看出,这个基于环形数组的队列,比较适合1写多读的场景,性能会有很大的提升。
总结
本文主要介绍了以下内容:
- 无锁队列所解决的问题;
- 无锁队列都是利用了cas操作,来解决多线程数据竞争的问题;因为cas操作的粒度要比mutex,spinlock要小很多;
- zmq无锁队列实现原理,包括chunk机制、批量写入、怎样唤醒读端等;yqueue、ypipe的具体的实现,预读机制、写端如何检测到读端的状态等;它只支持单写单读的场景;
- 基于环形数组的无锁队列,它支持多写多读的场景;对于1写多读的场景,性能有很大提升;它是如何解决多线程竞争问题的。