
Jaeger
OpenTracing 是开放式分布式追踪规范,OpenTracing API 是一致,可表达,与供应商无关的API,用于分布式跟踪和上下文传播。
OpenTracing 的客户端库以及规范,可以到 Github 中查看:https://github.com/opentracing/
Jaeger 是 Uber 开源的分布式跟踪系统,详细的介绍可以自行查阅资料。
部署 Jaeger
这里我们需要部署一个 Jaeger 实例,以供微服务以及后面学习需要。
使用 Docker 部署很简单,只需要执行下面一条命令即可:
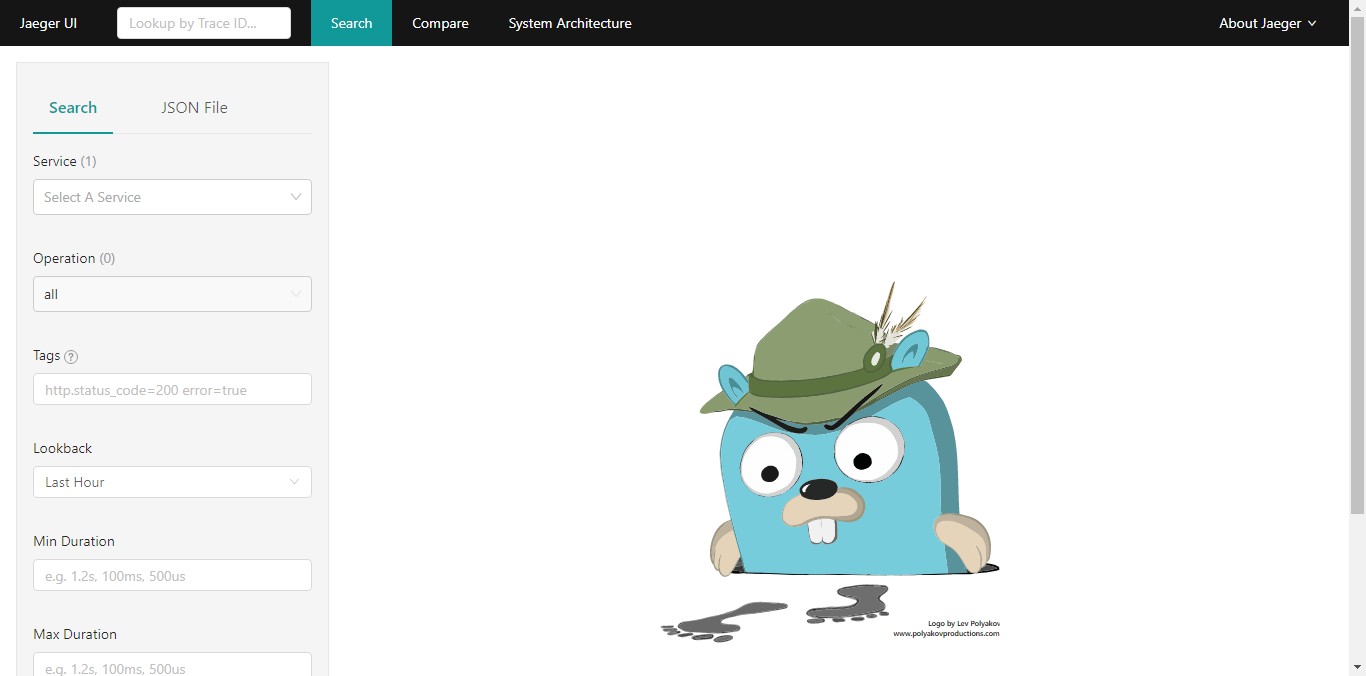
访问 16686 端口,即可看到 UI 界面。
后面我们生成的链路追踪信息会推送到此服务,而且可以通过 Jaeger UI 查询这些追踪信息。
从示例了解 Jaeger Client Go
这里,我们主要了解一些 Jaeger Client 的接口和结构体,了解一些代码的使用。
为了让读者方便了解 Trace、Span 等,可以看一下这个 Json 的大概结构:
创建一个 client1 的项目,然后引入 Jaeger client 包。
然后引入包
了解 trace、span
链路追踪中的一个进程使用一个 trace 实例标识,每个服务或函数使用一个 span 标识,jaeger 包中有个函数可以创建空的 trace:
然后就是调用链中,生成父子关系的 Span:
每个 span 表示调用链中的一个结点,每个结点都需要明确父 span。
trace{span1,span2}span1 -> span2tracer 配置
由于服务之间的调用是跨进程的,每个进程都有一些特点的标记,为了标识这些进程,我们需要在上下文间、span 携带一些信息。
例如,我们在发起请求的第一个进程中,配置 trace,配置服务名称等。
sampler.typesampler.paramReporter 可以配置如何上报,后面独立小节聊一下这个配置。
传递上下文的时候,我们可以打印一些日志:
配置完毕后就可以创建 tracer 对象了:
完整代码如下:
启动后:
Sampler 配置
sampler 配置代码示例:
jaegercfg.SamplerConfigtypeparam为什么要配置采样器?因为服务中的请求千千万万,如果每个请求都要记录追踪信息并发送到 Jaeger 后端,那么面对高并发时,记录链路追踪以及推送追踪信息消耗的性能就不可忽视,会对系统带来较大的影响。当我们配置 sampler 后,jaeger 会根据当前配置的采样策略做出采样行为。
jaegercfg.SamplerConfig 结构体中的字段 Param 是设置采样率或速率,要根据 Type 而定。
下面对其关系进行说明:
| Type | Param | 说明 |
|---|---|---|
| "const" | 0或1 | 采样器始终对所有 tracer 做出相同的决定;要么全部采样,要么全部不采样 |
| "probabilistic" | 0.0~1.0 | 采样器做出随机采样决策,Param 为采样概率 |
| "ratelimiting" | N | 采样器一定的恒定速率对tracer进行采样,Param=2.0,则限制每秒采集2条 |
| "remote" | 无 | 采样器请咨询Jaeger代理以获取在当前服务中使用的适当采样策略。 |
sampler.Type="remote"sampler.Type=jaeger.SamplerTypeRemoteReporter 配置
看一下 ReporterConfig 的定义。
Reporter 配置客户端如何上报追踪信息的,所有字段都是可选的。
这里我们介绍几个常用的配置字段。
QUEUESIZE,设置队列大小,存储采样的 span 信息,队列满了后一次性发送到 jaeger 后端;defaultQueueSize 默认为 100;
BufferFlushInterval 强制清空、推送队列时间,对于流量不高的程序,队列可能长时间不能满,那么设置这个时间,超时可以自动推送一次。对于高并发的情况,一般队列很快就会满的,满了后也会自动推送。默认为1秒。
LogSpans 是否把 Log 也推送,span 中可以携带一些日志信息。
LocalAgentHostPort 要推送到的 Jaeger agent,默认端口 6831,是 Jaeger 接收压缩格式的 thrift 协议的数据端口。
CollectorEndpoint 要推送到的 Jaeger Collector,用 Collector 就不用 agent 了。
例如通过 http 上传 trace:
据黑洞大佬的提示,HTTP 走的就是 thrift,而 gRPC 是 .NET 特供,所以 reporter 格式只有一种,而且填写 CollectorEndpoint,我们注意要填写完整的信息。
完整代码测试:
运行后输出结果:
打开 Jaeger UI,可以看到已经推送完毕(http://127.0.0.1:16686)。
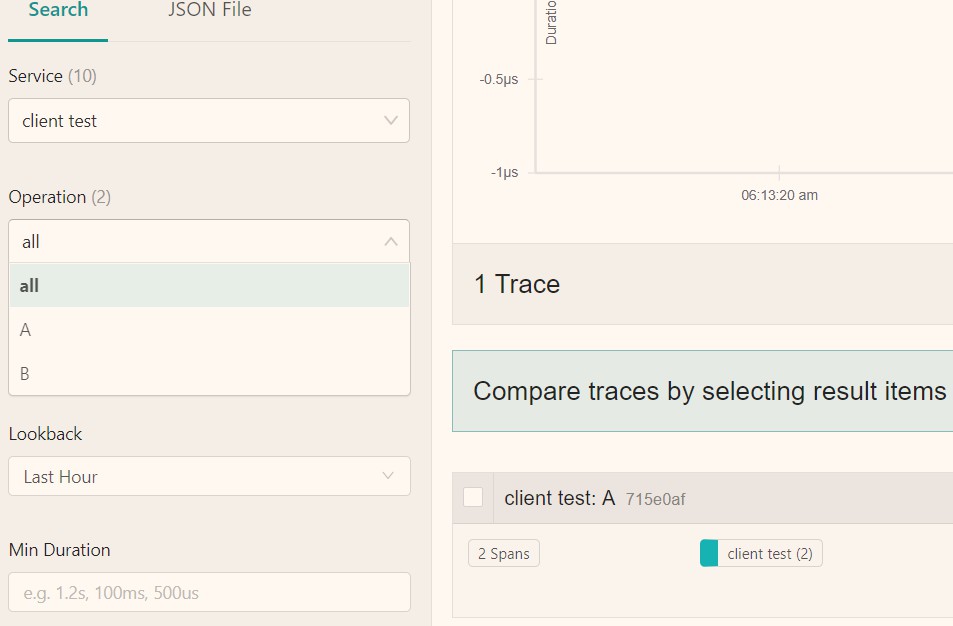
这时,我们可以抽象代码代码示例:
这样可以复用代码,调用函数创建一个新的 tracer。这个记下来,后面要用。
分布式系统与span
前面介绍了如何配置 tracer 、推送数据到 Jaeger Collector,接下来我们聊一下 Span。请看图。
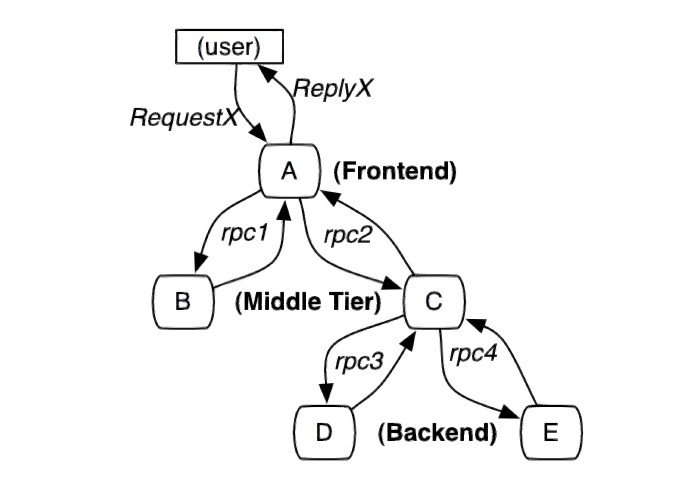
下图是一个由用户 X 请求发起的,穿过多个服务的分布式系统,A、B、C、D、E 表示不同的子系统或处理过程。
在这个图中, A 是前端,B、C 是中间层、D、E 是 C 的后端。这些子系统通过 rpc 协议连接,例如 gRPC。
一个简单实用的分布式链路追踪系统的实现,就是对服务器上每一次请求以及响应收集跟踪标识符(message identifiers)和时间戳(timestamped events)。
这里,我们只需要记住,从 A 开始,A 需要依赖多个服务才能完成任务,每个服务可能是一个进程,也可能是一个进程中的另一个函数。这个要看你代码是怎么写的。后面会详细说一下如何定义这种关系,现在大概了解一下即可。
怎么调、怎么传
如果有了解过 Jaeger 或读过 分布式链路追踪框架的基本实现原理 ,那么已经大概了解的 Jaeger 的工作原理。
jaeger 是分布式链路追踪工具,如果不用在跨进程上,那么 Jaeger 就失去了意义。而微服务中跨进程调用,一般有 HTTP 和 gRPC 两种,下面将来讲解如何在 HTTP、gPRC 调用中传递 Jaeger 的 上下文。
HTTP,跨进程追踪
A、B 两个进程,A 通过 HTTP 调用 B 时,通过 Http Header 携带 trace 信息(称为上下文),然后 B 进程接收后,解析出来,在创建 trace 时跟传递而来的 上下文关联起来。
injectextract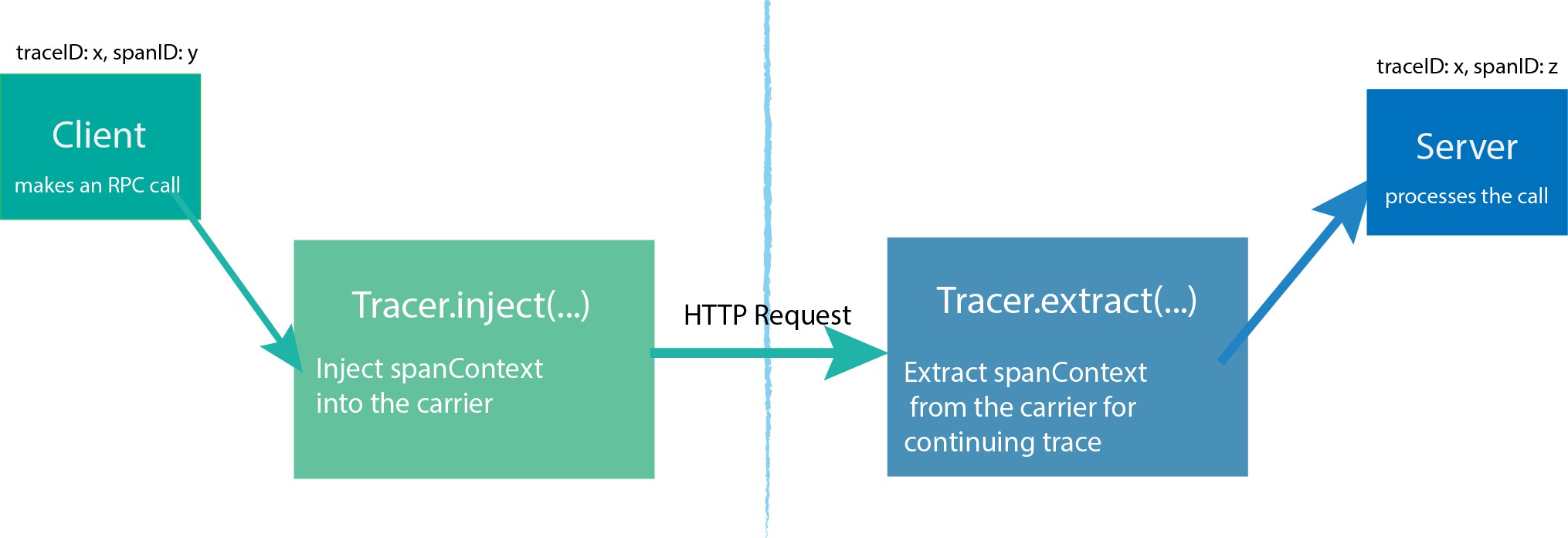
这里我们分为两步,第一步从 A 进程中传递上下文信息到 B 进程,为了方便演示已经实践,我们使用 client-webserver 的形式,编写代码。
客户端
在 A 进程新建一个方法:
CreateTracermain 函数改成:
Web 服务端
服务端我们使用 gin 来搭建。
go get -u github.com/gin-gonic/gin创建一个函数,该函数可以从创建一个 tracer,并且继承其它进程传递过来的上下文信息。
为了解析 HTTP 传递而来的 span 上下文,我们需要通过中间件来解析了处理一些细节。
别忘记了 API 服务:
然后是 main 方法:
分别启动 webserver、client,会发现打印日志。并且打开 jaerger ui 界面,会出现相关的追踪信息。

Tag 、 Log 和 Ref
Jaeger 的链路追踪中,可以携带 Tag 和 Log,他们都是键值对的形式:
ext.xxxxext.xxx.Set()前面写示例的时候忘记把日志也加一下了。。。日志其实很简单的,通过 span 对象调用函数即可设置。
示例(在中间件里面加一下):
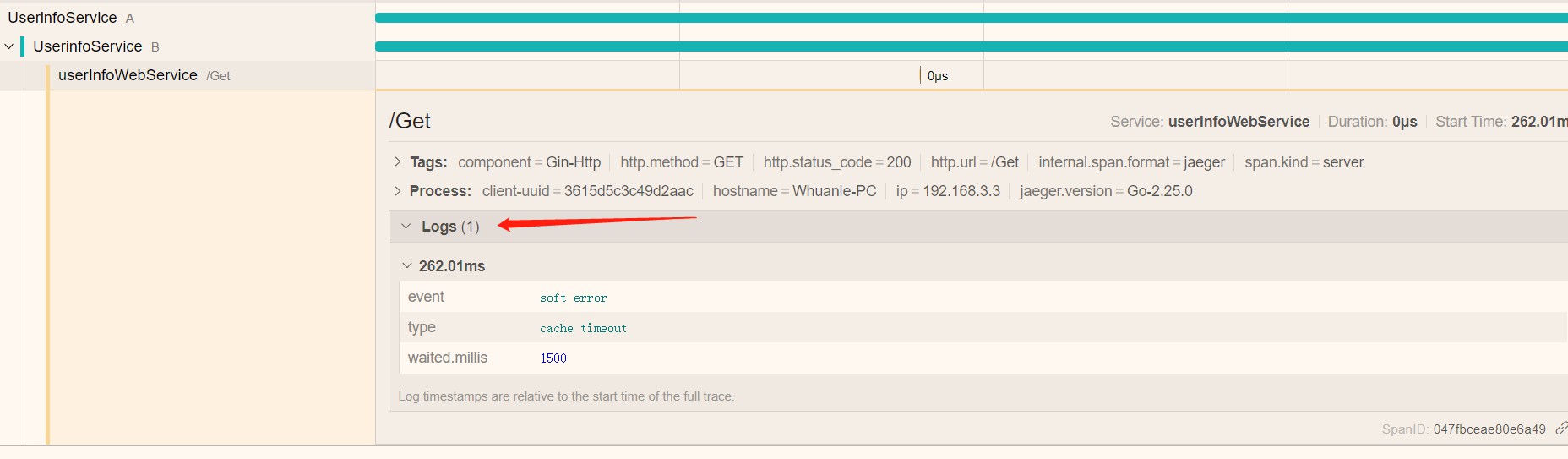
ref 就是多个 span 之间的关系。span 可以是跨进程的,也可以是一个进程内的不同函数中的。
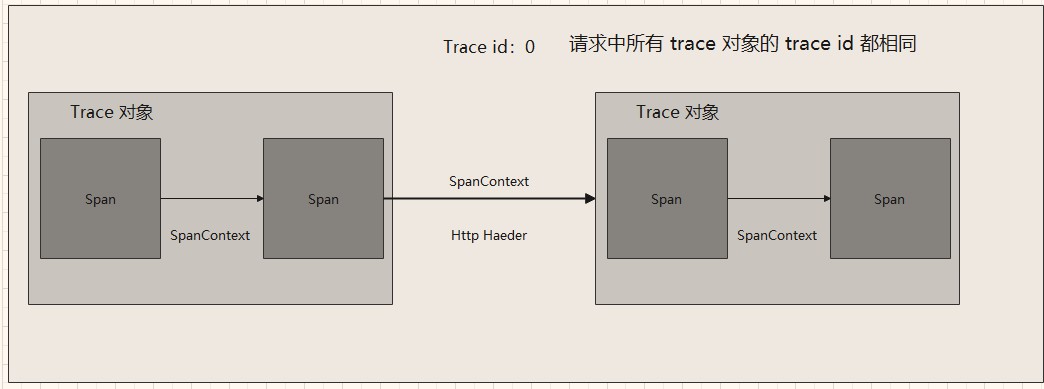
其中 span 的依赖关系表示示例:
spanID 为其依赖的父 span。
可以看下面这张图。
一个进程中的 tracer 可以包装一些代码和操作,为多个 span 生成一些信息,或创建父子关系。
而 远程请求中传递的是 SpanContext,传递后,远程服务也创建新的 tracer,然后从 SpanContext 生成 span 依赖关系。
子 span 中,其 reference 列表中,会带有 父 span 的 span id。
到此这篇关于Jaeger Client Go入门并实现链路追踪的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持脚本之家。