
传统并发的方式,其实是多线程。但是多线程除了每个线程的占用较大栈空间外(至少 2M),最大的问题就是线程的调度是由内核控制。
即线程上下文切换(同一个进程中)会从 用户态 -> 内核态 -> 用户态,很多上线文信息都是保存在内存中的,一次切换就是一次 I/O (内存的读写),这明显这是一个耗性能杀手的操作。
Golang 中有一个协程的概念,其实简单理解就是更轻量级的调度单元。它有两个最大的特点:
- 占用栈空间小(2KB ~ 2GB)
- 上下文都在用户态切换,不会涉及到内核态
虽然上下文切换也会涉及到内存 I/O 操作,但包含的信息极少,从下文 G 的结构体中 gobuf类型字段可以看出,就 7 个字段的信息。
这里列出一些测试过的量化指标:
协程切换的速度大约为 1~2微秒,而golang中协程的切换速度为 0.2微秒左右。
(下文说明:本文使用的版本:go version 1.17.9; 下文会交替出现: 协程、g 、goroutine,都是同一个意思(主要是博主懒,不想改了-_-)
接下来就进入正文。
(文章内容较多,建议大家配合目录看,更容易框架性/体系性 地去理解)
GMP
他们的关系图很容易在网上搜索到,这里就不放了。先介绍一下它们的结构体
M
M即操作系统的线程,一个M代表一个线程。
(一核cpu(P) 绑定一个 golang 线程,再利用协程自身的调度,就可发挥出很好的并发效果)
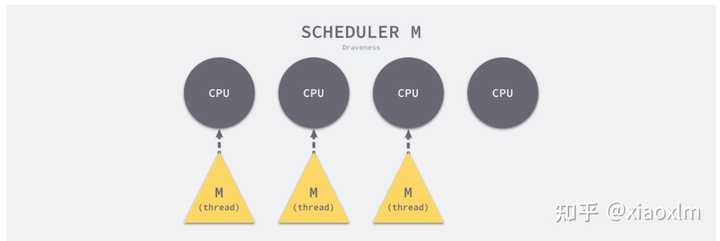
m 只关心 curg 和 g0 两个 Goroutine。
curg 是在当前线程上运行的用户 Goroutine。
g0 是一个比较特殊的 Goroutine(简单理解成处于用户态 golang 的系统协程),它深度参与运行时的调度过程。每当用户协程需要重新调度的时候(退出或被抢占),m 上的 运行的 curg 就会切换成 g0,完成调度后,再切换成 curg。
P
GOMAXPROCS同时又可以把 p 理解为 执行 goroutine 的执行环境(context)。
我们看看 p 结构体中,与调度相关的字段:
runqrunqrunqheadrunqtailrunqheadrunqtailrunnextstatus_Pidleidle p list_Prunning_Psyscall_Pgcstop_Pdead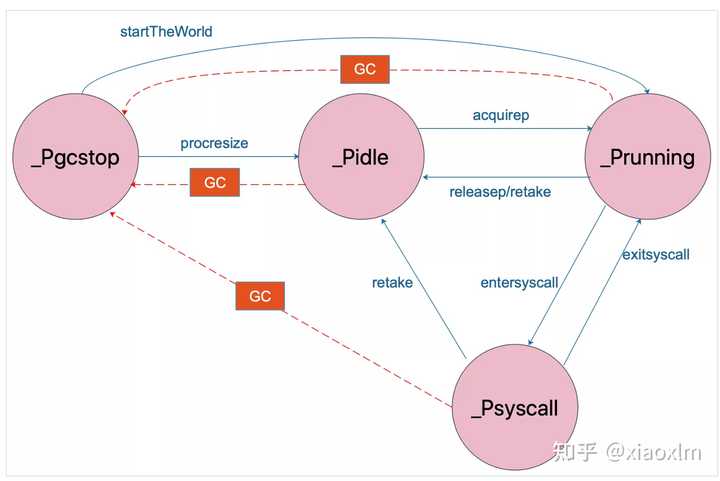
gFreeruntime.malgG
即 gorouting。它的结构体中有将近100个字段,这里不会全部介绍完,只介绍其中比较重要的几个字段:
stackstackguard0preemptpreemptStop我们再来看看 sched 的类型 gobuf,当调度器保存或者恢复上下文的时候,会用到其中的信息:
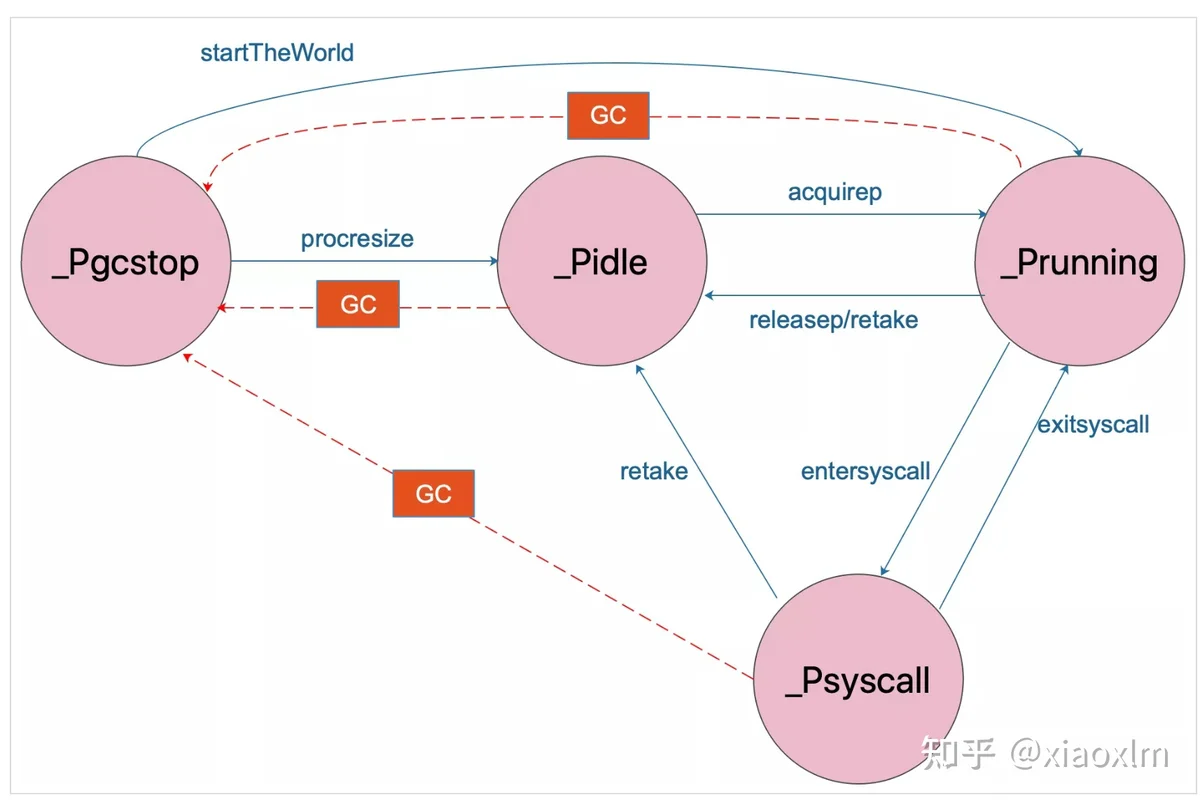
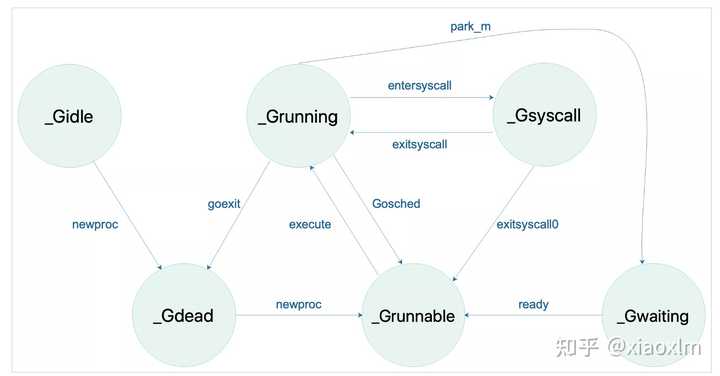
atomicstatus 表示 goroutine所处状态,状态解释如下:
_Gidle_Grunnable_Grunning可以执行代码,拥有栈的所有权。被赋予了内核线程 M 和处理器 P,不在运行队列中
_Gsyscall_Gwaiting_Gmoribund_unused_Gdead表示 goroutine 并没有被使用到。
可能刚刚退出,或在一个freelist,也或者刚刚被初始化;
可能有栈也可能没有
_Genqueue_unused_Gcopystack发现需要扩容或者缩小栈空间,将协程的栈转移到新栈时的状态。
没有执行用户代码,不在运行队列上。
_Gpreempted_Gscanxxx这里看起来比较头疼不要紧,在最后我会附上一张状态扭转图。
schedt
runqgFree调度
这是本章的重点,分为 调度策略 和 调度时机 。
go而创建goroutine的底层方法是:
它干的事儿就是创建一个 goroutine,然后放入到 p 的本地协程队列中。
newproc1()malg()然后就是调度执行了。
调度策略
即从哪里获取 协程?下面是调度策略函数:
主要的调度逻辑就是这三段。
runqput所以一开始的入口是第二段, 直接从本地协程队列获取协程。
findrunnableP 本地协程队列
findrunnablerunqget它的处理逻辑也很简单,流程是:
next==0head == tail全局协程队列
globrunqget方法len(_p_.runq) / 2runqput获取准备就绪的网络协程
然后就是 获取准备就绪的网络协程:
injectglist函数globrunqputbatch方法窃取其他P中的G
最后从其他 P中窃取G
stealWorkallp []*pallprunqsteal() 调用 runqgrab()执行
schedule() 方法execute()方法将 g 状态改为 _Grunnable -> _Grunning
gogogogogoexit0() 方法其中主要的逻辑就是:
gfput我们可以认为调度循环永远都不会返回。
gogogoexit0()gfputsched.gFree调度时机
schedule(借用 goland 的调用调转,很容易找到)
整理如下:
mstart1()Goexit()goexit1()goexit0()Gosched()`gosched_m()goschedImpl()gopark()park_m()exitsyscall()exitsyscall0()preemptPark()startTheWorld()semrelease1()goyield()goyield_m()协程退出 在上一节 执行 中已经说了,这里就不重复。
线程启动 主要是初始化 P,比较简单,这里就不叙述了,感兴趣的朋友可以自己了解一下。
剩下的,我们再一个一个来看。
抢占 P 咱们单独拿一节来说。
主动让出
runtime.Gosched()然后我们再看看源码逻辑:
逻辑也比较简单:
_Grunning_Grunnabledropg被动等待
这是最常见的,比如 网络I/O、chan 阻塞、定时器 等都会进入这里面。
源码也比较简单:
总的逻辑也比较简单:
_Grunning_Gwaitingdropg但中间有个插曲 :
gopark()!oknetpollblockcommit如果这个 网络事件解锁成功(goroutine准备好了),就恢复这个 goroutine,进入 执行。
等待被唤醒
goready()ready()- 修改 g 的状态 _Gwaiting -> _Grunnable
- 放入本地队列
退出系统调用
reentersyscall()- 保存当前 PC 和栈指针 SP 中的内容
- 修改 g 的状态 _Grunning -> _Gsyscall;修改 p 的状态为 _Psyscall
- 并解除 p 与 m 之间的绑定
- 将 P 放入 oldp 中
然后就是进入系统调用。
当系统调用结束后,会调用退出系统调用的函数,将 g 重新执行:
这里有一个快速路径和一个慢的路径。
exitsyscallfast()exitsyscall0()执行从注释就能看出来:
如果获取到空闲 p,就直接绑定 p 和 m, 然后执行当前。
_GrunnablestartTheWorld
goyield_m逻辑也非常简单:
_Grunning_Grunnable抢占P
就像我们在 linux 上跑的守护进程,或者 k8s 的 DaemonSet 资源一样。这个系统协程就是一个跑在后台的协程。
在程序启动的时候,会创建一个新的线程 m,同时创建一个 协程 g,这个 g 不需要 p,直接绑定与 m 绑定。
sysmonretake()_Prunning_Psyscall- 如果 p 距离上次调度已经过去 10us (pd.schedwhen+forcePreemptNS <= now)
- 如果系统调用超过了一个 sysmon tick (20us)
- 系统调用情况下,p 中的本地 goroutine 队列中有等待运行的G(runqempty(p))。 这时候抢占只是为了让本地队列中的 goroutine有执行的机会。
- 没有空闲 p 和 自旋的 m ( atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 )。有的话,说们很闲,抢占了也没有意义
- 当系统调用时间超过了 10us (pd.syscallwhen+1010001000)
情况1
preemptone()gp.stackguard0 = stackPreempt检查栈溢出morestack_noctxt()newstack()gopreempt_m()goschedImpl()goschedImpl其他情况
_Pidlehandoffp()startm()- p 中本地协程队列不为空
- 处理gc
- 没有 自选/空闲 m
- 全局协程队列不为空
- 如果这是最后一个运行的 p,同时需要处理网络 socket 事件
pidleput()releasem(mp)_g_.stackguard0 = stackPreemptpreemptone()最终 被抢占的 p 当前执行的 g,都会被放入到全局队列中
信号抢占
在go1.14版本之前没有抢占机制,这就会出现一个问题,如下:
一个这样的协程会永远占着 cpu,1.14版本之后,加入了信号强制抢占 p 的机制。类似于 Linux 里面的 sighandler 注册信号的方式:
doSigPreempt(gp, c)asyncPreempt()asyncPreempt2()preemptParkgopreempt_m总结
一开始我们介绍了 GMP 结构体中重要字段的意思。
然后就是重点 调度 ,调度可以看作是一个死循环,分为 调度策略 和 调度时机
调度策略逻辑如下:
- 先从 p 的 本地协程队列 获取 g,如果没有,就从全局协程队列里,获取第一个,然后拿一部分协程(最多拿走 256/2 个) 到本地中;
2. 如果 全局队列 中没有, 就获取将网络协程中的第一个,然后将剩下的所有网络协程都加入到全局协程队列中。
3. 如果还是没有,就从其他 p 的本地协程队列中 窃取一半 到自己本地队列中。
然后就是调度时机,常见的就是:
- 主动让出:
runtime.Gosched()_Grunnable_Grunning2. 被动等待:
_Grunning_Gwaiting_Gwaiting_Grunnable3.退出系统调用
退出后就要要么马上执行当前 goroutine(快路径);
要么就是慢路径: 将协程状态从 _Gwaiting 变成 _Grunnable,然后放入当前 p 的全局协程队列。。
4. gc 的 stop the world 后的 start the world:
_Grunning_Grunnable最后就是,就是监控线程的抢占 p ,它的目的主要是为了更公平是实现调度,防止其他 协程出现饥饿的情况。主要是出现下面两种情况会发生抢占:
- 超过了系统 tick(即20微秒)
- 当前执行超过了 10 微秒(系统执行或者用户协程执行)
然后将当前的 g 放入全局队列
g 的状态转换图可以参考下面这张图:
下班后加班加点耗时半个月,终于把复杂的 GMP 调度写完了。
喜欢的小伙伴不要只收藏不点赞啊 T_T。