
在golang中并没有class的概念,如果真要说起来就是struct了。
struct是一种自定义复杂的类型结构,可以包含多个字段(属性),可以定义方法,可以嵌套,而且struct是值类型。
与函数一样,struct如果要被外部访问到:结构体的名称和其中的字段首字母也需要大写。
声明
struct包含三种声明方式,如实例代码:
//定义一个学生结构体,有点类似其他语言的类
type Students struct {
isStudent bool
Name string
Age int
score int
}
//var student Students //声明方式1
//var student *Students = new(Students) //声明方式2
var student *Students = &Students{} //声明方式3
student.Name = "zhangsan"
student.isStudent = true //赋值
student.Age = 23
student.score = 90
fmt.Printf("struct声明:name=%s,isStudent=%t,age=%d,score=%d\n", student.Name, student.isStudent, student.Age, student.score)
(*student).isStudent = false
fmt.Printf("struct声明:name=%s,isStudent=%t,age=%d,score=%d\n", (*student).Name, (*student).isStudent, (*student).Age, (*student).score)
返回
struct声明:name=zhangsan,isStudent=true,age=23,score=90 struct声明:name=zhangsan,isStudent=false,age=23,score=90
值得注意的是,在go中(*student).与student.的两种访问形式的结果是一样的,区别在于后者是前者的简化版。
同时上面的声明方式2new的用法还是一样,返回指针,被分配的内存空间不需要自己释放,只管使用即可。
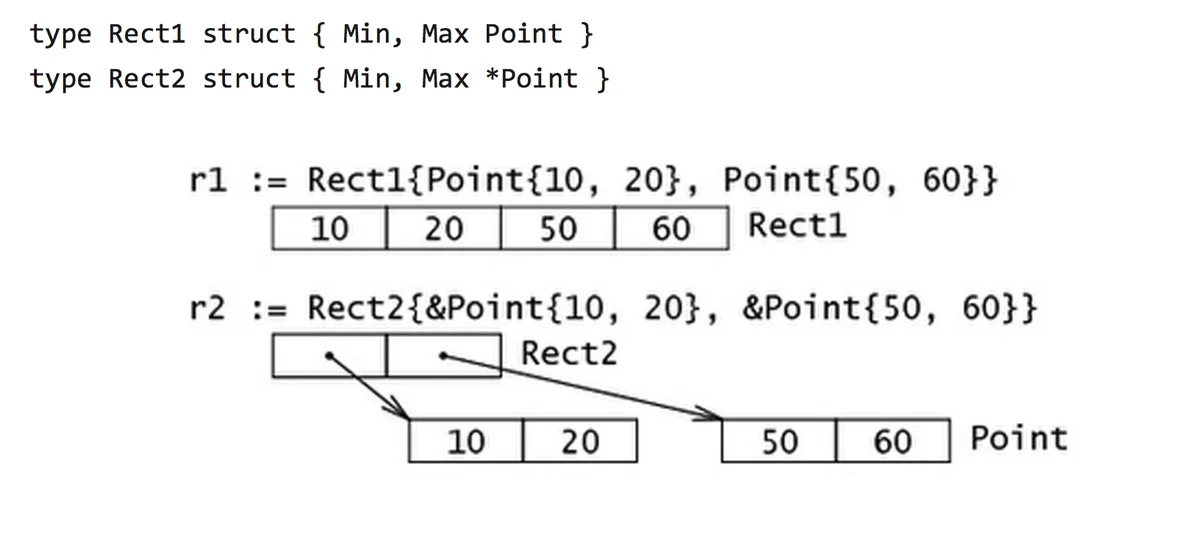
内存布局
struct的内存布局中的所有字段在内存里是连续的
type Students struct {
Name string
Age int
Score float32
}
var student Students
student.Name = "zhangsan"
student.Age = 23
student.Score = 90
fmt.Println(student)
fmt.Printf("Name:%p\n", &student.Name) //Name: 0xc00000c0 60
fmt.Printf("Age:%p\n", &student.Age) //Age: 0xc00000c0 70
fmt.Printf("Score:%p\n", &student.Score) //Score:0xc00000c0 78
返回
{zhangsan 23 90}
Name:0xc00000c0a0
Age: 0xc00000c0b0
Score:0xc00000c0b8
a0、b0、b8,由此可见,struct中的所有字段属性都是根据字节大小连续排列的。
初始化
三种初始化的方式,变量和指针:
type Students struct {
Name string
Age int
Score float32
}
var student = Students{
Name: "tom",
Age: 2,
}
var student2 Students
student2.Name = "zhangsan"
student2.Age = 23
student2.Score = 90
var student3 *Students = &Students{
Name: "tom",
Age: 2,
Score: 90.2,
}
fmt.Printf("初始化1:Name=%s,Age=%d,Score=%f\n", student.Name, student.Age, student.Score)
fmt.Printf("初始化2:Name=%s,Age=%d,Score=%f\n", student2.Name, student2.Age, student2.Score)
fmt.Printf("初始化3:Name=%s,Age=%d,Score=%.1f\n", student3.Name, student3.Age, student3.Score)
返回
初始化1:Name=tom,Age=2,Score=0.000000 初始化2:Name=zhangsan,Age=23,Score=90.000000 初始化3:Name=tom,Age=2,Score=90.2
与前面声明的一样,(*student).Name与student.Name是等同的,所以简便起见student.Name
链表
链表是每个节点包含下一个节点的地址(通常使用的是指针字段),这样把所有的节点串联起来,形成一个长度不固定、复杂的链式结构。
链表头:链表中的第一个节点
链表又分为单链表和双链表即循环单双链表:
单链表是每个节点只存在一个指针字段,只能从头向后走。
双链表是每个节点存在两个指针字段,一个指向后一个节点;另一个指向前一个节点。
循环单双链表是链表的尾节点指向链表头。

链表的常规操作:
链表尾部插入法:
type Students struct {
Name string
Age int
Score float32
next *Students
}
func() {
fmt.Println("链表尾部插入法:", )
//定义一个链表
//创建一个头节点
var head Students
head.Name = "head"
head.Age = 18
head.Score = 100
//定义一个尾节点
var student1 Students
student1.Name = "student1"
student1.Age = 18
student1.Score = 100
head.next = &student1
var student2 Students
student2.Name = "student2"
student2.Age = 18
student2.Score = 100
trans(&head) //传进去一个指向同一个内存空间的地址
student1.next = &student2
trans(&head) //传进去一个指向同一个内存空间的地址
}()
//模块化遍历链表
func trans(p *Students) {
for p != nil {
fmt.Println(*p)
if p.next == nil {
break
}
p = p.next
}
fmt.Println()
}
返回
链表尾部插入法:
{head 18 100 0xc00008c030}
{student1 18 100 <nil>}
{head 18 100 0xc00008c030}
{student1 18 100 0xc00008c060}
{student2 18 100 <nil>}
链表尾部遍历插入法:
type Students struct {
Name string
Age int
Score float32
next *Students
}
func() {
fmt.Println("链表尾部遍历插入法:", )
//定义一个链表
//创建一个头节点
var head Students
head.Name = "head"
head.Age = 18
head.Score = 100
insetTail(&head)
trans(&head)
}()
//尾部遍历插入链表
func insetTail(p *Students) {
var tail = p //记录尾节点,通过尾节点来新增节点
for i := 0; i < 10; i++ {
student := &Students{
Name: fmt.Sprintf("student%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
tail.next = student
tail = student //重新定义尾节点
}
}
返回
链表尾部遍历插入法:
{head 18 100 0xc000078180}
{student0 81 94.05091 0xc0000781b0}
{student1 47 43.77142 0xc0000781e0}
{student2 81 68.682304 0xc000078210}
{student3 25 15.651925 0xc000078240}
{student4 56 30.091187 0xc000078270}
{student5 94 81.36399 0xc0000782a0}
{student6 62 38.06572 0xc0000782d0}
{student7 28 46.888985 0xc000078300}
{student8 11 29.310184 0xc000078330}
{student9 37 21.855305 <nil>}
链表头不遍历插入法:
方式一:变量声明
//定义一个链表结构体
type Students struct {
Name string
Age int
Score float32
next *Students
}
func() {
fmt.Println("链表头部遍历插入法:", )
//定义一个链表
//创建一个头节点
var head Students //方式一
head.Name = "head"
head.Age = 18
head.Score = 100
for i := 0; i < 10; i++ {
student := Students{
Name: fmt.Sprintf("student%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
student.next = &head //方式一
head = student //方式一,错误
}
trans(&head) //方式一
}()
//模块化遍历链表
func trans(p *Students) {
for p != nil {
fmt.Println(*p)
if p.next == nil {
break
}
p = p.next
time.Sleep(time.Second)
}
fmt.Println()
}
返回
链表头部遍历插入法:
{student9 37 21.855305 0xc00006c180}
{student9 37 21.855305 0xc00006c180}
{student9 37 21.855305 0xc00006c180}
{student9 37 21.855305 0xc00006c180}
{student9 37 21.855305 0xc00006c180}
{student9 37 21.855305 0xc00006c180}
^Csignal: interrupt
通过返回可以看出,链表只有一个节点,并且地址都是一样,why?明明有循环赋值呀。
这是因为:上面代码这里(head = student)是变量赋值操作,其实就是copy的过程,copy之后值都是一样的,如herd.next=>student.next=>student.next=>.....,这样循环下去对应的都是student自己,所以会造成死循环。
而且,当遍历这个链表时就会死循环最后一个。可见变量copy并不能改变指向,这样也就无法形成一个完整的链表结构。
所以,要用指针来改变指向进行头部插入。如下面的方式二、三
方式二、三:
//定义一个链表结构体
type Students struct {
Name string
Age int
Score float32
next *Students
}
func() {
fmt.Println("链表头部遍历插入法:", )
//定义一个链表
//创建一个头节点
var head *Students = &Students{} //方式二
//var head *Students = new(Students) //方式三
head.Name = "head"
head.Age = 18
head.Score = 100
for i := 0; i < 10; i++ {
student := Students{
Name: fmt.Sprintf("student%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
student.next = head //方式二、三
head = &student //方式二、三//使用指针的话,改变指向就ok。
}
trans(head) //方式二、三
}()
//模块化遍历链表
func trans(p *Students) {
for p != nil {
fmt.Println(*p)
if p.next == nil {
break
}
p = p.next
}
fmt.Println()
}
返回
链表头部遍历插入法:
{student9 37 21.855305 0xc00008c1e0}
{student8 11 29.310184 0xc00008c1b0}
{student7 28 46.888985 0xc00008c180}
{student6 62 38.06572 0xc00008c150}
{student5 94 81.36399 0xc00008c120}
{student4 56 30.091187 0xc00008c0f0}
{student3 25 15.651925 0xc00008c0c0}
{student2 81 68.682304 0xc00008c090}
{student1 47 43.77142 0xc00008c060}
{student0 81 94.05091 0xc00008c030}
{head 18 100 <nil>}
这样就可以进行头部遍历插入了。
删除指定节点:
//定义一个链表结构体
type Students struct {
Name string
Age int
Score float32
next *Students
}
func() {
fmt.Println("链表头部遍历插入法:", )
//定义一个链表
//创建一个头节点
var head *Students = &Students{} //方式二
head.Name = "head"
head.Age = 18
head.Score = 100
for i := 0; i < 10; i++ {
student := Students{
Name: fmt.Sprintf("student%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
student.next = head //方式二、三
head = &student //方式二、三//使用指针的话,改变指向就ok。
}
trans(head) //方式二、三
//----------------------删除指定节点----------------------
deleteNode(head)
trans(head)
}()
//模块化遍历链表
func trans(p *Students) {
for p != nil {
fmt.Println(*p)
if p.next == nil {
break
}
p = p.next
}
fmt.Println()
}
返回
链表头部遍历插入法:
{student9 37 21.855305 0xc000078330}
{student8 11 29.310184 0xc000078300}
{student7 28 46.888985 0xc0000782d0}
{student6 62 38.06572 0xc0000782a0}
{student5 94 81.36399 0xc000078270}
{student4 56 30.091187 0xc000078240}
{student3 25 15.651925 0xc000078210}
{student2 81 68.682304 0xc0000781e0}
{student1 47 43.77142 0xc0000781b0}
{student0 81 94.05091 0xc000078180}
{head 18 100 <nil>}
链表删除指定节点:
{student9 37 21.855305 0xc000078330}
{student8 11 29.310184 0xc000078300}
{student7 28 46.888985 0xc0000782a0}
{student5 94 81.36399 0xc000078270}
{student4 56 30.091187 0xc000078240}
{student3 25 15.651925 0xc000078210}
{student2 81 68.682304 0xc0000781e0}
{student1 47 43.77142 0xc0000781b0}
{student0 81 94.05091 0xc000078180}
{head 18 100 <nil>}
删除后插入节点:
//定义一个链表结构体
type Students struct {
Name string
Age int
Score float32
next *Students
}
func() {
fmt.Println("链表头部遍历插入法:", )
//定义一个链表
//创建一个头节点
var head *Students = &Students{} //方式二
head.Name = "head"
head.Age = 18
head.Score = 100
for i := 0; i < 10; i++ {
student := Students{
Name: fmt.Sprintf("student%d", i),
Age: rand.Intn(100),
Score: rand.Float32() * 100,
}
student.next = head //方式二、三
head = &student //方式二、三//使用指针的话,改变指向就ok。
}
trans(head) //方式二、三
//----------------------删除指定节点----------------------
deleteNode(head)
//----------------------再插入一个节点---------------------------
var newNode *Students = new(Students)
newNode.Name = "newNode"
newNode.Score = 1213
newNode.Age = 13
addNode(head, newNode)
trans(head)
}()
//模块化遍历链表
func trans(p *Students) {
for p != nil {
fmt.Println(*p)
if p.next == nil {
break
}
p = p.next
}
fmt.Println()
}
func deleteNode(p *Students) {
fmt.Println("链表删除指定节点:", )
var prev *Students = p //存放上一个链表节点
for p.next != nil {
if p.Name == "student6" { //开始删除
prev.next = p.next //修改上一个节点next
break
}
//没有找到
prev = p //上个节点代存点,重新赋值prev
p = p.next //指向下一个节点
}
//删除头节点会有问题
}
func addNode(p *Students, newNode *Students) {
for p.next != nil {
if p.Name == "student9" { //开始添加
newNode.next = p.next //新节点需要和后面的节点连接起来
p.next = newNode
break
}
p = p.next
}
}
返回
链表头部遍历插入法:
{student9 37 21.855305 0xc000076330}
{student8 11 29.310184 0xc000076300}
{student7 28 46.888985 0xc0000762d0}
{student6 62 38.06572 0xc0000762a0}
{student5 94 81.36399 0xc000076270}
{student4 56 30.091187 0xc000076240}
{student3 25 15.651925 0xc000076210}
{student2 81 68.682304 0xc0000761e0}
{student1 47 43.77142 0xc0000761b0}
{student0 81 94.05091 0xc000076180}
{head 18 100 <nil>}
链表删除指定节点:
链表添加指定节点:
{student9 37 21.855305 0xc0000765a0}
{newNode 13 1213 0xc000076330}
{student8 11 29.310184 0xc000076300}
{student7 28 46.888985 0xc0000762a0}
{student5 94 81.36399 0xc000076270}
{student4 56 30.091187 0xc000076240}
{student3 25 15.651925 0xc000076210}
{student2 81 68.682304 0xc0000761e0}
{student1 47 43.77142 0xc0000761b0}
{student0 81 94.05091 0xc000076180}
{head 18 100 <nil>}
二叉树
如果每个节点有两个指针分别用来指向左子树和右子树,就是二叉树
type name struct {
Name string
Age int
left *name
right *name
}
一个简单的栗子来实现二叉树:
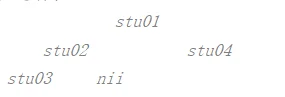
//定义二叉树结构体
type Tree struct {
Name string
Age int
Score float32
left *Tree
right *Tree
}
func test5() {
//定义根节点
var root *Tree = new(Tree)
root.Name = "stu01"
root.Age = 13
root.Score = 100
//root.left = nil
//root.right = nil
//定义左子树
var left1 *Tree = new(Tree)
left1.Name = "stu02"
left1.Age = 13
left1.Score = 100
root.left = left1
//定义右子树
var right1 *Tree = new(Tree)
right1.Name = "stu04"
right1.Age = 13
right1.Score = 100
root.right = right1
var left2 *Tree = new(Tree)
left2.Name = "stu03"
left2.Age = 13
left2.Score = 100
left1.left = left2
transTree(root)
}
//模块化递归遍历二叉树
func transTree(root *Tree) {
if root == nil {
return
}
//前序遍历:先遍历根节点,再遍历左右子树
fmt.Println(root)
transTree(root.left)
transTree(root.right)
//中序遍历:先遍历左子树,再遍历根节点、右子树
//transTree(root.left)
//fmt.Println(root)
//transTree(root.right)
//后序遍历:先遍历左子树,再遍历右子树,最后根节点
//transTree(root.left)
//transTree(root.right)
//fmt.Println(root)
}
返回
&{stu01 13 100 0xc0000741b0 0xc0000741e0}
&{stu02 13 100 0xc000074210 <nil>}
&{stu03 13 100 <nil> <nil>}
&{stu04 13 100 <nil> <nil>}
使用递归方式,可以很简便的遍历出二叉树结构。
根据返回,可以看出是根据一定的顺序来遍历的,这里就要说下三种不同的遍历方式:
前序遍历:先遍历根节点,再遍历左右子树
&{stu01 13 100 0xc0000601b0 0xc0000601e0}
&{stu02 13 100 0xc000060210 <nil>}
&{stu03 13 100 <nil> <nil>}
&{stu04 13 100 <nil> <nil>}
中序遍历:先遍历左子树,再遍历根节点、右子树
&{stu03 13 100 <nil> <nil>}
&{stu02 13 100 0xc000078210 <nil>}
&{stu01 13 100 0xc0000781b0 0xc0000781e0}
&{stu04 13 100 <nil> <nil>}
后序遍历:先遍历左子树,再遍历右子树,最后根节点
&{stu03 13 100 <nil> <nil>}
&{stu02 13 100 0xc000078210 <nil>}
&{stu04 13 100 <nil> <nil>}
&{stu01 13 100 0xc0000781b0 0xc0000781e0}
别名
在goang中是可以为类型定义别名的,使用的方式还是和别定义的一样。但是定义后的类型和原类型不同,只能使用原来类型强制转换进行赋值。
type integer int //定义别名
var a integer = 100
var b int = 19
b = int(a)
fmt.Println(b)
type alias struct { //定义一个结构体
Number int
}
type aliass alias //定义别名
var aa alias
aa = alias{29}
fmt.Println(aa)
var bb aliass
aa = alias(bb)
fmt.Println(aa)
返回
100
{29}
{0}
构造函数
在golang中的struct是没有构造函数的,一般可以使用工厂模式来解决这个问题。
为类型定义别名, 注意: 定义后的类型和原来的类型不同, 只能使用原来类型强制转换进行赋值
以上就是golang中的结构体,struct是一个很复杂的数据结构,甚至里边包含指针的指针的变量,理解起来确实蛮抽象的。
目前个人理解整理就是这么多,有问题的地方还望指出