
前言
结构体是包含多个字段的集合类型,用于将数据组合为记录。这样可以将与同一实体相关联的数据利落地封装到一个轻量的类型定义中,然后通过对该结构体类型定义方法来实现不同的行为。
struct
terraformTerraformResource输出结果
$ go run golang-struct-memory-allocation.go
==============================================================
结构体使用的总内存:d main.TerraformResource => [88]
==============================================================
结构体中的Cloud字段:d.Cloud string => [16]
结构体中的Name字段:d.Name string => [16]
结构体中的HaveDSL字段:d.HaveDSL bool => [1]
结构体中的PluginVersion字段:d.PluginVersion string => [16]
结构体中的ModuleVersionMajor字段:d.IsVersionControlled bool => [1]
结构体中的TerraformVersion字段:d.TerraformVersion string => [16]
结构体中的ModuleVersionMajor字段:d.ModuleVersionMajor int32 => [4]
TerraformResourceTerraformResource如下图所示:

为什么是88字节呢?16 +16 + 1 + 16 + 1+ 16 + 4 = 70 bytes,多出来的18字节是从哪来的?
涉及到结构体的内存分配时,总是会分配连续、字节对齐的内存志,字段按所定义的顺序进行内存分配和存储。这里的字节对齐表示连续的内存块按平台的字大小进行偏移排列。

TerraformResource.HaveDSLTerraformResource.isVersionControlledTerraformResource.ModuleVersionMajor所以重新计算一下:
数据占用字节 = 16字节 + 16字节 + 1字节 + 16字节 + 1字节 + 16字节 + 4字节 = 70字节
空白字节 = 7字节 + 7字节 + 4字节 = 18字节
总字节数 = 数据占用字节 + 空白字节 = 70字节 + 18字节 = 88字节
那如何修复这个问题呢?通过恰当地的数据结构对齐,我们可以这样来定义结构体:
使用优化后的结构体来运行同一段代码:
输出结果
$ go run golang-struct-memory-allocation.go
==============================================================
结构体使用的总内存:d main.TerraformResource => [72]
==============================================================
结构体中的Cloud字段:d.Cloud string => [16]
结构体中的Name字段:d.Name string => [16]
结构体中的HaveDSL字段:d.HaveDSL bool => [1]
结构体中的PluginVersion字段:d.PluginVersion string => [16]
结构体中的ModuleVersionMajor字段:d.IsVersionControlled bool => [1]
结构体中的TerraformVersion字段:d.TerraformVersion string => [16]
结构体中的ModuleVersionMajor字段:d.ModuleVersionMajor int32 => [4]
TerraformResource我们来看下在内存中是如何排列的:

仅仅是通过对结构体元素进行了一轮数据结构对齐我们就将所占用的内存由88字节降到了72字节,真是太棒了!!!
我们再来算一下
数据占用字节 = 16字节 + 16字节 + 16字节 + 16字节 +4字节 + 1 byte + 1字节 = 70字节
空白字节 = 2字节
总字节数 = 数据占用字节 + 空白字节 = 70字节 + 2字节 = 72字节
通过恰当的数据结构对齐不仅优化了内存占用,还优化了CPU读取周期,怎么做到的呢?
TerraformResource
但对优化后的结构体只需要读取9个字:
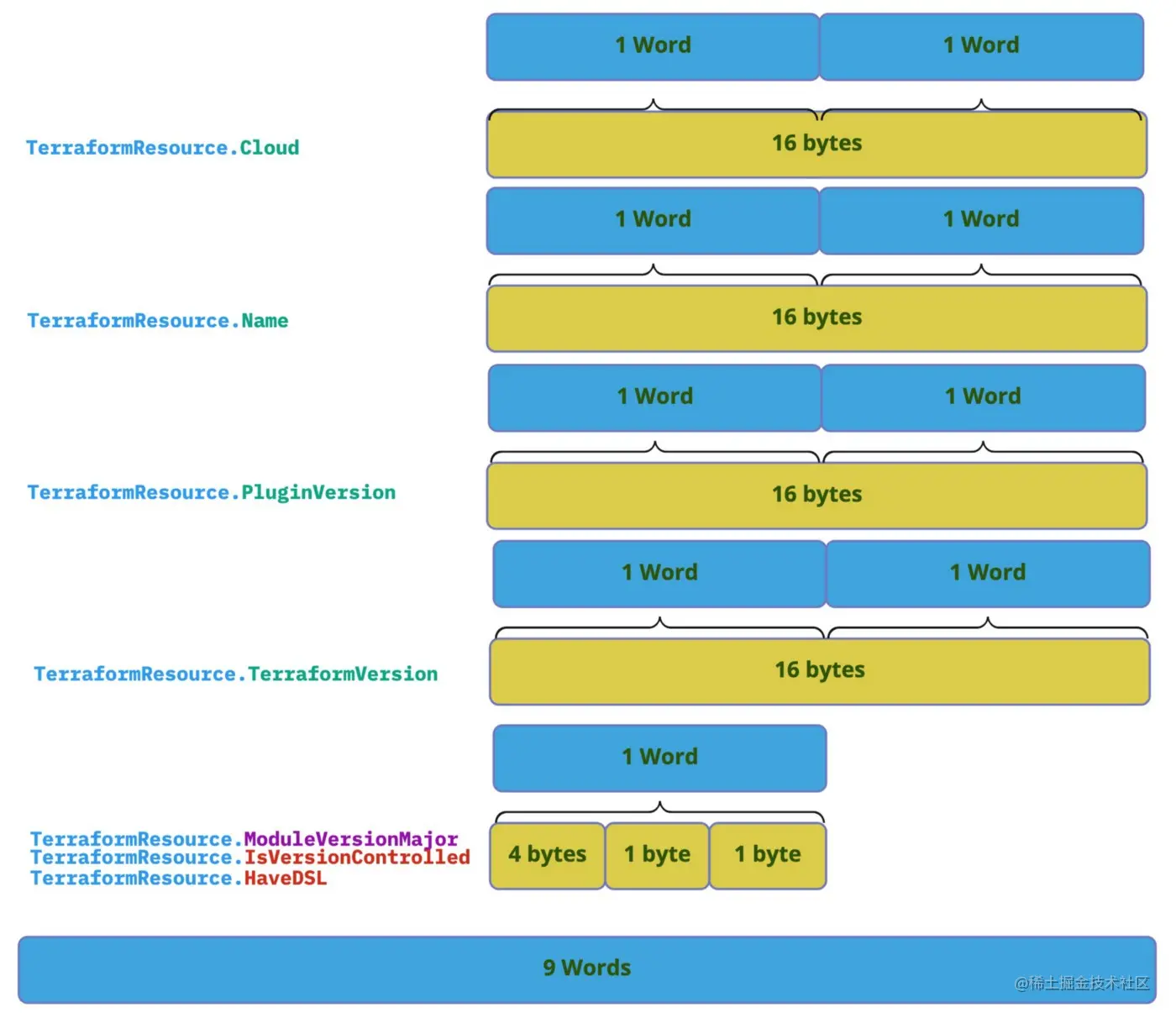
通过恰当地对结构体进行数据结构排序我们可以让内存分配和CPU 读取都变得高效。