
延时应用场景
之前的文章分享了分布式任务调度系统负载均衡方案:分布式任务调度系统分发及负载均衡实现方案。
一个完整的任务调度系统,对延时任务的支持必不可少。延时任务、延迟消息、延迟队列基本语境和实现类似,那么它有哪些适用场景呢?最常见的如:用户下单xx分钟内未付款订单自动取消,释放库存;订单发货后xx天自动确认收货;订单结束后xx天自动评价;用户注册后1min内触发xx动作等。
延时解决方案
延时作为常见的需求自然有众多解决方案,数据库轮询是最容易想到的一个方案,时间轮,小顶堆,有序链表,延时队列以及各类开源项目也是琳琅满目。了解每种解决方案的原理以及优缺点,可以帮助在生产中做好技术选型。
1.数据库轮询
最简单且容易想到的方案是后台启动定时脚本,定时轮询扫描数据库获取满足条件数据并处理,这种方案实现简单有效。
时间处理精度问题,linux系统crontab最小是1分钟,如果需要更细时间粒度可以通过脚本for{}无限循环轮询数据库,总执行时间为50秒,每次轮询后sleep10秒,类似操作可达成更小时间粒度。
此方案项目初级比较有效,但也有较多弊端:
轮询粒度不好把控,轮询间隔时间过长影响精准度,过短又会产生大量不必要的数据库扫描,增加数据库压力;
随着数据量增大此方案存在较大性能瓶颈;
延时任务过多也会造成定时脚本不易维护。
RabbitMQ本身不支持延时消息,但可通过死信队列及死信路由设置间接达成。
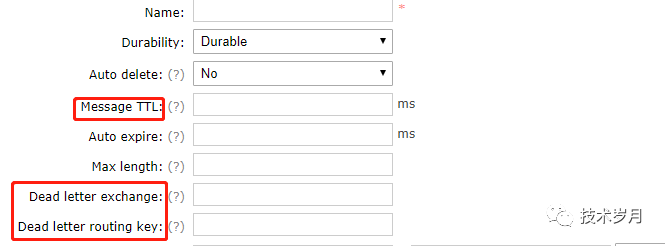
TTL(Time to live)分消息TTL和队列TTL,控制消息超时时间,消息在队列中生存时间一旦超过TTL设置时间即成为dead letter(死信),然后通过Dead letter exchange死信路由交换机来重新路由消息。
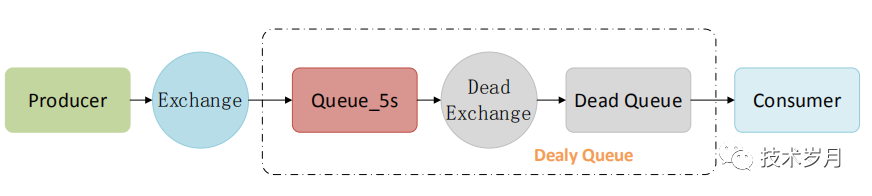
利用成熟RabbitMQ消息组件,稳定、易扩展、支持分布式,消息支持持久化可靠性好。但消息的延时时间需要保持一致,死信队列还是先进先出,如果先进的队列由于未到执行时间会阻塞所有后入消息,因此一种延时时间需要建一套路由。
除死信队列方案外还有一些RabbitMQ的插件可以实现延时,具体可下载插件:
rabbitmq_delayed_message_exchange
RocketMQ是支持延时消息的,且足够高效可靠,但延迟消息的时间不是任意时间,而是仅支持18个固定的时间段,这里不再赘述。
3.时间轮算法
时间轮算法是实现延时最常用的算法,这里重点介绍它的实现方案。
可以想象一个时钟的表盘,有一个指针绕着转动,每走一个格子称为一个刻度(时间间隔interval),表盘每个格子上挂载待执行任务列表(任务桶buckets),指针转动一圈总长度(bucketSize),这些元素构成一个时间轮。
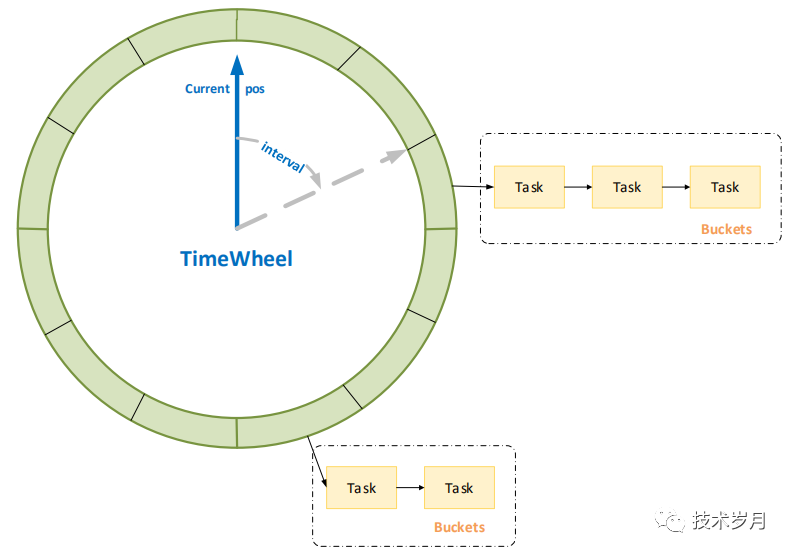
如果刻度是1s,总长度是60s,那么转一圈就是1分钟,可以实现1分钟内的延时。要实现更长时间跨度,可将总长度设置更大,但这会造成占用内存过大,更多空转浪费资源。有两种优化方案,使用多层时间轮或多级时间轮。
多层时间轮就是增加圈数circle,一圈代表60s,那么10圈就是10分钟。
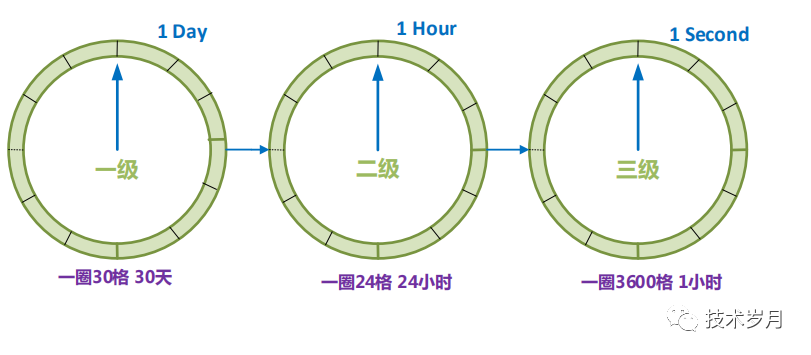
多级时间轮可以想象成时钟的时针、分针、秒针,一级到达后执行二级,再到三级,直到满足执行任务。
3.2具体代码
定义时间轮结构如下:
type TimeWheel struct {ticker *time.Ticker //tickerinterval time.Duration //time duration of moving one slot.buckets []*list.List //bucket listbucketSize int //total size of bucketcurrentPos int //current position in bucketscallbackFunc func(interface{}) //execute funcstopChannel chan bool //stop the ticker channel}
定时器触发使用time.Ticker,它是Go自身实现的内置定时器,基于最小堆结构实现。Buckets存放任务列表,使用双向链表container/list结构,注意它非线程安全。
新建一个时间轮实例:
//create timewheel instancefunc New(interval time.Duration, bucketSize int, callbackFunc func(interface{})) (*TimeWheel, error) {if interval <= 0 || bucketSize <= 0 || callbackFunc == nil {return nil, errors.New("create timewheel instance fail")}tw := &TimeWheel{interval: interval,buckets: make([]*list.List, bucketSize),bucketSize: bucketSize,currentPos: 0,callbackFunc: callbackFunc,stopChannel: make(chan bool),}//init bucket,every bucket will have a listfor i := 0; i < bucketSize; i++ {tw.buckets[i] = list.New()}return tw, nil}
定义任务Task结构体,并添加任务。为了构造多层时间轮,给任务添加circle代表该任务在第几圈。pos代表任务在当前表盘上的位置。
//define tasktype Task struct {Id interface{} //task id global uniquenessData interface{} //data of taskDelay time.Duration //delay time, 30 means after 30 secondCircle int //task position in timewheel}//add taskfunc (tw *TimeWheel) AddTask(task *Task) {delaySeconds := int(task.Delay.Seconds())intervalSeconds := int(tw.interval.Seconds())circle := int(delaySeconds / intervalSeconds / tw.bucketSize)pos := int(tw.currentPos+delaySeconds/intervalSeconds) % tw.bucketSizetask.Circle = circletw.buckets[pos].PushBack(task)}
启动时间轮,每经过一刻度(这个刻度可以是1s、5s任意),做一次检查,如果当前格里有任务则取出执行,碰到多圈任务将circle-1。当指针走到末尾代表走完一圈,会重置再从头执行。
//start timewheelfunc (tw *TimeWheel) Start() {//add tickertw.ticker = time.NewTicker(tw.interval)//receive chango func() {for {select {case <-tw.ticker.C: //reach a ticklog.Println("1 tick")tw.tickHandler()case <-tw.stopChannel: //truetw.ticker.Stop() //stop the tickerreturn}}}()}//1 tick handlerfunc (tw *TimeWheel) tickHandler() {bucket := tw.buckets[tw.currentPos]for e := bucket.Front(); e != nil; {task := e.Value.(*Task) //e.value is a taskif task.Circle > 0 {task.Circle--e = e.Next()continue}//do taskgo tw.callbackFunc(task.Data)//remove enext := e.Next()bucket.Remove(e)e = next}//finish 1 circle,resetif tw.currentPos == tw.bucketSize-1 {log.Println("new circle")tw.currentPos = 0} else {tw.currentPos++}}
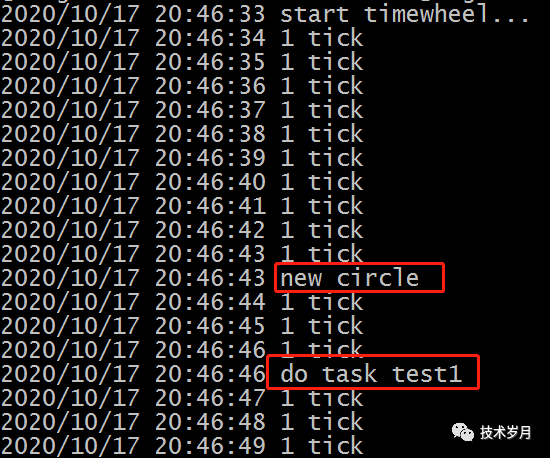
测试时间轮一圈10s,间隔刻度1s,添加延时12s的延时任务,第13s后执行任务。
func TestTimeWheel(t *testing.T) {tw, err := New(1*time.Second, 10, func(data interface{}) {log.Println("do task", data)})if err != nil {t.Error(err)}log.Println("start timewheel...")tw.Start()task := Task{Id: 1, Data: "test1", Delay: 12 * time.Second}tw.AddTask(&task)time.Sleep(20 * time.Second)}
执行效果:
由于时间跨度越大轮子越大,会占用更多内存,所以可以考虑采用磁盘文件+内存时间轮相结合的方案。内存时间轮只加载1小时的任务,磁盘文件可以时间命名(2020101721代表2020年10月17日21:00-21:59:59所有延时任务),每小时一个文件,一天24个,一般情况不会保存太多文件。
3.3.2 内存时间轮的高可用性
因为采用内存时间轮,如果程序崩溃会导致数据丢失。将时间轮持久化保存成文件存储,到达时间后预加载到内存,程序崩溃、重启后也可以重新加载,文件保存可保障数据不会丢失,当然也可保存在redis或其他持久化存储中。
除内存时间轮外也可以直接使用redis的list结构替代container/list,redis的string结构保存时间轮当前指针。
2020101721_02020101721_12020101721_2...2020101721_9
时间轮方案执行效率高,时间精度高,但内存时间轮重启或宕机后需要考虑持久化和消费标记,集群扩展实现也较复杂。
要使用排序链表数据结构,最先想到的就是redis的sorted set结构,这里以redis有序集合为基础来实现延时。
redis有序集合zset结构是一个有序链表,可以通过zadd向链表添加元素,并将其score设置为延时任务执行的时间戳,值设为任务id。然后通过zrange获取链表第一个元素(默认是score最小元素),通过判断score和当前时间大小,决定是否到达执行时间。
按时间轮设计思想定义一个带定时器的结构体:
//define bucket tickertype BucketTicker struct {Ticker *time.TickerInterval time.DurationName stringCallbackFunc func(interface{}) bool}//new tickerfunc New(interval time.Duration, bucketName string, callbackFunc func(interface{}) bool) (*BucketTicker, error) {if interval <= 0 || callbackFunc == nil {return nil, errors.New("create bucket ticker instance fail")}bucket := &BucketTicker{Interval: interval,Name: bucketName,CallbackFunc: callbackFunc,}return bucket, nil}
定义任务及添加方法,将任务的执行时间(当前时间+延时时间)和任务唯一Id存到zset结构中,将任务主体序列化存到kv结构(string)中。
//define tasktype Task struct {Id string //task id global uniquenessData interface{} //data of taskDelay time.Duration //delay time, 30 means after 30 secondTimestamp int}//add taskfunc (bucket *BucketTicker) AddTask(task *Task) error {//task id and delay time in redis zsettimestamp := time.Now().Add(task.Delay).Unix()err := redisclient.ZAdd(bucket.Name, int(timestamp), task.Id)if err != nil {return err}//task body in redis stringdata, err := json.Marshal(task)if err != nil {return err}err = redisclient.Set(task.Id, string(data))if err != nil {return err}return nil}
启动定时器,每隔一个刻度,检查是否有满足执行时间的任务。间隔时间越长,可以减少与redis查询频率,但延时任务处理精度会降低。
func (bucket *BucketTicker) Start() {timer := time.NewTicker(bucket.Interval) //intervalgo func() {for {select {case t := <-timer.C:log.Println("1 tick")bucket.tickHandler(t, bucket.Name)}}}()}//tick handlerfunc (bucket *BucketTicker) tickHandler(currentTime time.Time, bucketName string) {for {task, err := getTask(bucketName)if err != nil {log.Println("error happen!", err)return}if task == nil { //no taskreturn}//not arrival execution timeif task.Timestamp > int(currentTime.Unix()) {return}//do tasktaskDetail, err := getTaskDetail(task.Id)if err != nil { //retrylog.Println("error happen!", err)continue}//if callback success, remove finish taskif ok := bucket.CallbackFunc(taskDetail.Data); ok {err = removeTask(bucketName, task.Id)if err != nil {continue}} else {log.Println("error happen!", errors.New("callback error"))continue //retry}return}}
getTask(),getTaskDetail()和removeTask()分别执行Redis操作。
//get task from redis zsetfunc getTask(bucketName string) (*Task, error) {value, err := redisclient.ZRangeFirst(bucketName) //ZRANGE key 0 0 WITHSCORESif err != nil {return nil, err}if value == nil {return nil, nil}timestamp := int(value[0].(float64))taskId := value[1].(string)task := Task{Id: taskId,Timestamp: timestamp,}return &task, nil}//get task detail by taskIdfunc getTaskDetail(taskId string) (*Task, error) {v, err := redisclient.Get(taskId)if err != nil {return nil, err}if v == "" {return nil, nil}task := Task{}err = json.Unmarshal([]byte(v), &task)if err != nil {return nil, err}return &task, nil}//remove the taskfunc removeTask(bucketName string, taskId string) error {err := redisclient.ZRem(bucketName, taskId)if err != nil {return err}err = redisclient.Del(taskId)if err != nil {return err}return nil}
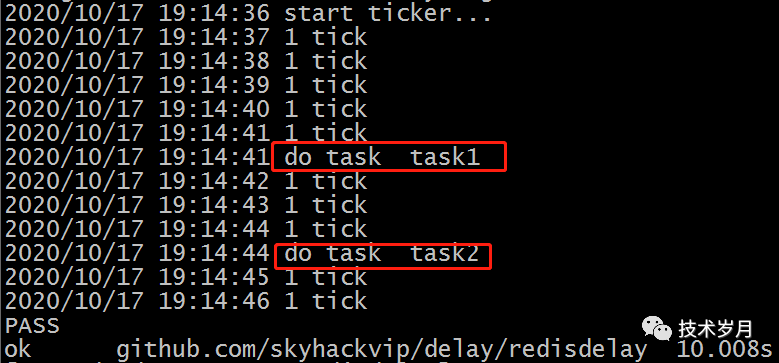
编写测试用例测试,添加2个延时任务分别是延时5秒和延时8秒。
func TestRedisDelay(t *testing.T) {delay, err := New(1*time.Second, "test", func(data interface{}) bool {log.Println("do task ", data)return true})if err != nil {t.Error(err)}log.Println("start ticker...")delay.Start()task1 := Task{Id: "1", Data: "task1", Delay: 5 * time.Second}task2 := Task{Id: "2", Data: "task2", Delay: 8 * time.Second}delay.AddTask(&task1)delay.AddTask(&task2)time.Sleep(10 * time.Second)}
执行效果如下:
当有更多延时任务时,考虑存储多个bucket,每个bucket有自己的定时器,执行自己的任务列表。当有任务添加时,轮询加入不同bucket中。
由于依赖比较成熟的组件redis,高可用程序挂掉重启后仍可继续处理,集群分片拓展也容易。但由于每次都取出数据比对score,会有频繁Redis IO操作,造成较大的资源浪费。
延时方案方案除上述几种外还有最小堆的形式,文中提到的Go内置定时器即采用四叉堆结构,其实现原理与排序链表大同小异。
文章相关代码请关注公众号 “技术岁月”,发送关键字“延时任务”获取。
