
哈希表
键-值(key-value)- 使用哈希函数将被找查的键转换为数组的索引.在理想的情况下,不同的键会被装换为不同的索引值,但是在有些情况下我们需要处理多个键被哈希到同一个索引值得情况。所以哈希查找的第二个步骤是处理冲突。
- 处理哈希碰撞冲突。一般处理哈希碰撞用拉链法和开放寻址法等方法。
开放地址法:当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止。
拉链法:当通过哈希函数把键转换为数组的索引时,如果索引重复,就在该位置用链表顺序 存储该键值对。
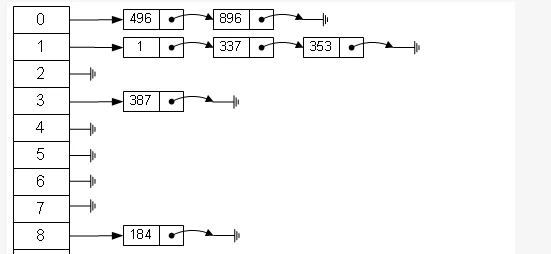
Java 中的 HashMap
基本认识:基于 Map 接口,允许 null 键/值,非同步,不保证有序,也不保证顺序不随时间变化。
HashMap 中和 Map 一样,键值对都是保存在一个内部类中的,而在 HashMap 类中有一个很重要的字段,那就是 Node[] table,即是一个哈希桶数组。Node 是 HashMap 的一个内部类,实现了 Map.Entry 接口,本质是就是一个映射 (键值对)。
1
2
3
4
5
6
7
8
9
static class <K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next; //链表的下一个node
Node(int hash, K key, V value, Node<K,V> next) { ... }
/.../
}
还有两个重要参数:
capacityload factorcapacity*load factorput()hashCode()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
public V put(K key, V value){
return putVal(hash(key),key,value,false,true);
}
final V putVal(int hash,K key,V value,boolean onlyIfAbsent,boolean evict)
{
Node<K,V>[] tab; Node<K,V> p; int n, i;
// tab为空则创建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算index,并对null做处理
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 节点存在
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 该链为树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 该链为链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 写入
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 超过load factor*current capacity,resize
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
get()equal()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 直接命中
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 未命中
if ((e = first.next) != null) {
// 在树中get
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 在链表中get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
K/VHashMapgolang 中的 map
==1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
struct Hmap{//map的关键数据
uint8 B; // 可以容纳2^B个项
uint16 bucketsize; // 每个桶的大小
....
byte *buckets; // 2^B个Buckets的数组
byte *oldbuckets; // 前一个buckets,只有当正在扩容时才不为空
};
//初始化的3种方式
ages:=make(map[string]int)// mapping from strings to ints
ages:=map[string]int{}
ages:=map[string]int{
"alice":0,
"charlie":33,
}
//取值
ages["alice"]=0
//赋值
ages["charlie"]=34
//删除
delete(ages, "alice") // remove element ages["alice"]
上面这些都是安全的,及时失败也会返回对应 value 类型的零值。
但是有时候需要想知道对应的元素是否真的在 map 之中。推荐写法:
1
2
3
//map的下标语法将产生两个值;第二个是一个布尔值
//用于报告元素是否真的存在。布尔变量一般命名为ok,特别适合马上用于if条件判断部分。
if age, ok := ages["alice"]; !ok { /* ... */ }
扩容
6.5扩容会建立一个大小是原来 2 倍的空表。将旧的 bucket 搬到新表中 (复制),但是并不会将旧的 bucket 从 oldbucket 中删除,而是加上一个已删除的标记。
由于整个过程是逐渐完成的,这样就会导致一部分数据还没有完全复制到新表,所以会对 insert,remove,get 等操作产生影响。并且只有当所有复制操作完成后才会释放 oldbucket。
insert- 根据 key 算出 hash 值,进而得出索引的位置
- 如果 bucket 的位置在 old table 中,就重新 hash 到新表中
- 查找对应的位置,如果在 bucket 中如果已经存在相应的 key,就覆盖原来 value,没有就插入
- 根据 table 中元素的个数,判断是否扩容
- 如果对应的 bucket 已经 full,重新申请新的 bucket 作为 overbucket(溢出桶链表)。
- 将 key/value pair 插入到 bucket 中。
get- 根据 key 算出 hash 值,进而得出索引的位置
- 如果存在 old table, 首先在 old table 中查找,如果找到的 bucket 已经扩容,转到步骤 3。 反之,返回其对应的 value。
- 在 new table 中查找对应的 value。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
do { //对每个bucket
//依次比较桶内的每一项存放的高位hash与所求的hash值高位是否相等
for(i = 0, k = b->data, v = k + h->keysize * BUCKETSIZE; i < BUCKETSIZE; i++, k += h->keysize, v += h->valuesize) {
if(b->tophash[i] == top) {
k2 = IK(h, k);
t->key->alg->equal(&eq, t->key->size, key, k2);
if(eq) { //相等的情况下再去做key比较...
*keyp = k2;
return IV(h, v);
}
}
}
b = b->overflow; //b设置为它的下一下溢出链
} while(b != nil);
这里一个细节需要注意一下。不认真看可能会以为低位用于定位 bucket 在数组的 index,那么高位就是用于 key/valule 在 bucket 内部的 offset。事实上高 8 位不是用作 offset 的,而是用于加快 key 的比较的。
总结
在扩容过程中,oldbucket 是被冻结的,查找时会在 oldbucket 中查找,但不会在 oldbucket 中插入数据。如果在 oldbucket 是找到了相应的 key,做法是将它迁移到新 bucket 后加入扩容标记。
然后就是只要在某个 bucket 中找到第一个空位,就会将 key/value 插入到这个位置。也就是位置位于 bucket 前面的会覆盖后面的 (类似于存储系统设计中做删除时的常用的技巧之一,直接用新数据追加方式写,新版本数据覆盖老版本数据)。找到了相同的 key 或者找到第一个空位就可以结束遍历了。不过这也意味着做删除时必须完全的遍历 bucket 所有溢出链,将所有的相同 key 数据都删除。所以目前 map 的设计是为插入而优化的,删除效率会比插入低一些。
参考:
Java 8 系列之重新认识 HashMap
Java HashMap 工作原理及实现