
目录
作为一个算法工程师无可避免的会给领导或者客户展示算法应用和效果,一个比较直观的方法就是制作一个比较简单的http页面,可以远程访问同时能够比较直观的展示出相关算法的效果之类的。这样使用一个美观的网页的形式,我认为还是比较有逼格的。假设前提,一般都假设算法人员开发前后端和前端的能力都欠佳,或者并不想投入太多的精力去搞一个比较好看的前端页面,那么我们就希望有一个功能能够快速实现算法Demo展示的精美页面,学习成本低、实现简单同时做出的页面也比较好看——称之为“最佳实践”。
一、streamlit——简单的单次交互前端页面我个人认为非常好的一个工具就是streamlit,这个是在知乎上看文章,别人推荐的,这里我自己做一个实现和总结。这个工具的能够实现大部分CV和NLP算法和数据工程师demo的展示,具体的一些example,可以去streamlit官网查看。下面就用我开发的一个文本分类数据标注检测小工具来展示一下streamlit的页面效果。
实现需求:上传一个含有文本和标注label的Excel文件;按照相似度阈值,把不同类别之间的可能存在标注冲突的文本理出来。
首先效果如下
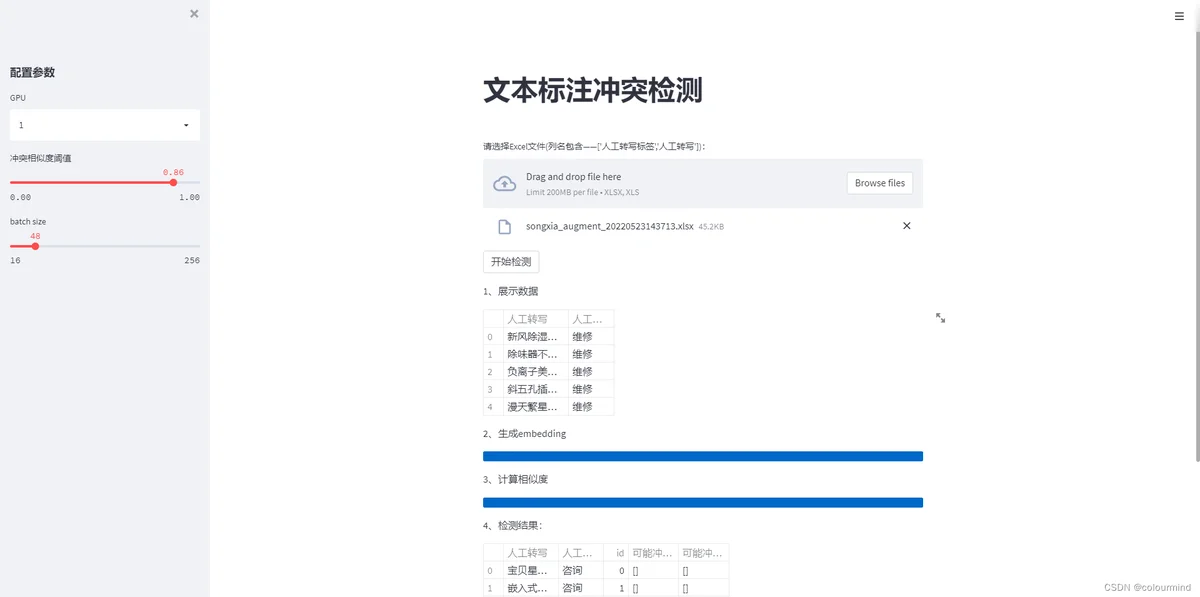
视频演示
代码如下(模型相关代码和功能忽视这里没有给出):
import streamlit as st
import pandas as pd
from transformers import BertTokenizer,BertConfig
from model.sentence_bert import SentenceBert
import torch
from tqdm import tqdm
from data_reader.dataReader_nopairs import DataReaderNopairs
from torch.utils.data import DataLoader
import os
import datetime
def compute_simi(query_id,temp_ids,embeddings,device,topn=10):
q_embedding = embeddings[query_id:query_id+1]
ids = torch.tensor(temp_ids,dtype=torch.long).to(device)
match_embeddings = torch.index_select(embeddings,0,ids)
dist = torch.mul(q_embedding,match_embeddings)
q_len = torch.norm(q_embedding,dim=1)
lengths = torch.norm(match_embeddings,dim=1)
cos = torch.sum(dist,dim=1)/(q_len*lengths)
topk = torch.topk(cos, topn)
return topk
def embedding(dataloader,model,device):
vectors = []
bar = st.progress(0)
interval = 100/len(dataloader)
for step ,batch in tqdm(enumerate(dataloader),desc='embedding'):
batch = [t.to(device) for t in batch]
inputs = {'input_ids': batch[0], 'attention_mask': batch[1], 'token_type_ids': batch[2]}
embedding = model.encoding(inputs)
vectors.append(embedding)
bar.progress(min(int((step+1)*interval),100))
vectors = torch.cat(vectors,dim=0)
return vectors
@st.cache
def convert_df(df):
# IMPORTANT: Cache the conversion to prevent computation on every return
return df.to_csv().encode('utf-8')
if __name__ == '__main__':
st.markdown(
"""
# 文本标注冲突检测
"""
)
st.markdown(
"""
"""
)
st.markdown(
"""
"""
)
st.sidebar.subheader("配置参数")
gpu_num = st.sidebar.selectbox(label='GPU', options=['0', '1'])
threshold = st.sidebar.slider("冲突相似度阈值",min_value=0.0, max_value=1.0, value=0.90, step=0.01)
bs = st.sidebar.slider("batch size",min_value= 16, max_value=256, value=64,step=16)
os.environ['CUDA_VISIBLE_DEVICES'] = gpu_num
task_type = "classification"
# task_type = "regression"
pretrained = './output/classification/75W_SBert_best_weikong_shanghai_ningbo_2021-11-30'
tokenizer = BertTokenizer.from_pretrained(pretrained)
config = BertConfig.from_pretrained(pretrained)
device = "cuda" if torch.cuda.is_available() else "cpu"
max_len = 64
model = SentenceBert.from_pretrained(config=config, pretrained_model_name_or_path=pretrained, max_len=max_len,
tokenizer=tokenizer, device=device, task_type=task_type)
model.to(device)
uploaded_file = st.file_uploader("请选择Excel文件(列名包含——['人工转写标签','人工转写']):", accept_multiple_files=False, type=["xlsx", "xls"])
if uploaded_file is not None and st.button("开始检测"):
df = pd.read_excel(uploaded_file.read())
assert '人工转写标签' in df.columns and '人工转写' in df.columns
st.markdown('1、展示数据')
st.dataframe(df[0:5])
df.sort_values(by=['人工转写标签'], kind='mergesort', inplace=True)
df.reset_index(drop=True, inplace=True)
df['id'] = range(len(df))
texts = df['人工转写'].values.tolist()
label_df = df[['人工转写标签']].copy()
label_df.drop_duplicates(keep='first', inplace=True)
label_set = label_df['人工转写标签'].values.tolist()
inside_data = DataReaderNopairs(tokenizer=tokenizer, texts=texts, max_len=64)
inside_dataloader = DataLoader(dataset=inside_data, shuffle=False, batch_size= bs)
st.markdown('2、生成embedding')
embeddings = embedding(inside_dataloader, model, device)
del inside_dataloader
del inside_data
conflict_labels = []
conflict_texts = []
st.markdown('3、计算相似度')
bar = st.progress(0)
interval = 100/len(label_set)
for step,label in tqdm(enumerate(label_set), desc='filter'):
temp_df = df[df['人工转写标签'] != label].copy()
temp_ids = temp_df['id'].values.tolist()
temp_df.reset_index(drop=True, inplace=True)
query_ids = df[df['人工转写标签'] == label]['id'].values.tolist()
for query_id in query_ids:
topk = compute_simi(query_id, temp_ids, embeddings, device, topn=5)
indices = topk.indices.data.tolist()
simis = topk.values.data.tolist()
save_labels = []
save_texts = []
for index, simi in zip(indices, simis):
if simi > threshold:
save_labels.append(temp_df.loc[index]['人工转写标签'])
save_texts.append(temp_df.loc[index]['人工转写'])
conflict_labels.append(save_labels)
conflict_texts.append(save_texts)
bar.progress(min(int((step+1)*interval),100))
del embeddings
torch.cuda.empty_cache()
df['可能冲突的文本'] = conflict_texts
df['可能冲突的标注'] = conflict_labels
st.markdown(
"""
4、检测结果:
"""
)
st.dataframe(df[0:5])
time_str = datetime.datetime.now().strftime("%Y-%m-%d_%H_%M")
file_path = "filter/" + time_str + "_"+ str(threshold) + '.csv'
df.to_csv(file_path, index=False)
csv = convert_df(df)
file_name = 'filter_'+ time_str + "_"+ str(threshold) + '.csv'
st.download_button(
label="Download result as CSV",
data= csv,
file_name= file_name,
mime='text/csv',
)
del conflict_texts
del conflict_labels
st.stop()
忽视上面代码中的模型和相似度计算代码,主要是关注streamlit相关的API
st.markdown(
"""
# 文本标注冲突检测
"""
)
st.markdown(
"""
"""
)
st.markdown(
"""
"""
)
st.sidebar.subheader("配置参数")
st.file_uploader("请选择Excel文件(列名包含——['人工转写标签','人工转写']):", accept_multiple_files=False, type=["xlsx", "xls"])
st.markdown('1、展示数据')
#DataFrame数据展示
st.dataframe(df[0:5])
# 进度条
bar = st.progress(0)
interval = 100/len(label_set)
for step,label in tqdm(enumerate(label_set), desc='filter'):
......
bar.progress(min(int((step+1)*interval),100))
st.download_button(
label="Download result as CSV",
data= csv,
file_name= file_name,
mime='text/csv',
)
页面比较美观,比单独一个不含CSS的页面好看很多;同时功能也比较完备,页边栏、标题titile等、文件上传和下载、数据表格展示,代码运行过程进度条等,花里胡哨的哈哈哈。代码很简单就不做详细的说明和注释了。另一方面,只需要写想要的效果和模块逻辑,streamlit会自己给你生成前端效果。一般而言,只要不是那种需要不断多轮交互来完成的demo——如聊天机器人复杂的逻辑,streamlit都能完成单轮交互的演示页面——NLP领域的NER、翻译、文本生成、分类、文本相似等等demo页面展示都是可以胜任的,这个真的对于前后端开发能力不是很强的算法工程师或者不想投太多精力给demo页面的算法工程是的一大福音呀。
二、多次交互对话式页面这种类似微信聊天界面的前端,稍微比较复杂,使用上述前端页面工具streamlit很难实现这样的逻辑(本人尝试过实现,奈何水平比较菜,实现不出来),要实现这种对话式机器人,就需要前后端一起搭建一个后端http服务和前端网页APP了。
首先直接上图,看一看网页聊天机器人的效果:
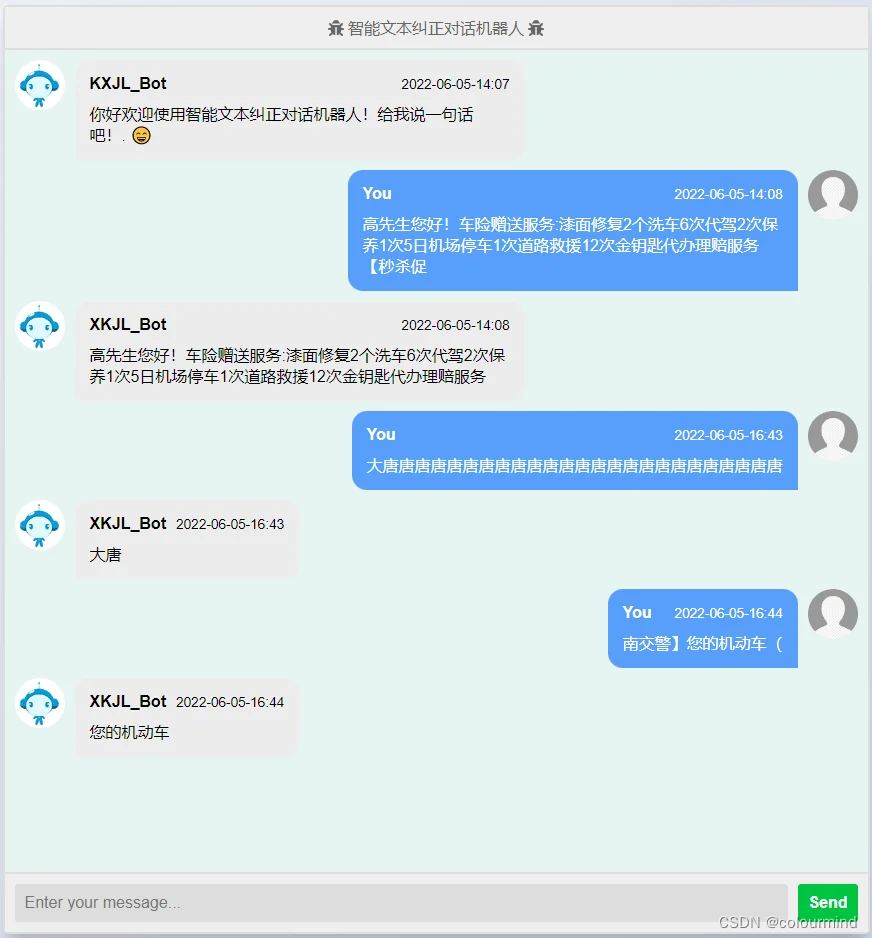
大概就是这样的一个网页版对话APP,虽然页面比较简单,但是功能上完全满足一个demo演示的需要。如何搭建这样一个简单的对话APP?下面使用python的flask、sanic框架和golang以及前端资源一起展示一下。
1、前端资源
首先看看页面的主要资源,主要是html+js。声明一下,这个前端资源不是我写的(具体的地址找不到了),是从网上找出来后,修改了一些文字和图片等等,算是做一个分享。
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>KXJLGPT2Bot</title>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<link rel="stylesheet" href="{{ url_for('static', filename='styles/style.css') }}">
<script src="{{ url_for('static', filename='js/jquery.min.js') }}"></script>
</head>
<body>
<!-- partial:index.partial.html -->
<section class="msger">
<header class="msger-header">
<div class="msger-header-title">
<i class="fas fa-bug"></i> 科讯嘉联智能客服对话机器人 <i class="fas fa-bug"></i>
</div>
</header>
<main class="msger-chat">
<div class="msg left-msg">
<div class="msg-img" style="background-image: url(/static/img/bot.png)"></div>
<div class="msg-bubble">
<div class="msg-info">
<div class="msg-info-name">KXJL_Bot</div>
<div id="msg-info-time_0" class="msg-info-time"></div>
</div>
<div class="msg-text">
你好欢迎使用灵珠聊天机器人!给我说一句话吧!. 😄
</div>
</div>
</div>
</main>
<form class="msger-inputarea">
<input type="text" class="msger-input" id="textInput" placeholder="Enter your message...">
<button type="submit" class="msger-send-btn">Send</button>
</form>
</section>
<!-- partial -->
<script src='https://use.fontawesome.com/releases/v5.0.13/js/all.js'></script>
<script src="{{ url_for('static', filename='js/index.js') }}"></script>
</body>
</html>主要是声明了一些页面元素,js、css等静态资源的地址;注意到:
src="{{ url_for('static', filename='js/jquery.min.js') }}这种写法url_for在某些语言下或者某些配置不对的情况下,是有问题的,需要换成当前项目根目录下的相对路径
<script src="./static/js/index.js"></script>js文件
需要一个js库——jquery.min.js这个是jquery下载的;另外的页面上的一些逻辑需要在index.js中实现:
// 渲染第一个msg-info-time_0日期
document.getElementById("msg-info-time_0").innerHTML = formatDate(new Date());
const msgerForm = get(".msger-inputarea");
const msgerInput = get(".msger-input");
const msgerChat = get(".msger-chat");
// Icons made by Freepik from www.flaticon.com
const BOT_IMG = "static/img/bot.png";
const PERSON_IMG = "static/img/user.png";
const BOT_NAME = "XKJL_Bot";
const PERSON_NAME = "You";
// 事件监听器页面上的submit按钮点击以后就执行逻辑
msgerForm.addEventListener("submit", event => {
event.preventDefault();
const msgText = msgerInput.value;
if (!msgText) return;
appendMessage(PERSON_NAME, PERSON_IMG, "right", msgText);
msgerInput.value = "";
botResponse(msgText);
});
function appendMessage(name, img, side, text) {
// Simple solution for small apps
const msgHTML = `
<div class="msg ${side}-msg">
<div class="msg-img" style="background-image: url(${img})"></div>
<div class="msg-bubble">
<div class="msg-info">
<div class="msg-info-name">${name}</div>
<div class="msg-info-time">${formatDate(new Date())}</div>
</div>
<div class="msg-text">${text}</div>
</div>
</div>
`;
// 页面上插入一个新的对话文字泡
msgerChat.insertAdjacentHTML("beforeend", msgHTML);
//设置滚动条的位置
msgerChat.scrollTop += 500;
}
// 机器人的响应
function botResponse(rawText) {
// Bot Response get请求 得到结果后 调用appendMessage()函数填充到页面
$.get("/get", { msg: rawText }).done(function (data) {
console.log(rawText);
console.log(data);
const msgText = data;
appendMessage(BOT_NAME, BOT_IMG, "left", msgText);
});
}
// Utils
function get(selector, root = document) {
return root.querySelector(selector);
}
function formatDate(date) {
const y = "0" + date.getFullYear();
const m = "0" + date.getMonth();
const d = "0" + date.getDay();
const h = "0" + date.getHours();
const mi = "0" + date.getMinutes();
return `${y.slice(-4)}-${m.slice(-2)}-${d.slice(-2)}-${h.slice(-2)}:${mi.slice(-2)}`;
}
以上js代码大致的逻辑给出了注释
css
:root {
--body-bg: linear-gradient(135deg, #f5f7fa 0%, #c3cfe2 100%);
--msger-bg: #fff;
--border: 2px solid #ddd;
--left-msg-bg: #ececec;
--right-msg-bg: #579ffb;
}
html {
box-sizing: border-box;
}
*,
*:before,
*:after {
margin: 0;
padding: 0;
box-sizing: inherit;
}
body {
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
background-image: var(--body-bg);
font-family: Helvetica, sans-serif;
}
.msger {
display: flex;
flex-flow: column wrap;
justify-content: space-between;
width: 100%;
max-width: 867px;
margin: 25px 10px;
height: calc(100% - 50px);
border: var(--border);
border-radius: 5px;
background: var(--msger-bg);
box-shadow: 0 15px 15px -5px rgba(0, 0, 0, 0.2);
}
.msger-header {
/* display: flex; */
font-size: medium;
justify-content: space-between;
padding: 10px;
text-align: center;
border-bottom: var(--border);
background: #eee;
color: #666;
}
.msger-chat {
flex: 1;
overflow-y: auto;
padding: 10px;
}
.msger-chat::-webkit-scrollbar {
width: 6px;
}
.msger-chat::-webkit-scrollbar-track {
background: #ddd;
}
.msger-chat::-webkit-scrollbar-thumb {
background: #bdbdbd;
}
.msg {
display: flex;
align-items: flex-start;
margin-bottom: 10px;
}
.msg-img {
width: 50px;
height: 50px;
margin-right: 10px;
background: #ddd;
background-repeat: no-repeat;
background-position: center;
background-size: cover;
border-radius: 50%;
}
.msg-bubble {
max-width: 450px;
padding: 15px;
border-radius: 15px;
background: var(--left-msg-bg);
}
.msg-info {
display: flex;
justify-content: space-between;
align-items: center;
margin-bottom: 10px;
}
.msg-info-name {
margin-right: 10px;
font-weight: bold;
}
.msg-info-time {
font-size: 0.85em;
}
.left-msg .msg-bubble {
border-bottom-left-radius: 0;
}
.right-msg {
flex-direction: row-reverse;
}
.right-msg .msg-bubble {
background: var(--right-msg-bg);
color: #fff;
border-bottom-right-radius: 0;
}
.right-msg .msg-img {
margin: 0 0 0 10px;
}
.msger-inputarea {
display: flex;
padding: 10px;
border-top: var(--border);
background: #eee;
}
.msger-inputarea * {
padding: 10px;
border: none;
border-radius: 3px;
font-size: 1em;
}
.msger-input {
flex: 1;
background: #ddd;
}
.msger-send-btn {
margin-left: 10px;
background: rgb(0, 196, 65);
color: #fff;
font-weight: bold;
cursor: pointer;
transition: background 0.23s;
}
.msger-send-btn:hover {
background: rgb(0, 180, 50);
}
.msger-chat {
background-color: #fcfcfe;
background-image: url("/static/img/background.jpg");
background-size: cover;
}2、后端服务器
后端服务器搭建,这里演示三种不同的方案。
a、flask+gevent.pywsgi.WSGIServer
一般这种对话demo,大多是文本对话机器人,需要记住历史记录,所以多个人同时访问的时候,需要区分清楚,需要用到flask的session功能
from flask import Flask, request, render_template,session
from gevent.pywsgi import WSGIServer
from tools.log import Logger
import secrets
"""
flask实现一个简单的http服务器,比较简单
Session保存session_id
静态资源啥的可以直接使用
"""
contents = {}
replays = {}
def main():
app = Flask(__name__)
app.config["SECRET_KEY"] = 'TPmi4aLWRbyVq8zu9v82dWYW1'
app.config['PERMANENT_SESSION_LIFETIME'] = timedelta(seconds=300)
app.static_folder = 'static'
@app.route("/")
def home():
global contents
global replays
if session.get("sid"):
logger.info('delete session')
del session["sid"]
session_id = secrets.token_urlsafe(24)
logger.info('session_id %s',session_id)
contents[session_id] = ""
replays[session_id] = ""
session['sid'] = session_id
return render_template("index.html")
@app.route("/get")
def get_bot_response():
global contents
global replays
sid = session.get('sid')
userText = request.args.get('msg')
contents[sid] += userText
ts = time.time()
logger.info('session_id %s contents get_bot_response: %s'%(sid, contents[sid]))
res_test = text_single_generate(model, tokenizer, args, contents[sid],logger)
te = time.time()
logger.info('inferece time is:%.4f' % (te - ts))
contents[sid] += '[SEP]'+ res_test + '[SEP]'
replays[sid] = res_test
return str(res_test)
WSGIServer(('172.20.10.221', 5555), app).serve_forever()把flask的服务化代码给出来了,其他的自然语言处理算法相关的代码没有给出,需要注意的是:
1、设计了全局的字典来保存不同访问者的历史记录
2、初次访问页面会给一个初始的session_id,secrets.token_urlsafe(24)生成了24位的安全字符串;刷新页面,session_id会重置;对话过程中不会重置
3、@app.route()路由一定要写对和前端js中的get请求相适应。
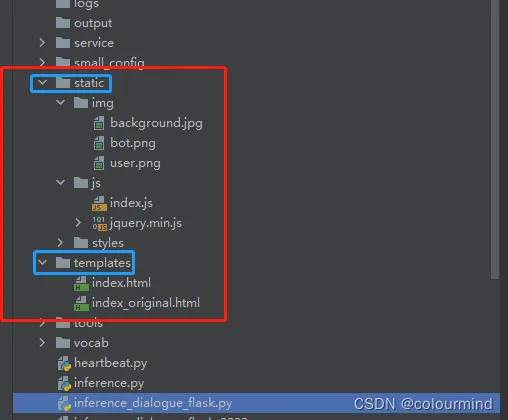
4、静态资源的文件夹一定要为static,代码中app.static_folder = 'static' 会根据这个参数来寻找静态资源;render_template("index.html")会在templates目录下加载html文件
静态页面的路径如下:
b、sanic
sanic的优势在于速度更快,性能更好,可以设置参数进程参数,起多个进程;可能再使用gpu推理的时候有点复杂;我使用sanic的时候一般算法都是使用CPU推理的:gpu推理的时候需要在每个进程内重新初始化模型。需要用到的包
jinja2
sanic
代码如下:
import secrets
from sanic import Sanic
from sanic.response import text
from sanic import request
from sanic_common import JinJaTemplate
def main():
# sanic的代码
app = Sanic(__name__)
# 静态资源(CSS,JS等)注册url————路径
app.static('/static', './static')
template = JinJaTemplate().template_render_sync
logger.info('app finished')
@app.route("/")
def home(request):
t = template("index.html")
if request.cookies.get('sid'):
logger.info('delete session')
del t.cookies['sid']
session_id = secrets.token_urlsafe(24)
logger.info('session_id %s',session_id)
t.cookies['sid'] = session_id
return t
@app.route("/get")
def get_bot_response(request):
global contents
session_id = request.cookies.get('sid')
logger.info('now session_id %s', session_id)
userText = request.args.get('msg')
contents += userText
ts = time.time()
logger.info('contents get_bot_response: %s' % (contents))
res_test = "好的你好"
te = time.time()
logger.info('inferece time is:%.4f' % (te - ts))
contents += '[SEP]' + res_test + '[SEP]'
r = response.text(res_test)
r.cookies['sid'] = session_id
return r
serverIp = "*.*.*.*"
serverPort = 1111
app.run(host=serverIp, port=serverPort, debug=True, workers=4)看一下进程数
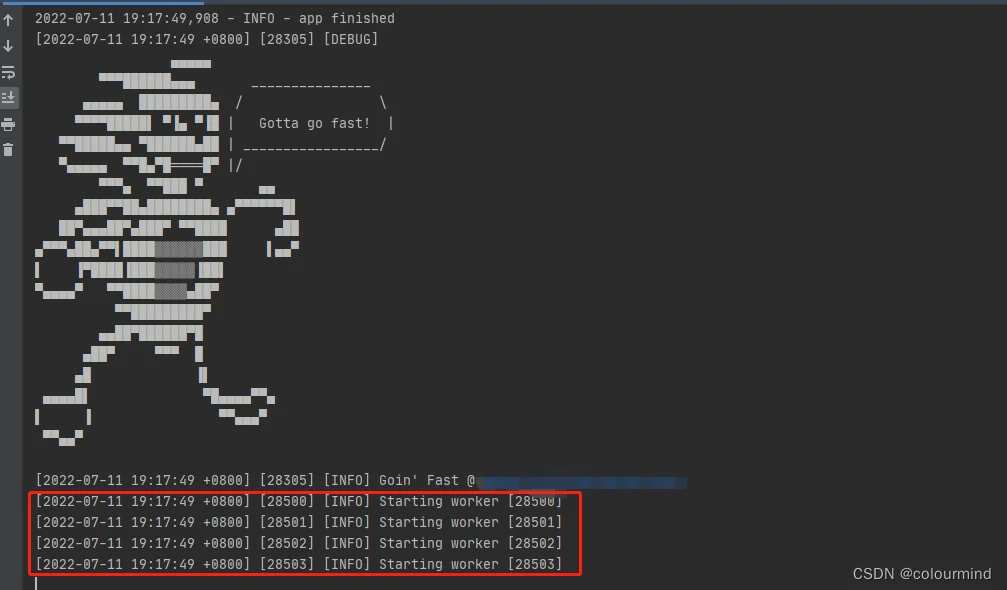
sanic程序跑起来如下,workers=4,就启动了4个子进程
整体服务代码和flask不同的是,加载html复杂要更复杂,需要结合jinja2才能实现html的加载;同时要实现上面的类似session_id功能也稍微麻烦一点,需要用到cookies。
jinja2 加载html
from jinja2 import Environment, select_autoescape, FileSystemLoader
from sanic.response import html
import sys
class JinJaTemplate(object):
def __init__(self):
self.template_paths = ["./templates"]
self.env_sync = Environment(loader=FileSystemLoader(self.template_paths),
autoescape=select_autoescape(['html', 'xml', 'tpl']),
enable_async=False)
self.enable_async_flag = sys.version_info >= (3, 6)
self.env_async = Environment(loader=FileSystemLoader(self.template_paths),
autoescape=select_autoescape(['html', 'xml', 'tpl']),
enable_async=self.enable_async_flag)
def template_render_sync(self, template_file, **kwargs):
template = self.env_sync.get_template(template_file)
rendered_template = template.render(kwargs)
return html(rendered_template)jinja2加载html模板解析等;然后sanic.response的html把解析到的html模板封装为response;
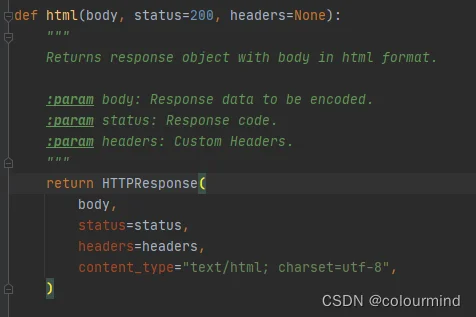
cookies 区别不同用户
html()的返回对象HTTPResponse()是有cookies,同时sanic的request也带有cookies。浏览器刷新的时候,cookies就更新了;在请求页面的时候做cookies的更新和设置,初始的时候t.cookies是一个空字典{},通过t.cookies['sid']设置其中的键值。
t = template("index.html")
if request.cookies.get('sid'):
logger.info('delete session')
del t.cookies['sid']
session_id = secrets.token_urlsafe(24)
logger.info('session_id %s',session_id)
t.cookies['sid'] = session_id
return tget请求的时候(页面没有刷新),这个时候cookies不会更新,会把之前的cookies中的sid一直带下去,直到浏览器刷新或者关闭重启。当然get请求的时候也需要为response设置cookies的sid值。
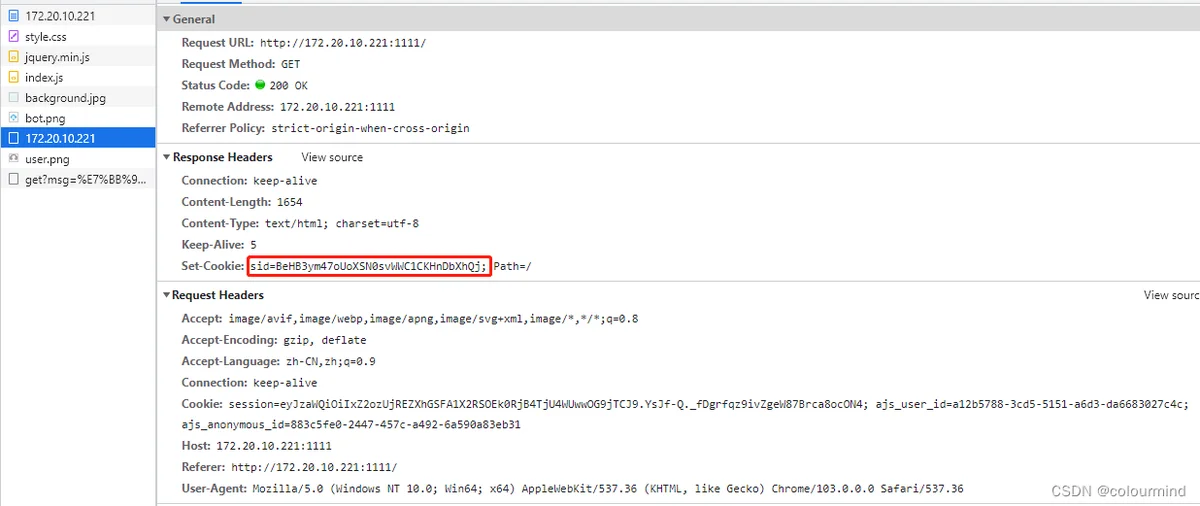
首次访问页面,response 返回的时候设置 sid=BeHB3ym47oUoXSN0svWWC1CKHnDbXhQj
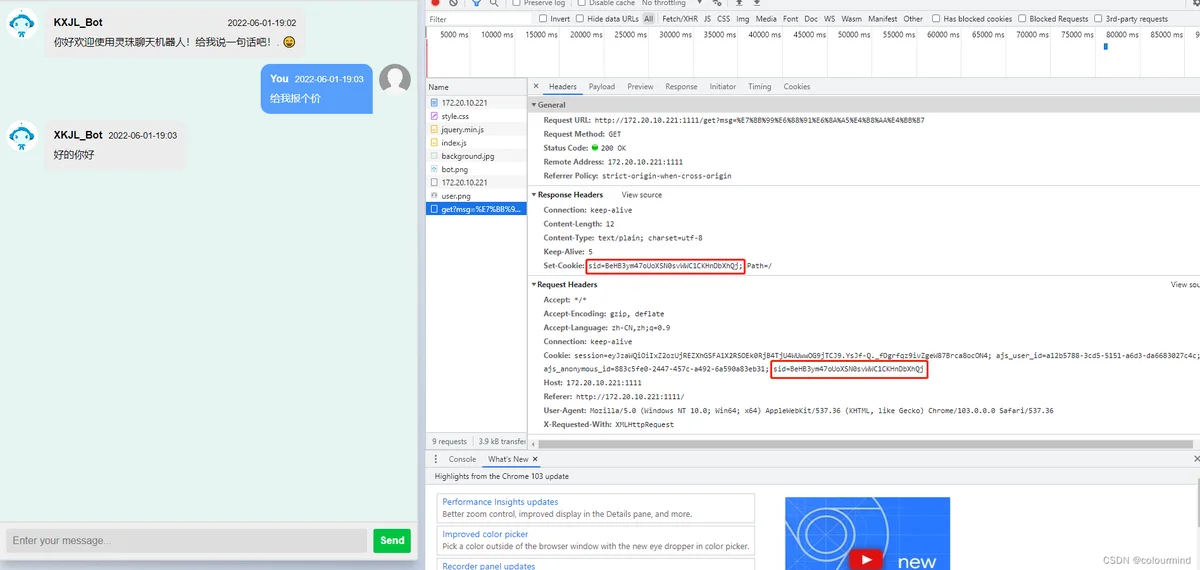
get请求机器人完成页面上的对话回答,可以看到response Header 和request Header中的sid值一样,也和首次访问页面的时候sid值一样。
3、golang
golang中也有很多web框架,本人不熟悉,就使用golang内置的库和函数来完成服务端的搭建。主要代码如下:
package main
import (
"chat_web_demo/config"
"encoding/json"
"fmt"
"io/ioutil"
"log"
"net/http"
"regexp"
"strconv"
"strings"
"unicode"
)
type httpServer struct {
}
type Request struct {
Msg string `json:"msg"`
}
func NueGenerationPostProcess(genInfo string) string {
return "你好"
}
func (GetInformHandler httpServer) ServeHTTP(w http.ResponseWriter, r *http.Request) {
query := r.URL.Query()
msg := query.Get("msg")
log.Println("msg:" + msg)
post_result := NueGenerationPostProcess(msg)
log.Println("post_result:" + post_result)
w.Write([]byte(post_result))
}
func main() {
// 启动静态资源文件服务
http.Handle("/static/", http.StripPrefix("/static/", http.FileServer(http.Dir("./static"))))
// 启动html文件服务
http.Handle("/", http.FileServer(http.Dir("./templates")))
//get接口服务 GetInformHandler需要重写ServeHTTP方法,http.HandleFunc不需要直接实现逻辑函数即可
var GetInformHandler httpServer
http.Handle("/get", GetInformHandler)
// http.HandleFunc("/nlp", GetNlp)
log.Println("服务IP:", config.Config().Server.Ip)
log.Println("服务端口:", config.Config().Server.Port)
log.Println("listening on port ", config.Config().Server.Port)
// tcp下启动监听和启动服务
err := http.ListenAndServe(config.Config().Server.Ip+":"+strconv.Itoa(config.Config().Server.Port), nil)
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}html的加载采用http.Handle("/", http.FileServer(http.Dir("templates")));注意其中http.FileServer(http.Dir("templates"))有的时候路由并不是"/"而是"/***"时,url的变化如下:
url:http://ip:port/templates
url:http://ip:port/***/templates
这个时候就需要使用http.StripPrefix()函数把拼接的前缀给去掉。
http.Handle("/***",http.StripPrefix("/***",http.FileServer(http.Dir("templates"))))
静态资源路径如下:
以上主要是对算法工程是demo用到的前端工具streamlit进行了一个展示;同时也对streamlit不能实现的比较复杂的demo(例如对话机器人的页面——多次交互,记录和展示历史信息)的前端资源从网上找到一个比较合适的资源进行了分享;最后也使用python两种不同的框架flask和Sanic以及golang语言等三种方法搭建了简单的后端服务。感觉差不多算法工程师需要web页面展示的demo以上方法全部都能满足。
参考文章: