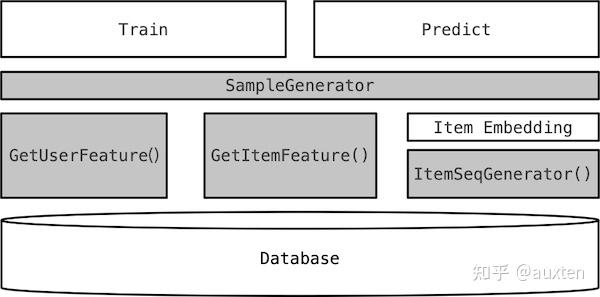
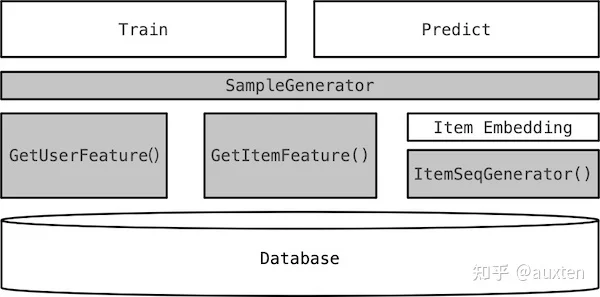
一个大规模的推荐系统维护需要耗费难以想象的人力,我试着从推荐系统最初的样子说起。
2009 年在豆瓣实习第一次听教授和胖子在聊协同过滤,我还以为是一种比 Bloom Filter 还要牛逼的东西。
2016 年加入第四范式,我才有了机会去参与几个推荐系统的设计。每当我们用奇技淫巧的特征工程把训练 AUC 做到接近 0.8,就有种「雄关漫道真如铁,而今迈步从头越」的感觉。
ai4every1
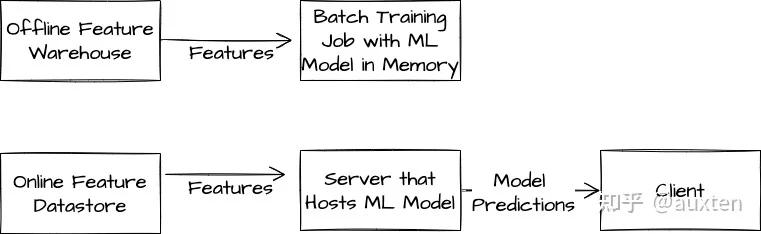
咱就说,也曾幻想,要当年如果 Hinton 会的不是 Python,而是 C++……算了,有点离谱,那可能他还在研究牛逼闪闪的 C++11、17、20……如果当年 Hinton 会 Golang,那是不是咱当年就不用苦逼兮兮看着 Python 翻译成 Java 了。
打住,假设我们有了一种语言像 Python 一样省键盘,像 C++ 一样拳拳到肉。模型训练和上线是不是就变成了:
分分钟训练完成,单机 10w QPS,哇嘎嘎。看来看去,目前也就 Golang 比较接近理想


也不太对,数据哪来呢,哪会有现成的宽表躺在那里等你 Train 一发
对,Spark 这玩意儿真是秒啊,但要是线上召回也用 Spark 跑个 Job?那 QPS,不,应该是 SPQ(Second Per Query?) 还不上千。
打住,假设我们有了一种语言既能描述大宽表的形成逻辑,又能描述 Predict 的特征宽表。不用假设,这就是 SQL 啊!
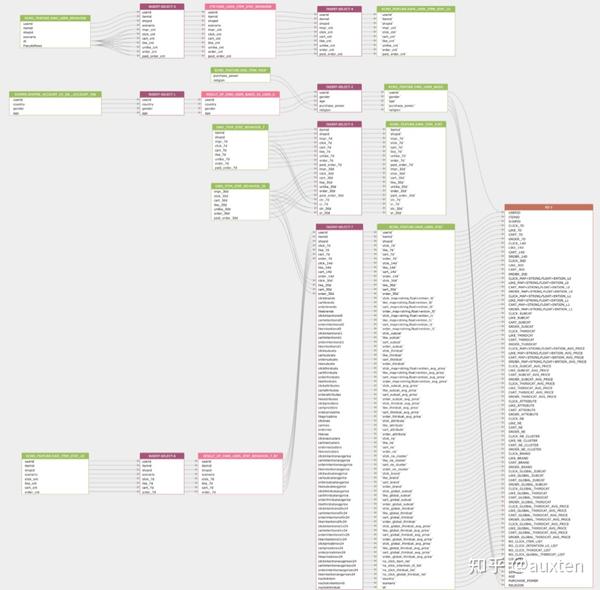
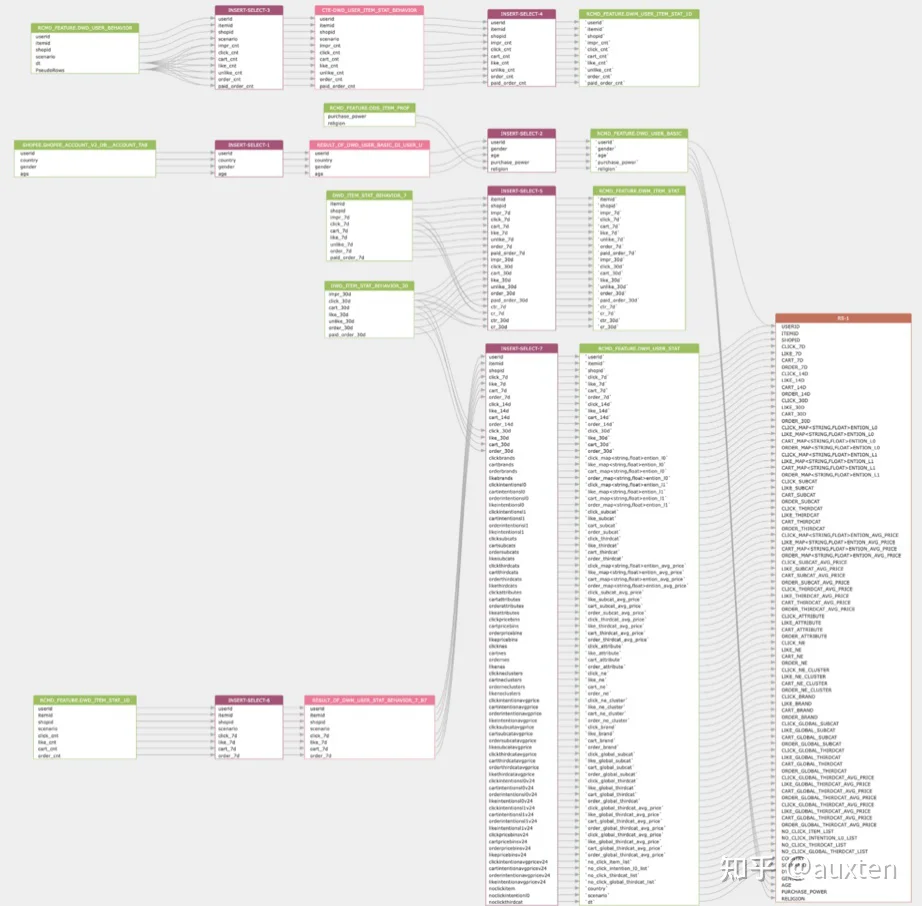
回头看,为啥这么多年了推荐系统还只是几个豪门大厂才能玩的呢,主要还是这玩意儿是 IT 界少有的学习曲线异常陡峭,对后端技能要求又很高的领域。这么一来不可避免的就要分工很细,只有非常少数的人能从原理、算法和工程上完整见识过工业界推荐系统的全貌。而这少部分人要么是英年财务自由,要么是在为 AUC 提升 0.001 而点灯熬油。
AUC: 你基本可以理解为是推荐系统的一个核心效果指标。
一般情况下:
AUC 0.3 你把 label 整反了
AUC 0.5 代表全选“钝角”
AUC 0.7 就是一个用户明显感觉到“懂我”的指标
AUC 0.8 就是一个互联网大厂及格线的水平
AUC 1.0 代表你是上帝
其实说白了推荐系统这 10 多年主要就发生了这么几个重大的进步:
- 2009~2015 LR + 精妙的特征工程打败了 SVM、协同过滤这些上一代的算法
- 2012~2015 NN 改变了 CV、NLP 行业之后又杀回了推荐系统,把特征组合这个传统艺能的重要性大大降低了
- 2013 被 Google 从故纸堆里拿出来,而后被发扬光大产生了 Item2vec 等,激发了大家对 User Behavior 的挖掘热潮
- 2015~2016 激发了NN+各种老模型的“嫁接”
- 2016~2017 中间经历了 、 等一众树模型多快好省的强烈反扑
- 2017 Transformer 大行其道,以至于
- 2018~now 主要就是对特征,尤其是用户特征的深挖,代表就是大名鼎鼎的
一来呢,既然算法都成“科学家”了,都用 Python 做出了牛逼闪闪的新模型了,那自然是不屑于关心什么狗屁 Numa、异步非阻塞、shared_ptr,剩下的事情你们这些工程师还搞不定嘛??
不是俺们无能,是这玩意儿真是术业有专攻,不搞个三五年咋能出师,没个五年八载咋能发 Paper。
坦白来说,对于大多数系统,无论是从积累的数据量还是从必要性上看,对推荐系统的需求肯定不是 AUC 从 0.75 → 0.76。而是,我有一些后端 CRUD 逻辑、一个 MySQL 数据库、一个 SPA 前端,那能不能在某些关键的影响用户体验,或影响收入的列表上给用户一个千人千面的推荐?
那么需求应该是:
- 能基于常见的数据库 MySQL、PG、SQLite 作为训练样本的数据源
- 容易 PoC(Proof of Concept),容易对接、部署、请求一下看看效果
- 在老子尝到甜头之前,别想骗老子去学习线性代数买 GPU
于是乎,在经历了这么多之后,我用纯 Golang 写了一个集训练、预估于一体的服务端框架。你只需要用 SQL + Golang 完成几个数据接口的实现,就可以跑起来一个小型推荐系统: