
最近发现线上服务偶尔有重启现象,于是开启了一段持久的排查过程
首先,排查程序中可能的panic,先是拉了一波日志,把有panic的地方全部处理了
这些panic,主要集中在空指针,
其次,针对起协程的地方检查有没做recover捕获
发现有部分起协程没有做recover捕获
解决完这些,感觉基本就解决了,然后上线后发现仍有部分机器会重启,
重启的现象是:
进程消失,用ps指令查看,进程没了,
然后,容器就自动重启prod,拉起程序
至此,就开始进入比较难排查的过程。
因为进程丢失后,prod重启,nohup中所有的日志就都丢了
log日志只记录了最后一次日志的打印,没有任何错误信息
怎么办呢,一脸懵逼!!!
然后根据最后的日志信息,开始看代码,然并卵,没有什么发现
于是重新梳理可能导致程序panic的地方
- 程序内部有空指针的使用会导致panic
- 程序中有使用panic()函数的
- 数组越界
- map写并发
上述地方,如果不做defer recover处理会导致程序异常终止
但是,现在程序中已经加了defer recover处理,没道理再出现panic,而不会捕获到
查资料时发现这么一个修改
map的并发写操作,会触发 fatal error
而fatal error 不会被recover捕获到
于是开始排查map的使用,发现一个问题,有个map使用时,没有加锁,代码类似如下:
上面的代码在写map的时候加锁了,但是读map的时候没有加锁,导致map的度写并发错误。
可以看看下面这个例子:
运行上面这个代码,会发现出现如下错误:
而这个 fatal error 就是上面提到的不会被recover的错误,会直接导致进程down掉
下面来看下,fatal错误的处理
可以看到,fatal错误直接执行 exit(2)
程序就直接结束了。
到这里基本就该解决了,然而,还有一个坑
依然是并发的坑
代码里还有个并发调用,会修改参数,这个是比较隐藏的,因为是使用的第三方的库,原本没有注意到第三方库中,会有修改,伪代码是这样的
这里只是示意,实际执行这个并不会有问题。
handle中有修改判断,如果为nil,会panic。
所以这里建议这么写,把数据作为入参传进去
到了这里,就所有的会导致panic的问题都解完了。
然后补充一下,如何抓取coredump
对于无法捕获的panic,是无法靠recover输出堆栈信息的。
那有什么办法能输出吗?
有的
首先在启动脚本的最前面加上如下配置
ulimit命令用于控制shell程序的资源
-c <core文件上限> 设定core文件的最大值,单位为区块
unlimited标识不做限制
GOTRACEBACK来控制Golang panic stack trace输出的信息
加上这两句,当程序异常终止时,就是打印堆栈信息
然后将 /data/coredump中的信息cp到指定的文件夹下
这样就可以把coredump信息输出到/home/data/coredump/,当然,你可以根据自己的需求修改路径。
生成coredump文件后,使用golang的 dlv 来调试core文件
安装dlv的方法如下
然后调试coredump文件
执行指令
--check-go-version=false 是忽略go 版本和 dlv版本的区别
不然会报错
然后执行goroutines 指令,查看执行的协程
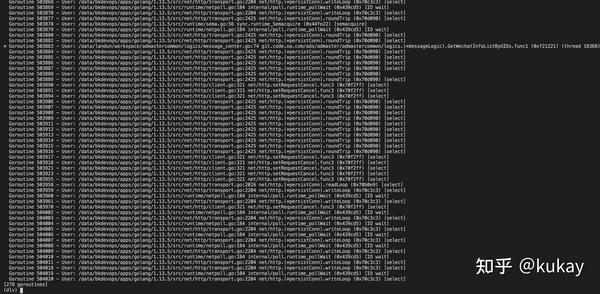
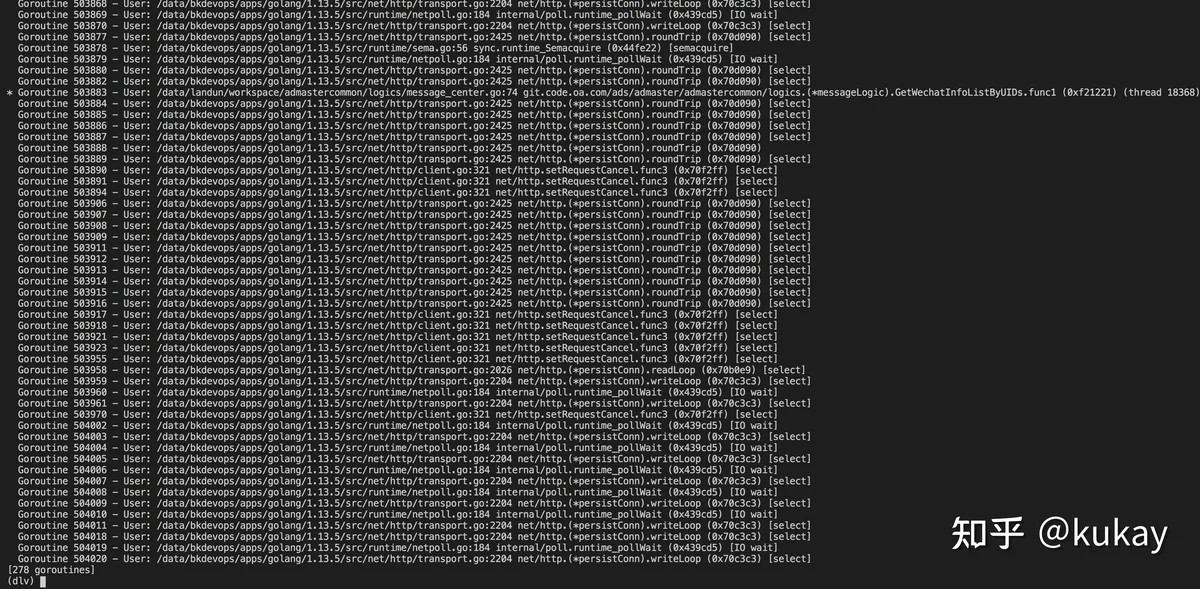
此时看到Goroutine 503883前面有一个*号引起了注意,使用命令goroutine 503883 对当前的goroutine进行切换。然后bt查看堆栈信息。
指令如下:
分析堆栈的错误,然后解决问题。
好了,就这些吧,耗时3天终于解决问题了